

EPOPTIS: A Monitoring-as-a-Service Platform for Internet-of-Things Applications
 , and
, and
Abstract
:1. Introduction
2. Related Works
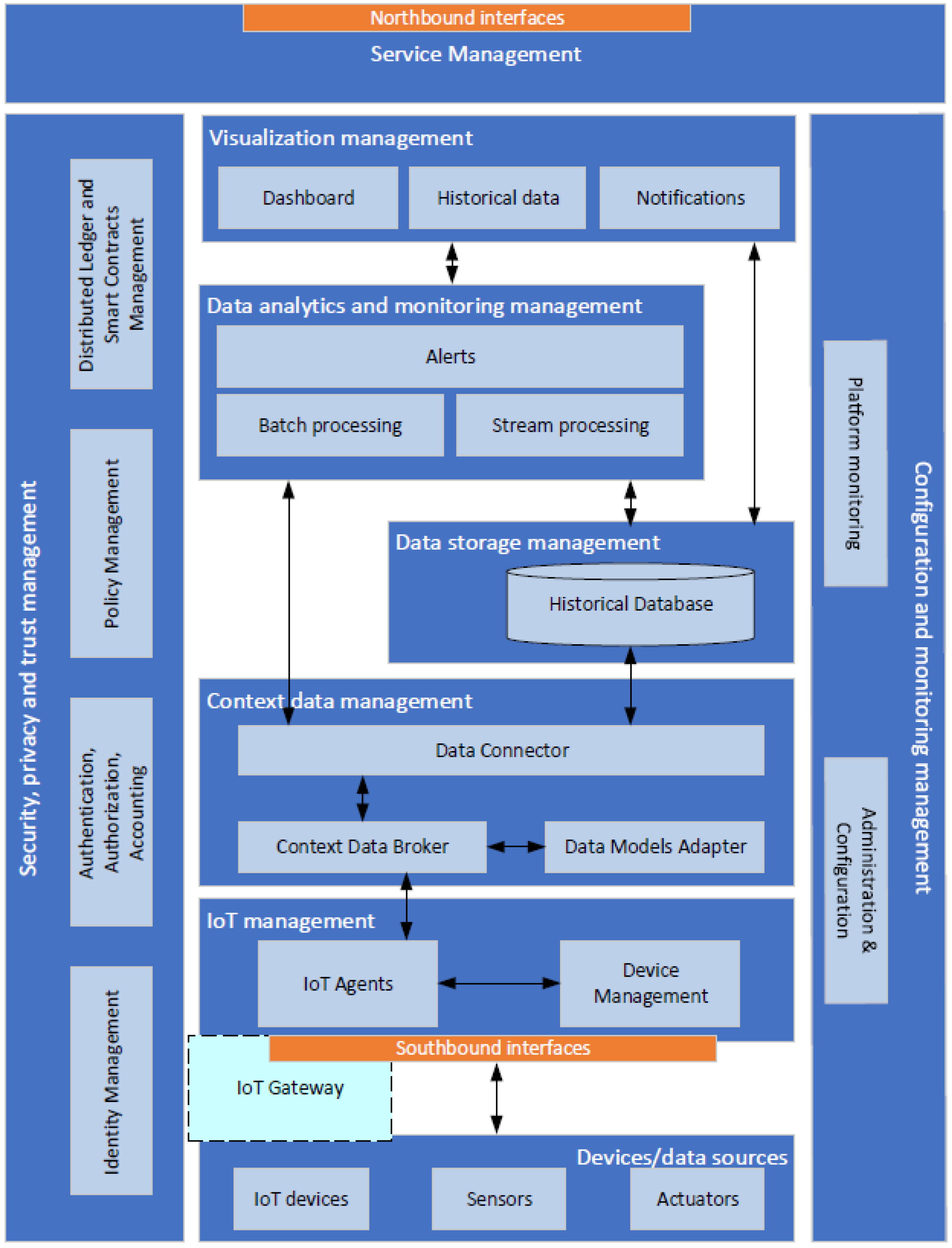
3. System Requirements and Logical Architecture
3.1. System Requirements
3.1.1. Functional Requirements
- Heterogeneous device support: The platform should consider the inherent heterogeneity of native IoT device hardware platforms and ensure seamless integration, offering flexible enrollment for various device flavors.
- Device virtualization: Physical devices and their resources should be appropriately virtualized, adhering to a standardized information model that allows easy querying though common syntax.
- Ubiquitous access and transparent communication: Devices should be accessible irrespective of constraints imposed by end-node network topology and configuration. In scenarios where devices do not support IPv6 or are not IPv6 routable, devices should be accessed though transparent gateways that provide protocol translation or Network Address Translation.
- Multi-tenancy: Multi-tenancy mechanisms should be supported, providing complete resource isolation of different tenants and preventing unauthorized access.
- Data processing of large-scale monitoring data: The platform should be able to process and analyze large amounts of monitoring data and provide useful insights based on user-defined metrics.
- Visualization of monitoring data: The platform should visualize monitoring data, data integrity verification, and event-based notifications in a comprehensible and user-friendly manner (e.g., graphs, labels, etc.).
- Data integrity: The platform should ensure the integrity and consistency of monitoring data throughout its life cycle by developing robust mechanisms to prevent unauthorized modifications. This enhances the reliability and trustworthiness of the monitoring data, maintaining its accuracy and validity when visualized.
- Real-time alerting: A robust event-based notification system that operates on predefined rules should be incorporated, promptly alerting users about the violations of these rules. The platform should be capable of generating real-time alerts, ensuring timely communication of critical events or sensory data deviations from predefined rules.
3.1.2. Non-Functional Requirements
- Security and privacy: The platform should integrate robust authentication and authorization mechanisms for users and IoT devices. Control and application data communication should be encrypted and integrity-protected.
- High availability: The platform should provide high availability of monitoring services as well as an IoT data storage service, taking into consideration diverse network conditions.
- Fault tolerance: The platform should be resilient and able to recover from faults and failures on both cloud and IoT devices.
- Scalability: The platform should be capable of handling large volumes of data in terms of storage, retrieval, and processing capabilities.
- Quality of service (QoS): QoS should be maintained as high as possible in terms of interactions with cloud services (e.g., low latency of data retrieval, near-real-time notification mechanism) and IoT devices (e.g., low latency of IoT data updates).
3.2. Logical Architecture
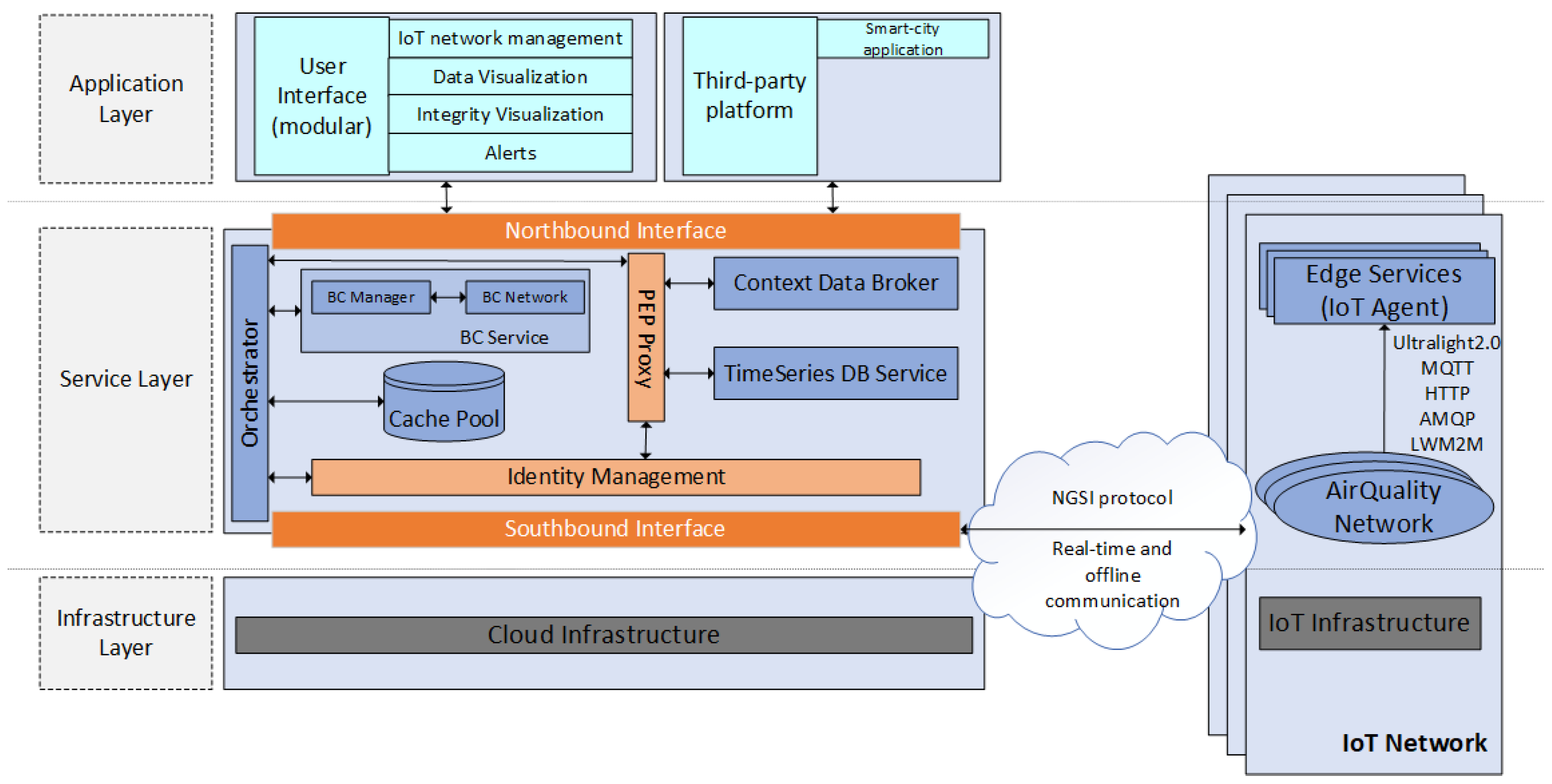
4. Implementation Details of the EPOPTIS Platform
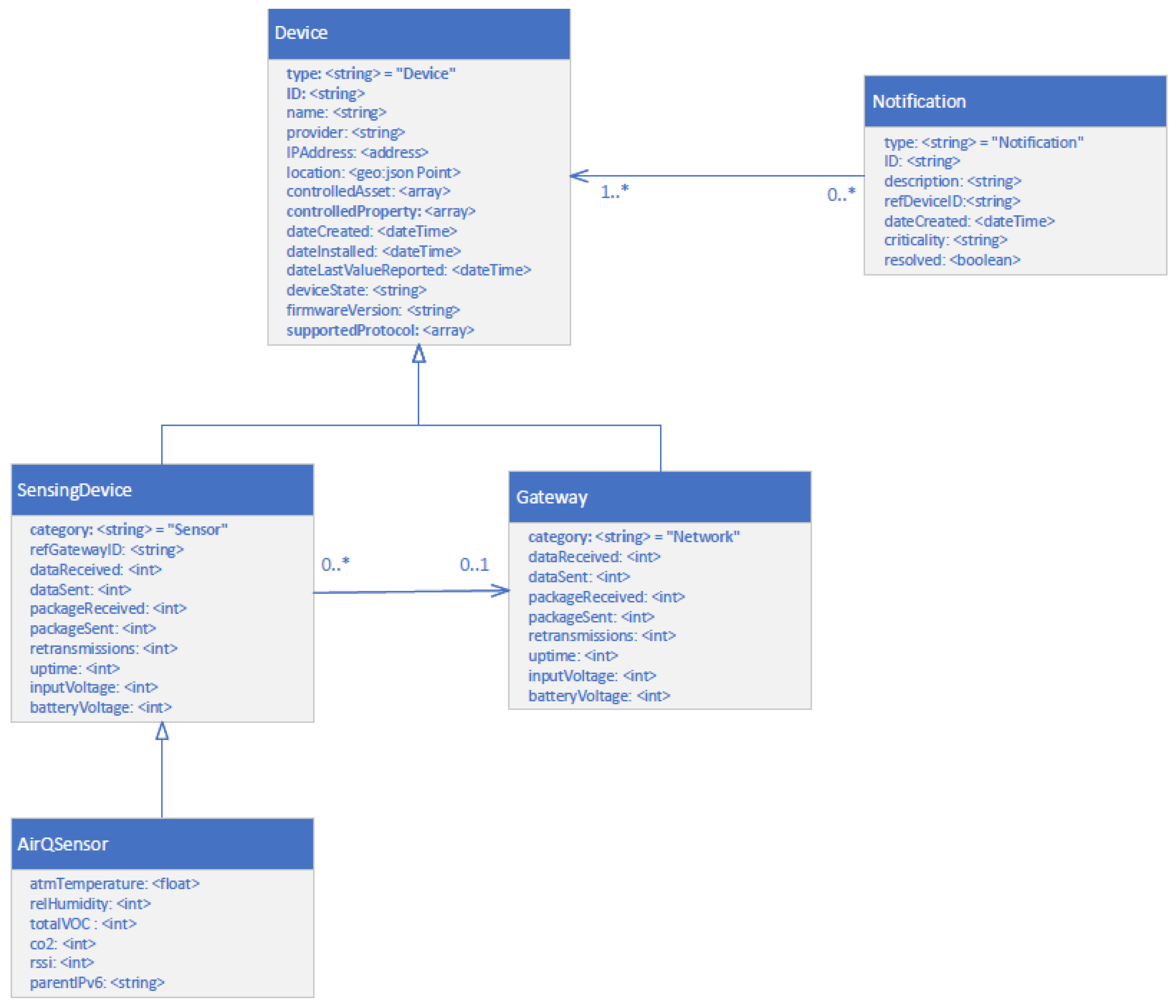
4.1. Context Information Model
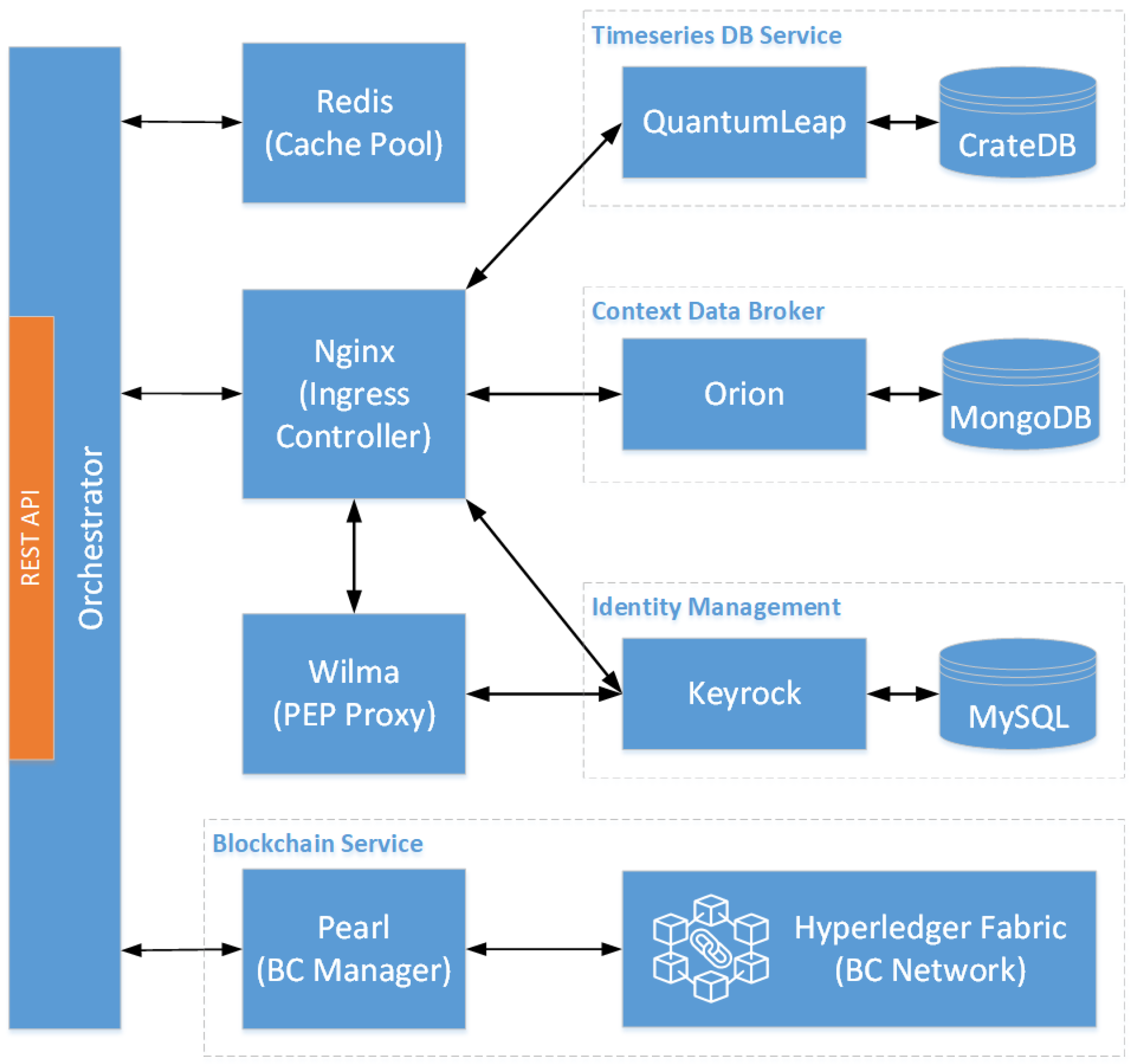
4.2. Functional Architecture
4.2.1. Orchestrator
- Identity Module: This module is responsible for managing information about logical hierarchical entities on our platform, including virtual representation of human and non-human users (i.e., IoT users), ecosystems, roles, permissions, and their relevant connection graphs. The Identity Module utilizes the Identity Management component to store and associate this type of information in its internal database.
- Device Module: This module is responsible for retrieving information regarding physical devices and their association with IoT networks, supporting the retrieval of essential information about both types of physical devices, gateways, and sensing devices, including their attributes, as described in the contextual model. The Device Module utilizes the Context Data Broker component to retrieve this kind of information.
- Statistics Module: This module is responsible for retrieving and calculating statistics about logical entities and their associations. It provides detailed information about users, devices, and ecosystems, including statistics such as the number of users within an IoT ecosystem and the assigned role for each user within an IoT network. The Statistics Module utilizes the Context Data Broker and the Identity Management components to provide this type of information.
- Notification Module: This module is responsible for the retrieval of information regarding generating notifications and organizing them in two categories: the IoT Ecosystem or the Device. The retrieved information includes criticality level, descriptions, and the attribute on which the notification was triggered. Additionally, this module allows authorized users to manage generated notifications (e.g., appropriately labeling them once they have been resolved). The Notification Module utilizes the Context Data Broker to support these operations.
- IoT Module: This module is responsible for registering a new device and updating its attributes. It receives NGSI payloads from IoT networks and implements mechanisms for: (i) triggering alert-based notifications according to the SC rules, (ii) caching the incoming NGSI payloads using a Cache Pool, calculating and storing the appropriate hash value required for the data integrity verification, and (iii) updating contextual information in order to support a seamless interaction with the IoT networks. This module utilizes the Cache Pool, the Context Data Broker, and the BC Service (described in Section 4.2.6) in order to support all the above operations.
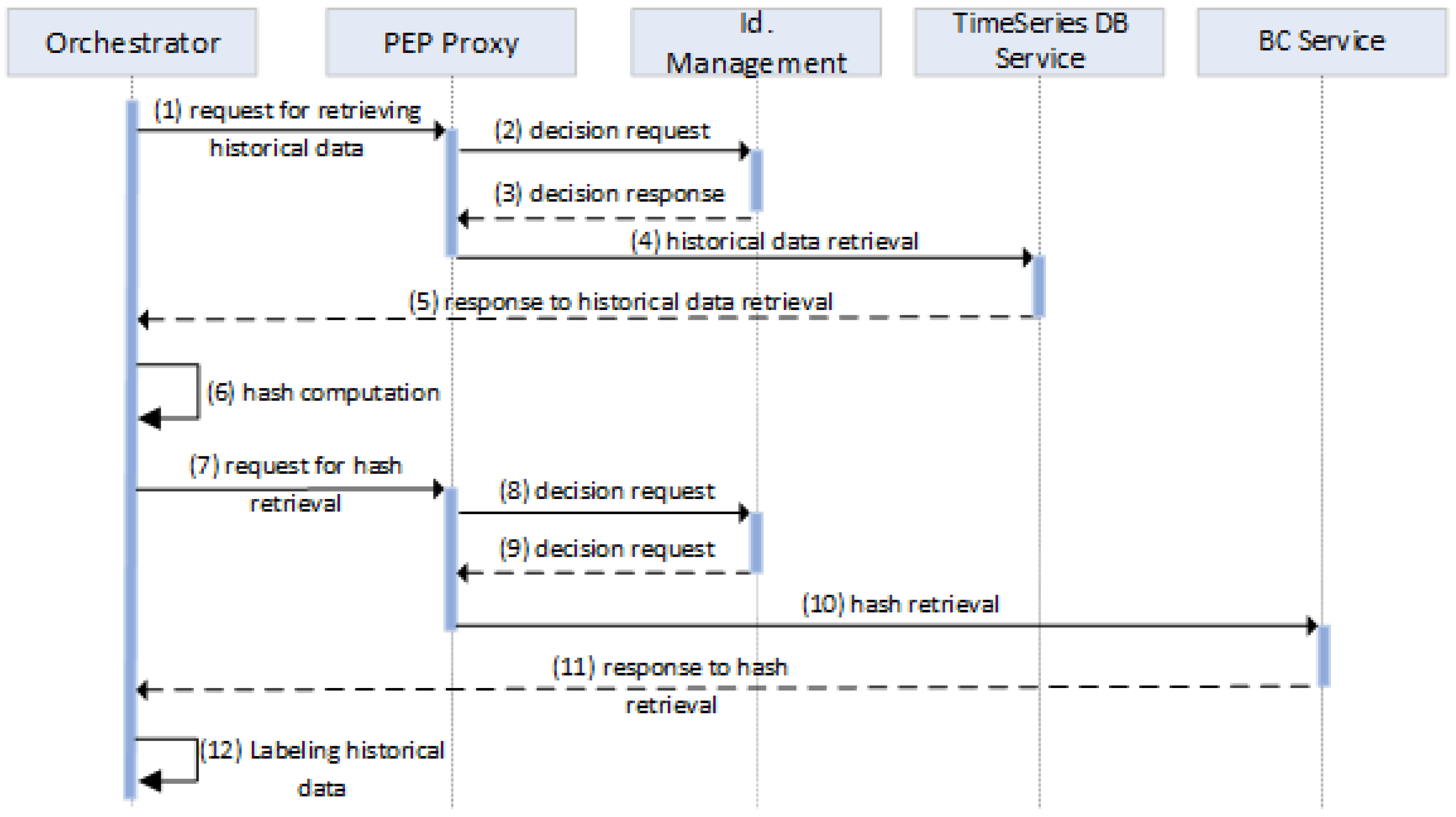
- Query Module: This module is responsible for retrieving historical data and labeling them utilizing the data integrity verification mechanism. A detailed description of how this mechanism works is provided in Section 4.3. This module utilizes the TimeSeries DB service for retrieving historical data and the BC Service to obtain the appropriate hash value used to label them according to the outcome of the integrity protection mechanism (i.e., corrupted/not corrupted).
4.2.2. Identity Management and PEP Proxy
4.2.3. Cache Pool
4.2.4. Context Data Broker
4.2.5. TimeSeries DB Service
4.2.6. Blockchain Service
- Data labeling. SCs are crucial for the automated label compliance assignment of the collected IoT data. These enforce configurable rules that encompass various criteria, such as acceptable sensor data ranges, input voltage limits, etc. When data are submitted to the platform, SCs automatically assign a label based on these predefined criteria. Therefore, during the data retrieval processes, the historical data are labeled as compliant or non-compliant (based on the previously reported rules), also feeding a suitable API for visualization purposes.
- Hash computation and storage: The BC Service is responsible for storing and retrieving hash values, which are computed by the Orchestrator using the SHA-3 (https://csrc.nist.gov/pubs/fips/202/final (accessed on 25 March 2024)) hash algorithm. The corresponding hashed values are securely stored in the immutable BC ledger in a key-value format, significantly reducing retrieval times and conserving storage space within the ledger, while the actual data records are stored in the TimeSeries DB. The hashed values can be retrieved by the Orchestrator in order to support the data integrity verification mechanism during historical data retrieval.
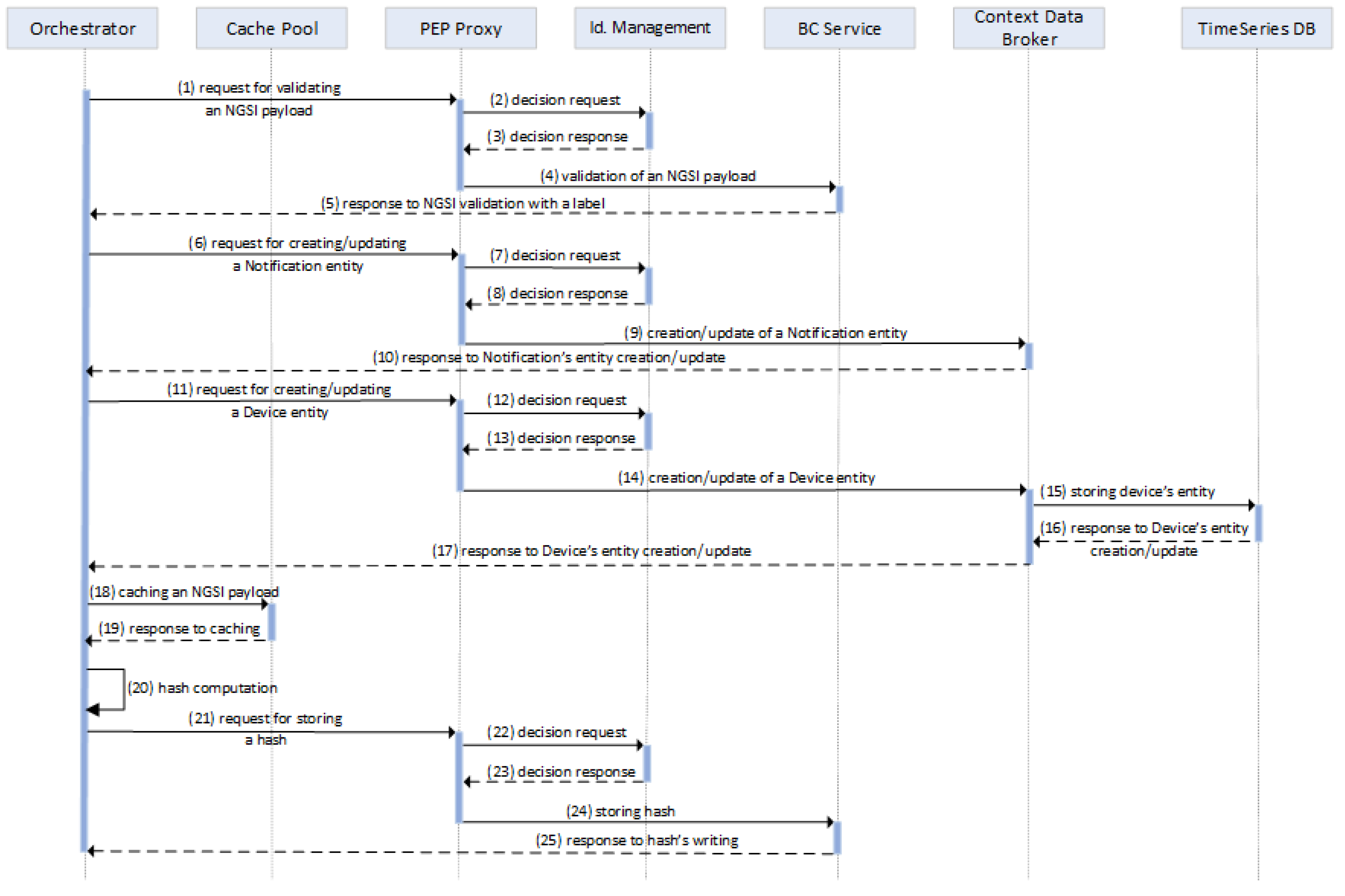
4.3. Interactions of the Functional Components
4.3.1. NGSI Data Persistent Storage
4.3.2. Retrieval of Historical Data
5. Performance Evaluation
5.1. Testbed and Deployment
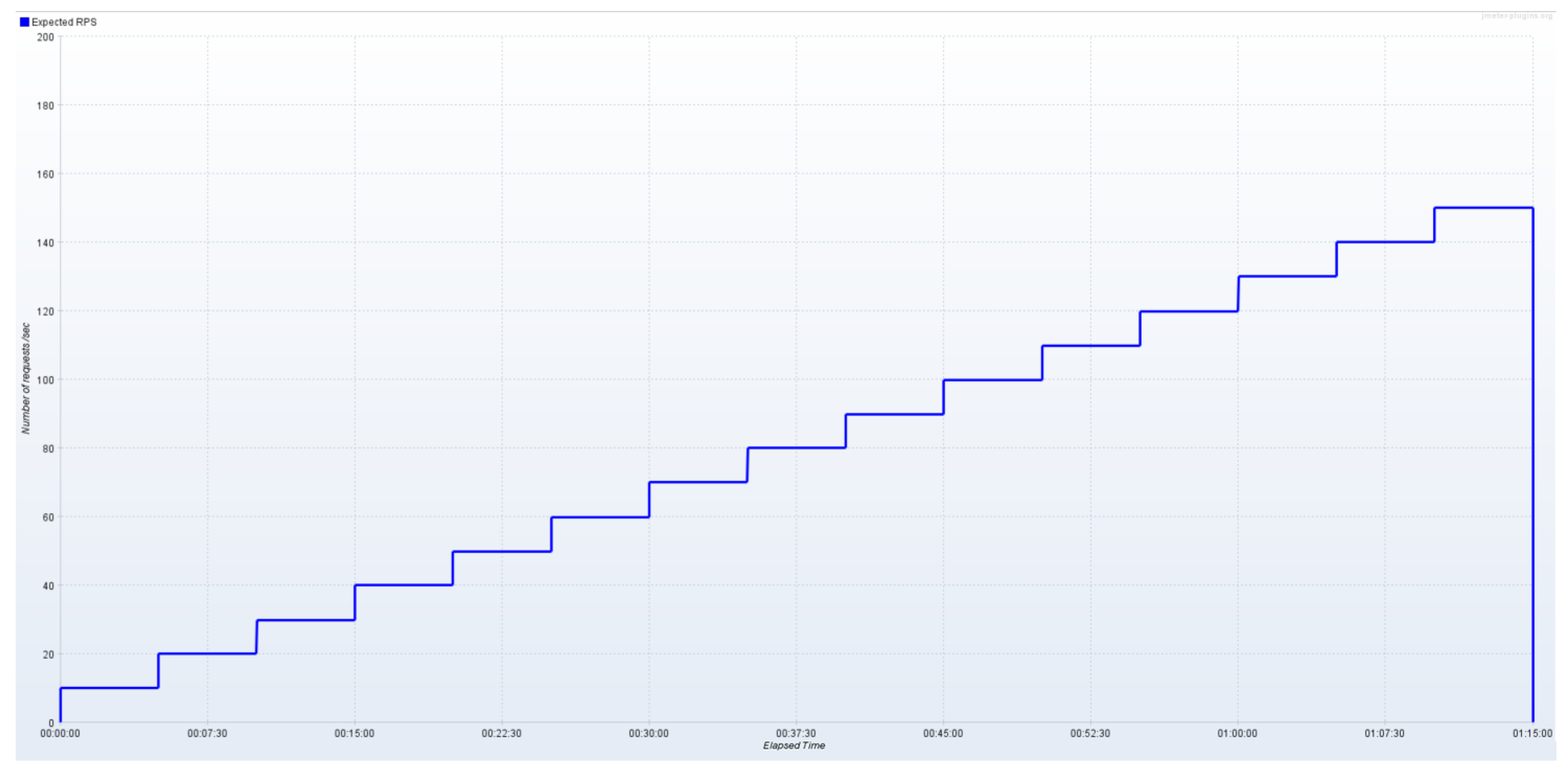
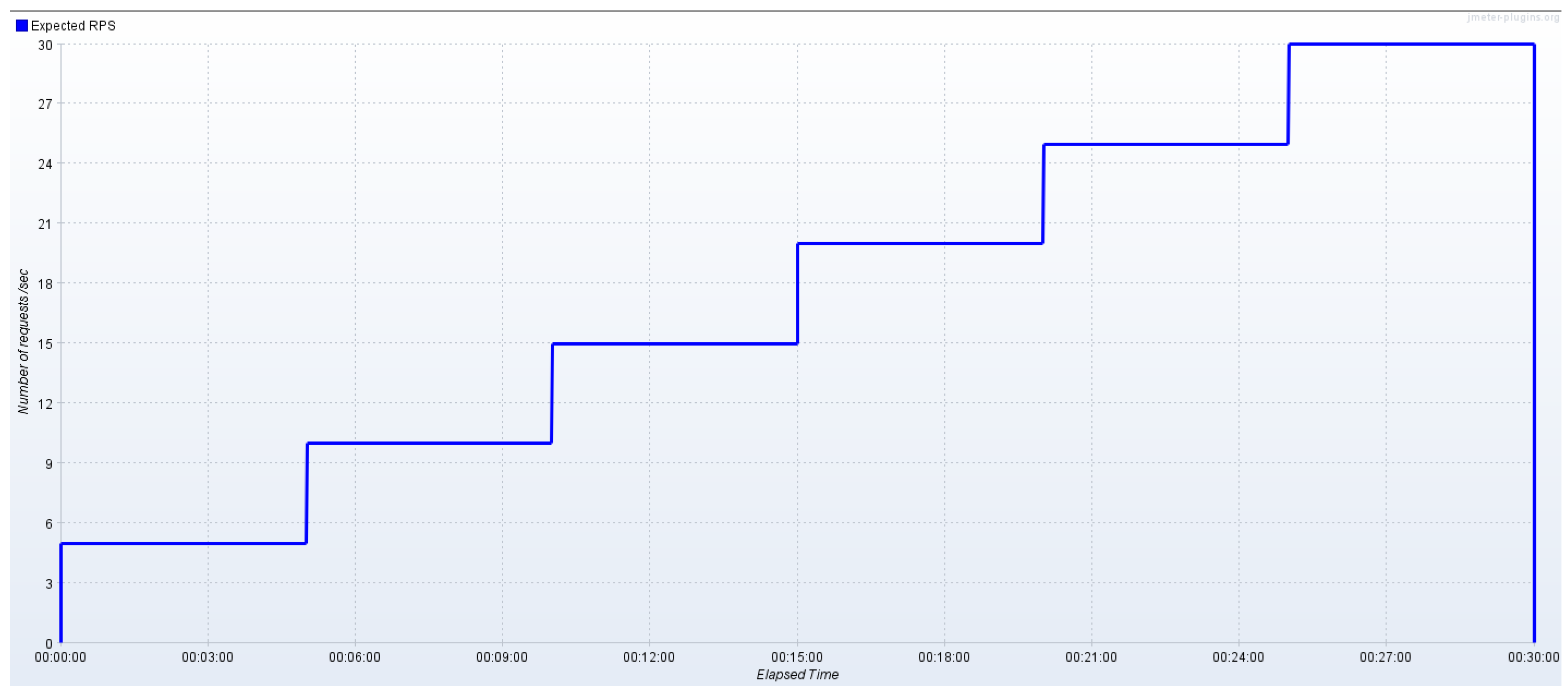
5.2. Test Plan
5.2.1. Ecosystems without Data Integrity Verification
5.2.2. Ecosystems with Data Integrity Verification
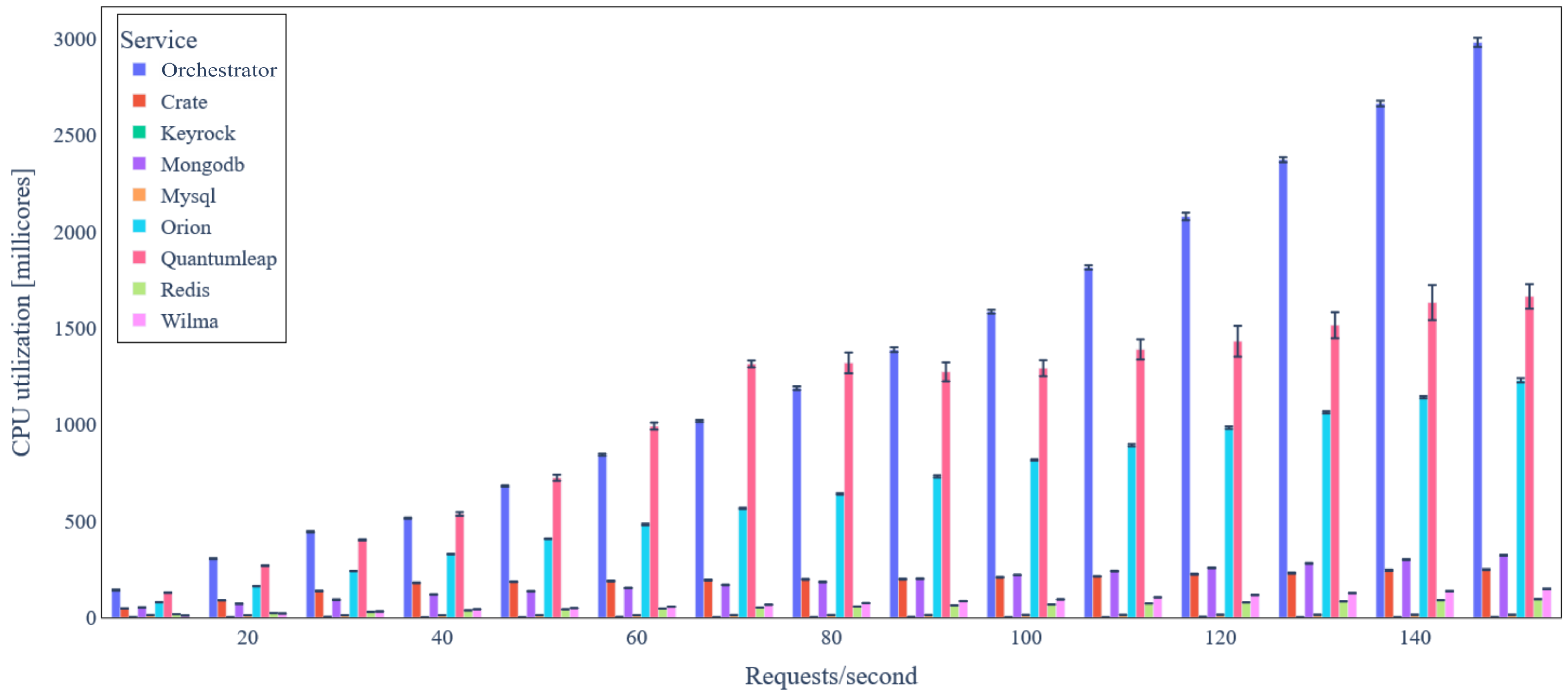
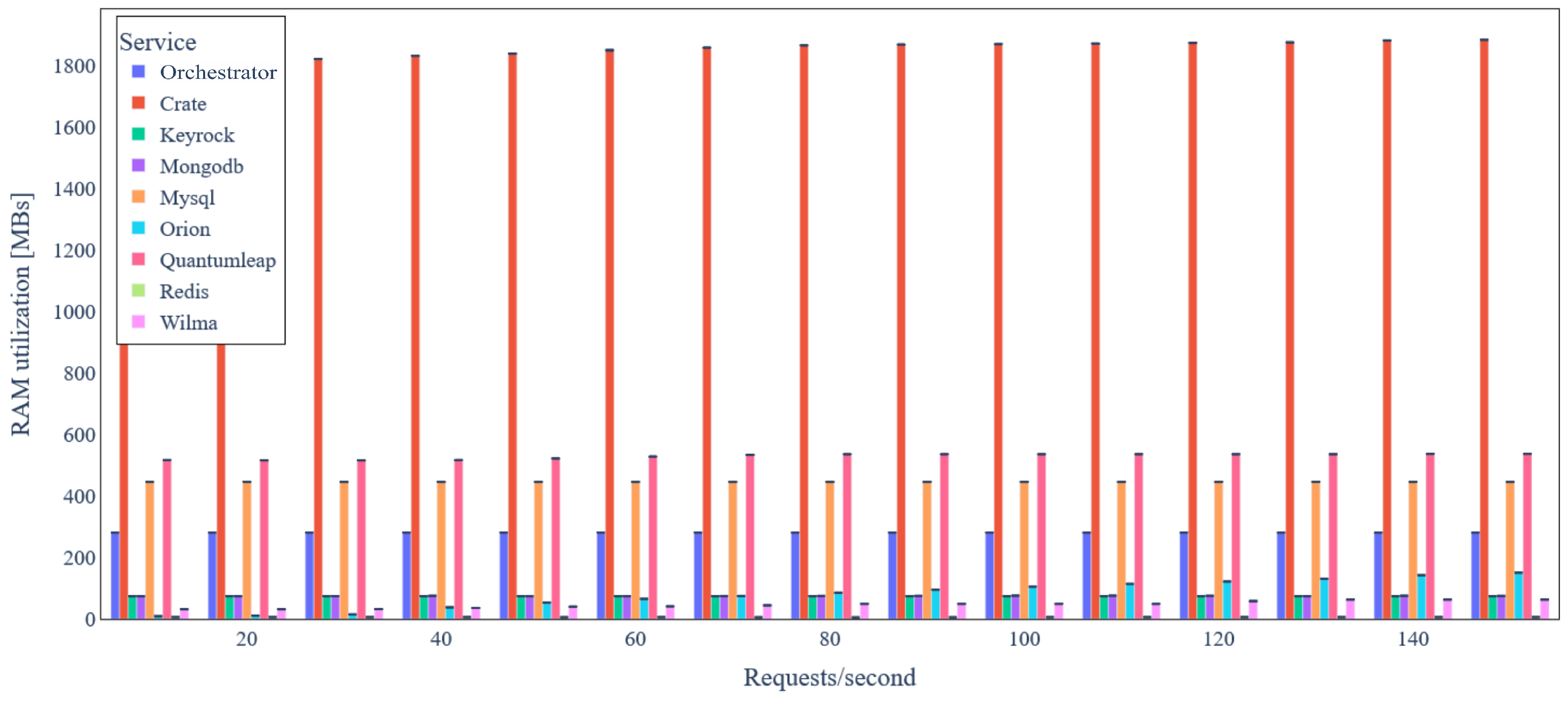
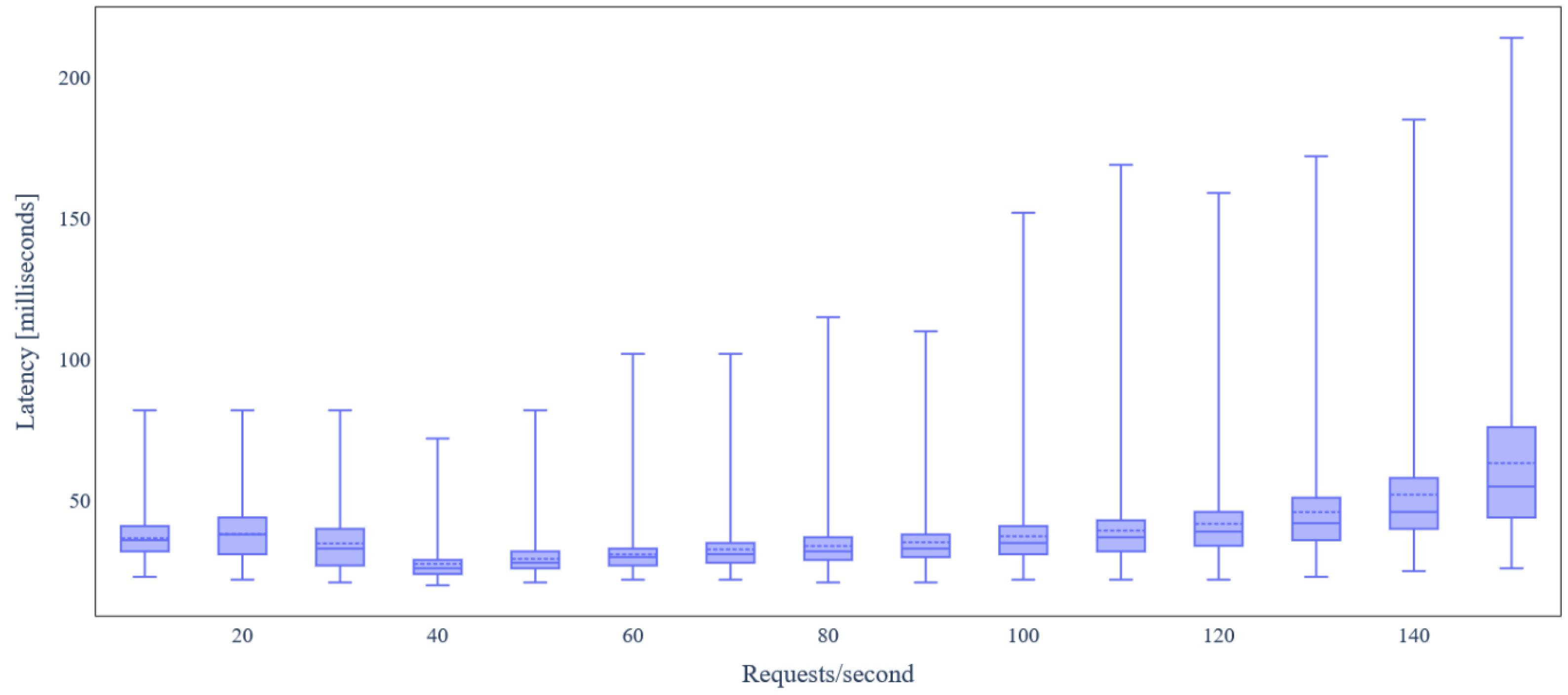
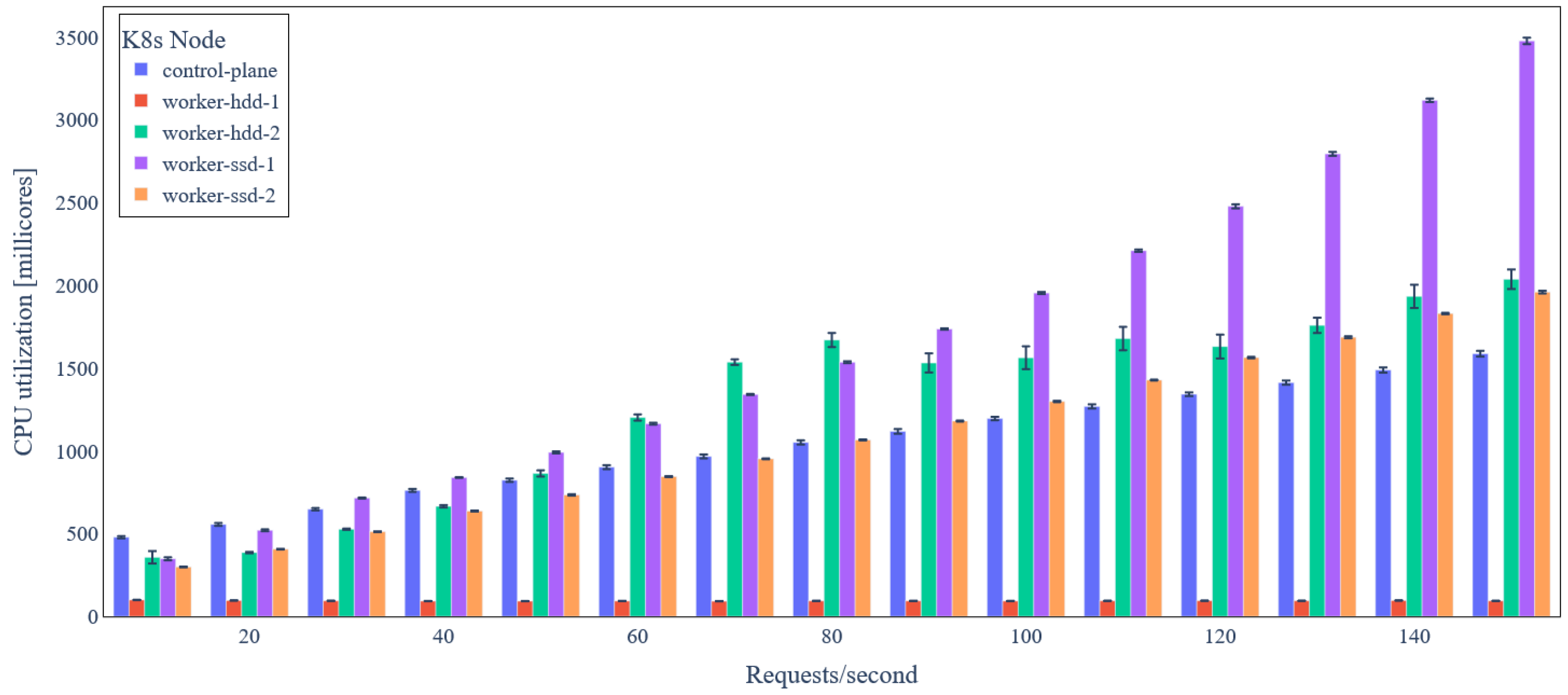
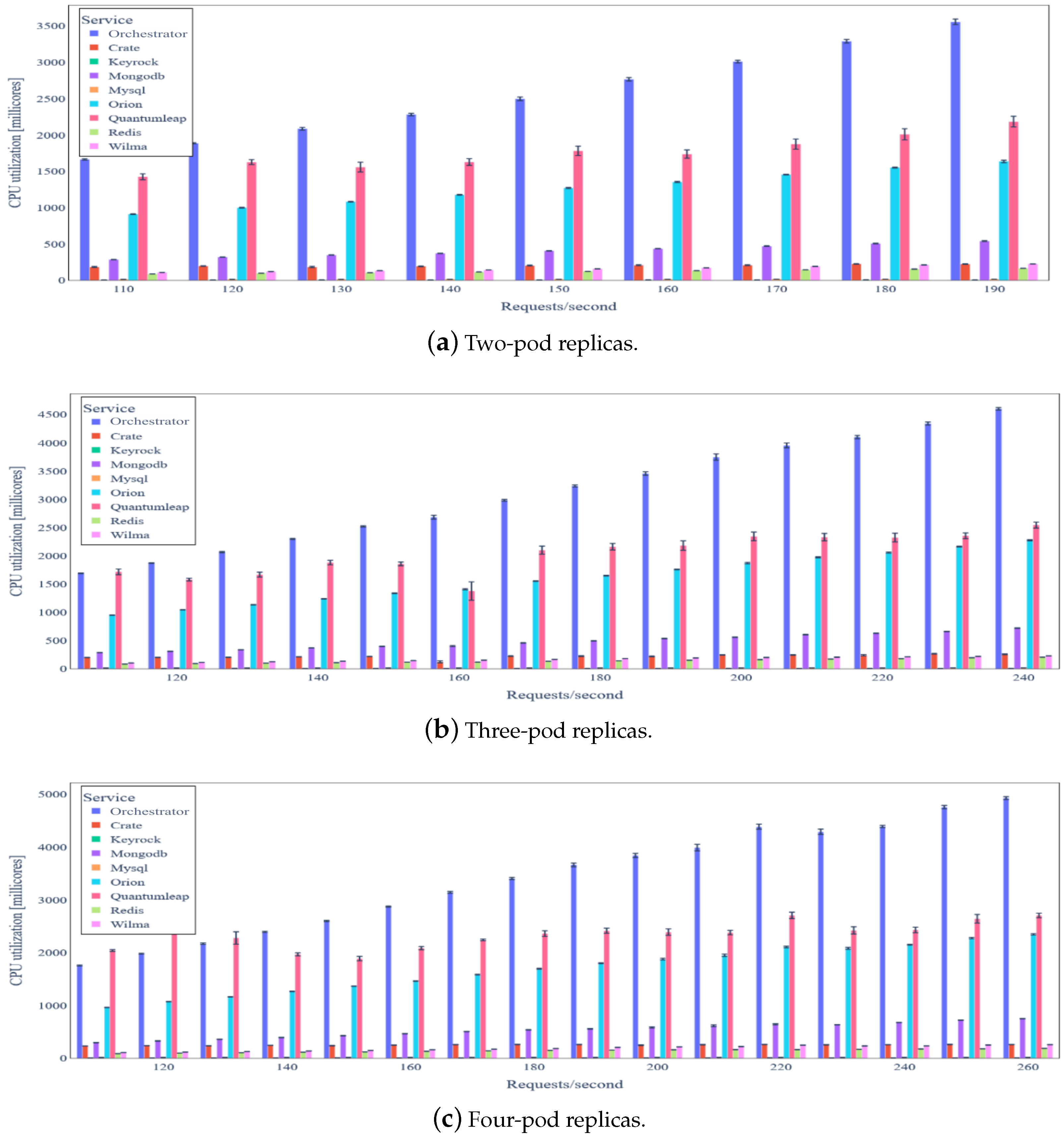
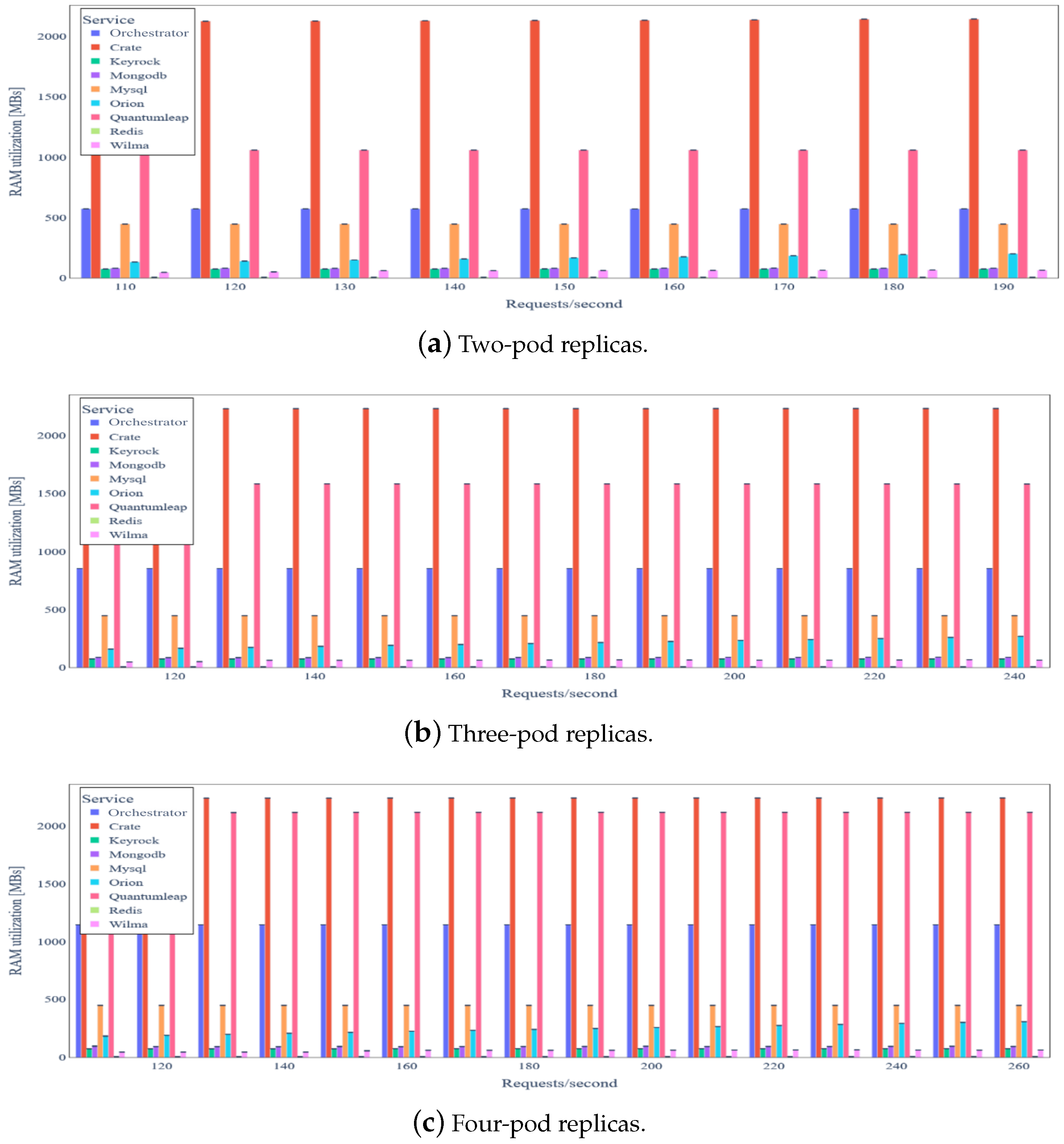
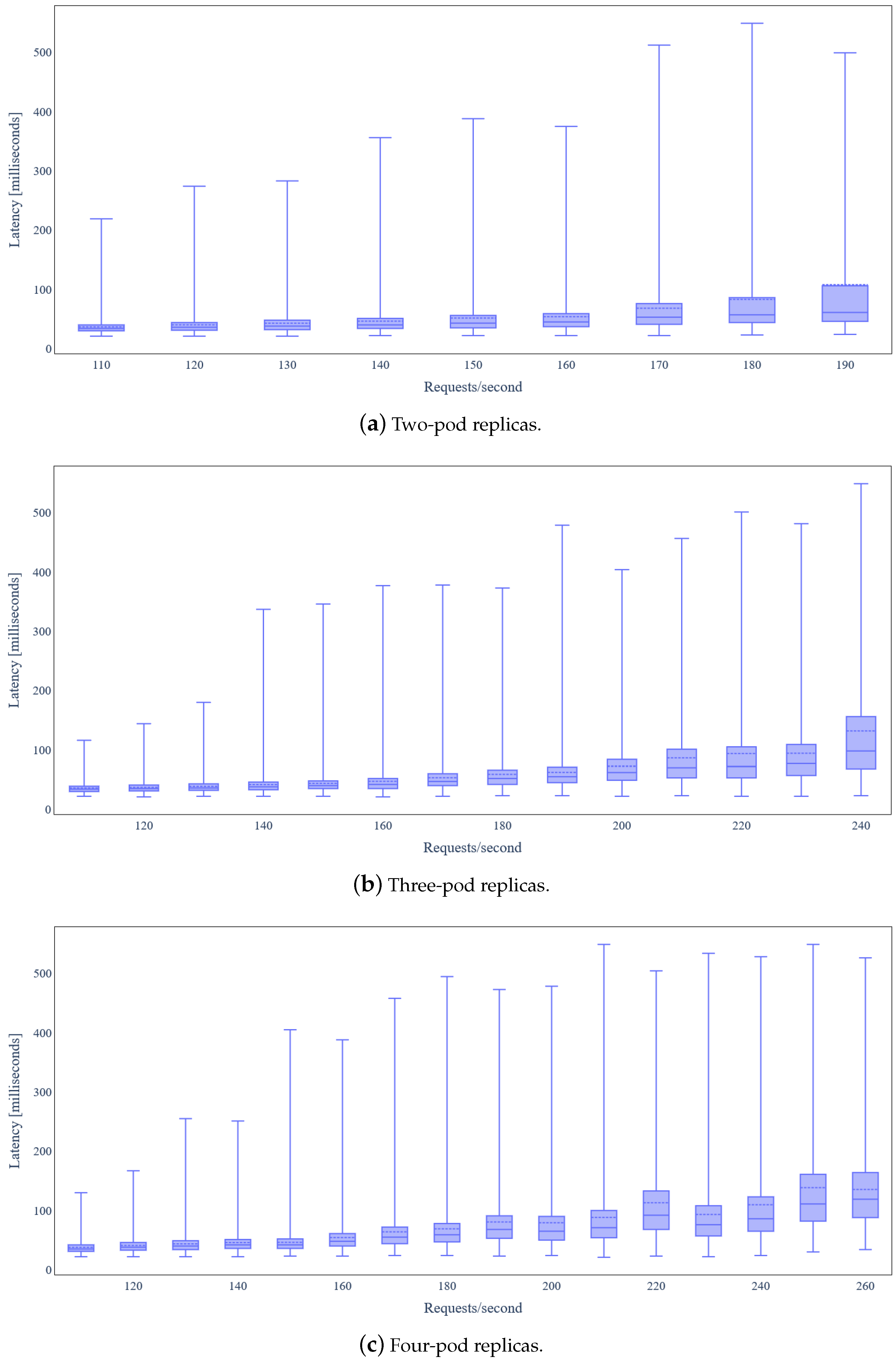
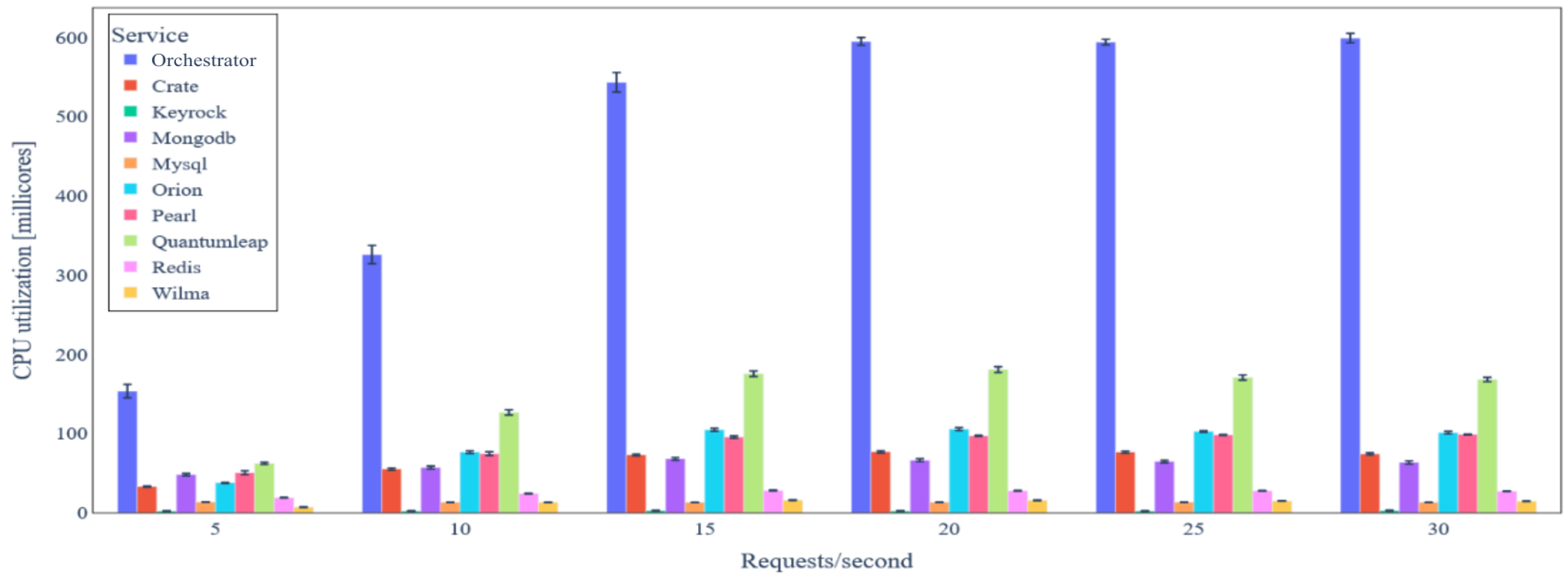
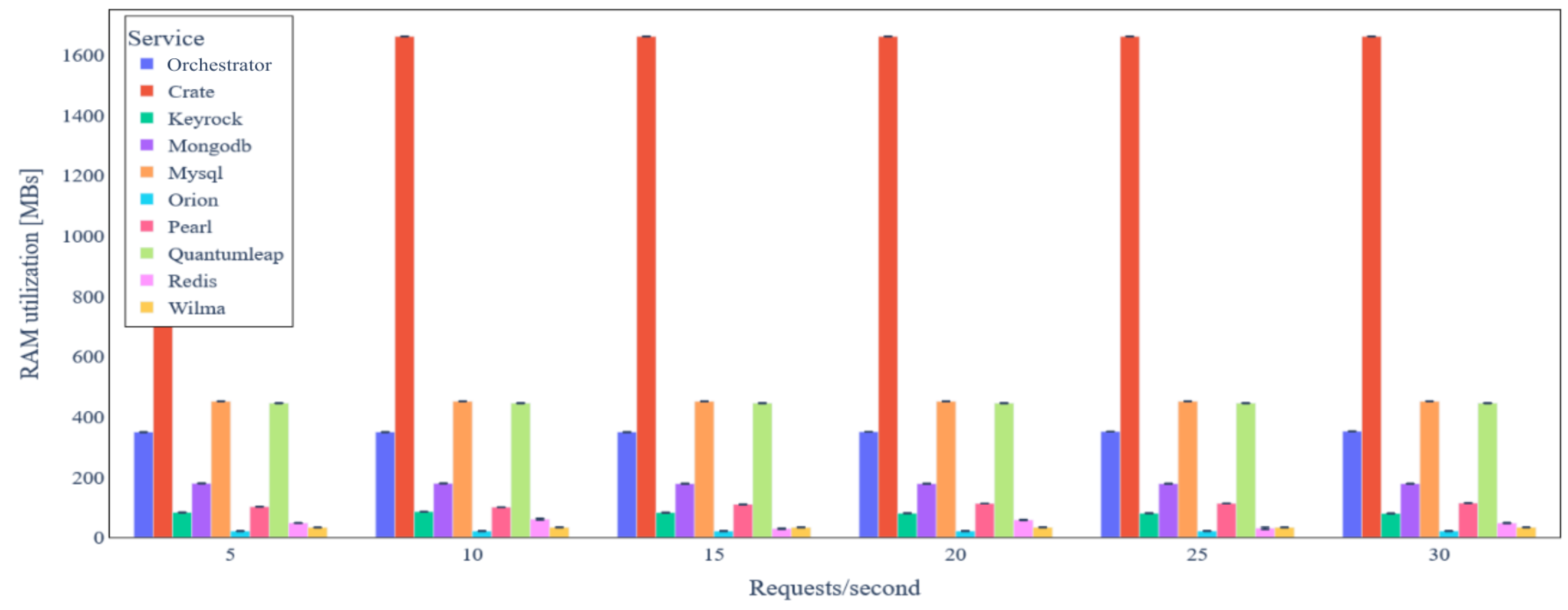
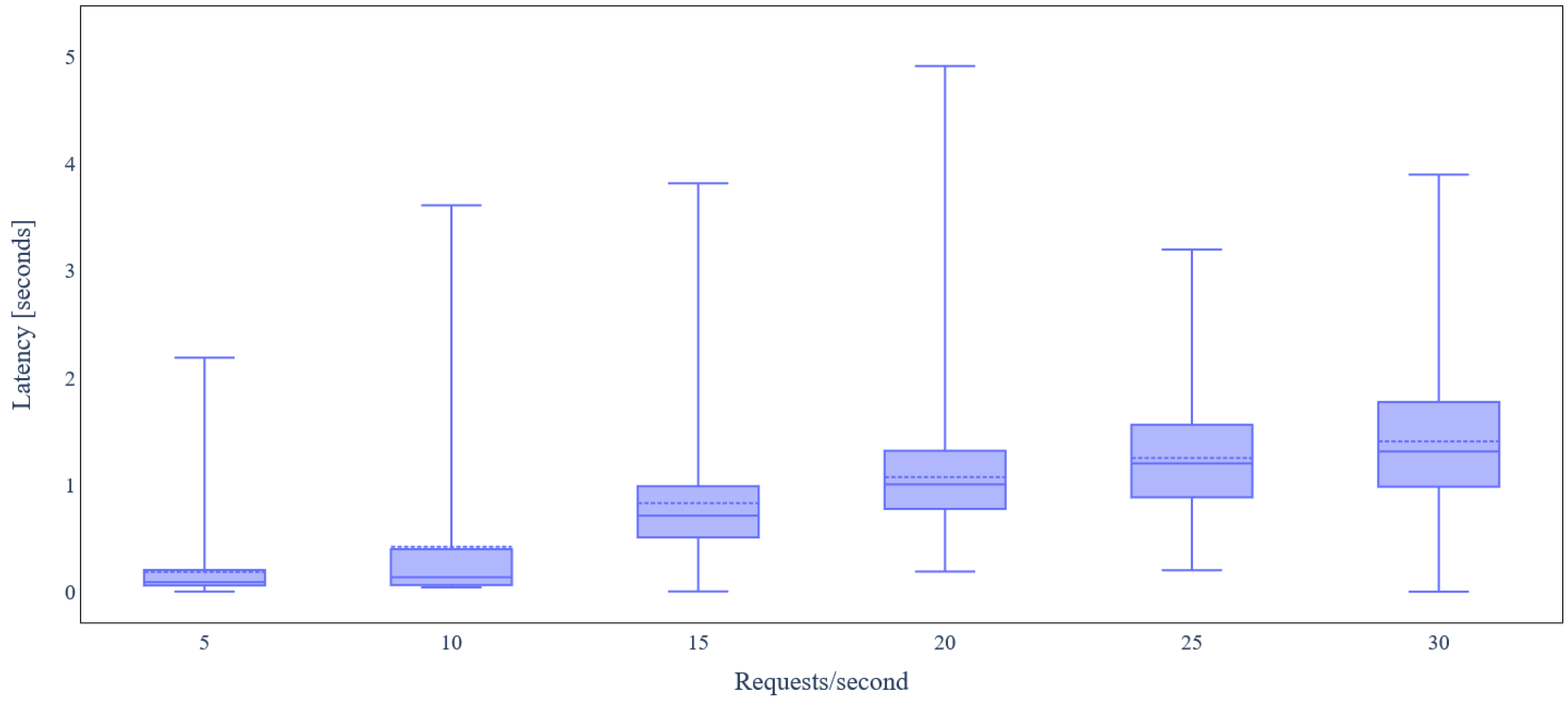
5.3. Evaluation Results
5.3.1. Ecosystems without Data Integrity Verification
5.3.2. Ecosystems with Data Integrity Verification
6. Conclusions and Further Work
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| API | Application Programming Interface |
| BC | Blockchain |
| CI | Cloud Infrastructure |
| CIM | Context Information Model |
| CPU | Central Processing Unit |
| CSS | Cloud Storage Service |
| DNS | Domain Name System |
| FTP | File Transfer Protocol |
| HLF | HyperLedger Fabric |
| HTTP | Hypertext Transfer Protocol |
| IoT | Internet of Things |
| LG | Load Generator |
| MaaS | Monitoring as a Service |
| MQTT | Message Queuing Telemetry Transport |
| NGSI | Next-Generation Service Interface |
| PDP | Policy Decision Point |
| PEP | Policy Enforcement Point |
| RAM | Random Access Memory |
| REST | Representational State Transfer |
| SC | Smart Contract |
| TPA | Third-Party Auditor |
| VM | Virtual Machine |
References
- Kalaitzakis, M.; Bouloukakis, M.; Charalampidis, P.; Dimitrakis, M.; Drossis, G.; Fragkiadakis, A.; Fundulaki, I.; Karagiannaki, K.; Makrogiannakis, A.; Margetis, G.; et al. Building a Smart City Ecosystem for Third Party Innovation in the City of Heraklion. In Mediterranean Cities and Island Communities: Smart, Sustainable, Inclusive and Resilient; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 19–56. [Google Scholar] [CrossRef]
- Afonso, J.A.; Monteiro, V.; Afonso, J.L. Internet of Things Systems and Applications for Smart Buildings. Energies 2023, 16, 2757. [Google Scholar] [CrossRef]
- Atalla, S.; Tarapiah, S.; Gawanmeh, A.; Daradkeh, M.; Mukhtar, H.; Himeur, Y.; Mansoor, W.; Hashim, K.F.B.; Daadoo, M. IoT-Enabled Precision Agriculture: Developing an Ecosystem for Optimized Crop Management. Information 2023, 14, 205. [Google Scholar] [CrossRef]
- Ejaz, W.; Naeem, M.; Shahid, A.; Anpalagan, A.; Jo, M. Efficient Energy Management for the Internet of Things in Smart Cities. IEEE Commun. Mag. 2017, 55, 84–91. [Google Scholar] [CrossRef]
- Folgado, F.J.; González, I.; Calderón, A.J. Data acquisition and monitoring system framed in Industrial Internet of Things for PEM hydrogen generators. Internet Things 2023, 22, 100795. [Google Scholar] [CrossRef]
- Tarrés-Puertas, M.I.; Brosa, L.; Comerma, A.; Rossell, J.M.; Dorado, A.D. Architecting an Open-Source IIoT Framework for Real-Time Control and Monitoring in the Bioleaching Industry. Appl. Sci. 2024, 14, 350. [Google Scholar] [CrossRef]
- Lampropoulos, G.; Siakas, K.; Anastasiadis, T. Internet of Things in the Context of Industry 4.0: An Overview. Int. J. Entrep. Knowl. 2019, 7, 4–19. [Google Scholar] [CrossRef]
- Chatterjee, A.; Ahmed, B.S. IoT anomaly detection methods and applications: A survey. Internet Things 2022, 19, 100568. [Google Scholar] [CrossRef]
- Xenakis, A.; Karageorgos, A.; Lallas, E.; Chis, A.E.; Gonzalez-Velez, H. Towards Distributed IoT/Cloud based Fault Detection and Maintenance in Industrial Automation. Procedia Comput. Sci. 2019, 151, 683–690. [Google Scholar] [CrossRef]
- Passlick, J.; Dreyer, S.; Olivotti, D.; Grutzner, L.; Eilers, D.; Breitner, M. Predictive maintenance as an internet of things enabled business model: A taxonomy. Electron. Mark. 2021, 31, 67–87. [Google Scholar] [CrossRef]
- Psychoula, I.; Singh, D.; Chen, L.; Chen, F.; Holzinger, A.; Ning, H. Users’ Privacy Concerns in IoT Based Applications. In Proceedings of the 2018 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computing, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/CBDCom/IOP/SCI), Guangzhou, China, 8–12 October 2018; pp. 1887–1894. [Google Scholar] [CrossRef]
- Jeon, H.; Lee, C. Internet of Things Technology: Balancing privacy concerns with convenience. Telemat. Inform. 2022, 70, 101816. [Google Scholar] [CrossRef]
- Babun, L.; Denney, K.; Celik, Z.B.; McDaniel, P.; Uluagac, A.S. A survey on IoT platforms: Communication, security, and privacy perspectives. Comput. Netw. 2021, 192, 108040. [Google Scholar] [CrossRef]
- Shelby, Z.; Hartke, K.; Bormann, C. RFC 7252—The Constrained Application Protocol (CoAP). Available online: https://datatracker.ietf.org/doc/html/rfc7252 (accessed on 25 March 2024).
- Fedor, M.; Schoffstall, M.; Davin, J.; Case, J. RFC 1157—Simple Network Management Protocol (SNMP). Available online: https://datatracker.ietf.org/doc/html/rfc1157 (accessed on 25 March 2024).
- Enns, R.; Bjorklund, M.; Schoenwaelder, J.; Bierman, A. RFC 6241—Network Configuration Protocol (NETCONF). Available online: https://datatracker.ietf.org/doc/html/rfc6241 (accessed on 25 March 2024).
- Bierman, A.; Bjorklund, M.; Watsen, K. RFC 8040—RESTCONF Protocol. Available online: https://datatracker.ietf.org/doc/html/rfc8040 (accessed on 25 March 2024).
- Veillette, M.; Stok, P.; Pelov, A.; Bierman, A.; Bormann, C. CoAP Management Interface (CORECONF). Available online: https://datatracker.ietf.org/doc/draft-ietf-core-comi/ (accessed on 25 March 2024).
- Li, Z.; Xie, Z.; Liu, L.; Wu, Y. Design and Implementation of an Integrated City-Level IoT Platform Based on Edge Computing and Cloud Native. In Proceedings of the 2022 IEEE 6th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Beijing, China, 3–5 October 2022; pp. 463–467. [Google Scholar] [CrossRef]
- Lopez-Riquelme, J.; Pavon-Pulido, N.; Navarro-Hellin, H.; Soto-Valles, F.; Torres-Sanchez, R. A software architecture based on FIWARE cloud for Precision Agriculture. Agric. Water Manag. 2017, 183, 123–135. [Google Scholar] [CrossRef]
- Neagu, G.; Preda, S.; Stanciu, A.; Florian, V. A Cloud-IoT based sensing service for health monitoring. In Proceedings of the 2017 E-Health and Bioengineering Conference (EHB), Sinaia, Romania, 22–24 June 2017; pp. 53–56. [Google Scholar] [CrossRef]
- Galán, F.; Fazio, M.; Celesti, A.; Glikson, A.; Villari, M. Exploiting the FIWARE Cloud Platform to Develop a Remote Patient Monitoring System. In Proceedings of the 2015 IEEE Symposium on Computers and Communication (ISCC), Larnaca, Cyprus, 6–9 July 2015. [Google Scholar] [CrossRef]
- Fernández, P.; Santana, J.M.; Ortega, S.; Trujillo, A.; Suárez, J.P.; Domínguez, C.; Santana, J.; Sánchez, A. SmartPort: A Platform for Sensor Data Monitoring in a Seaport Based on FIWARE. Sensors 2016, 16, 417. [Google Scholar] [CrossRef] [PubMed]
- Hui, L.; Gui-rong, W.; Jian-ping, W.; Peiyong, D. Monitoring platform of energy management system for smart community. In Proceedings of the 2017 29th Chinese Control And Decision Conference (CCDC), Chongqing, China, 28–30 May 2017; pp. 1832–1836. [Google Scholar] [CrossRef]
- Openhab Smart Home Platform. Available online: https://www.openhab.org (accessed on 22 March 2024).
- Samsung SmartThings Platform. Available online: https://www.samsung.com/us/smartthings (accessed on 22 March 2024).
- Apple HomeKit. Available online: https://www.apple.com/shop/accessories/all/homekit (accessed on 22 March 2024).
- Amazon Web Services IoT. Available online: https://aws.amazon.com/iot (accessed on 22 March 2024).
- IBM Watson. Available online: https://www.ibm.com/watson (accessed on 22 March 2024).
- Liu, B.; Yu, X.L.; Chen, S.; Xu, X.; Zhu, L. Blockchain Based Data Integrity Service Framework for IoT Data. In Proceedings of the 2017 IEEE International Conference on Web Services (ICWS), Honolulu, HI, USA, 25–30 June 2017; pp. 468–475. [Google Scholar] [CrossRef]
- Wu, X.; Kong, F.; Shi, J.; Bao, L.; Gao, F.; Li, J. A blockchain internet of things data integrity detection model. In Proceedings of the 1st International Conference on Advanced Information Science and System; Association for Computing Machinery, New York, NY, USA, 15–17 November 2019. AISS ’19. [Google Scholar] [CrossRef]
- Eghmazi, A.; Ataei, M.; Landry, R.J.; Chevrette, G. Enhancing IoT Data Security: Using the Blockchain to Boost Data Integrity and Privacy. IoT 2024, 5, 20–34. [Google Scholar] [CrossRef]
- Chanai, P.; Kakkasageri, M. Blockchain-based data integrity framework for Internet of Things. Int. J. Inf. Secur. 2024, 23, 519–532. [Google Scholar] [CrossRef]
- Zhang, K.; Xiao, H.; Liu, Q. Data Integrity Verification Scheme Based on Blockchain Smart Contract. In Proceedings of the 2022 IEEE International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Wuhan, China, 9–11 December 2022; pp. 857–863. [Google Scholar] [CrossRef]
- Chen, C.; Wang, L.; Long, Y.; Luo, Y.; Chen, K. A blockchain-based dynamic and traceable data integrity verification scheme for smart homes. J. Syst. Archit. 2022, 130, 102677. [Google Scholar] [CrossRef]
- Rahman, M.S.; Chamikara, M.; Khalil, I.; Bouras, A. Blockchain-of-blockchains: An interoperable blockchain platform for ensuring IoT data integrity in smart city. J. Ind. Inf. Integr. 2022, 30, 100408. [Google Scholar] [CrossRef]
- Doulgeraki, P.; Karuzaki, E.; Sykianaki, E.; Partarakis, N.; Bouhli, M.; Ntoa, S.; Stephanidis, C. Web-Based Management for Internet of Things Ecosystems. In Proceedings of the HCI International 2023 Posters, Copenhagen, Denmark, 23–28 July 2023; Stephanidis, C., Antona, M., Ntoa, S., Salvendy, G., Eds.; Springer: Cham, Switzerland, 2023; pp. 475–482. [Google Scholar]
- Domínguez-Bolaño, T.; Campos, O.; Barral, V.; Escudero, C.J.; García-Naya, J.A. An overview of IoT architectures, technologies, and existing open-source projects. Internet Things 2022, 20, 100626. [Google Scholar] [CrossRef]
- Dragoni, N.; Giallorenzo, S.; Lafuente, A.L.; Mazzara, M.; Montesi, F.; Mustafin, R.; Safina, L. Microservices: Yesterday, Today, and Tomorrow. In Present and Ulterior Software Engineering; Springer International Publishing: Berlin/Heidelberg, Germany, 2017; pp. 195–216. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Contribution | Scope | Commercial |
|---|---|---|
| City-level IoT [19] | Generic | No |
| MEWiN [20] | Agricultural water management | No |
| [21] | Health monitoring | No |
| [22] | Remote patient monitoring | No |
| SmartPort [23] | Seaport data monitoring | No |
| [24] | Energy management | No |
| Openhab [25] | Smart home applications | No |
| SmartThings [26] | Smart home applications | Yes |
| Apple HomeKit [27] | Smart home applications | Yes |
| Amazon Web Services IoT [28] | Generic | Yes |
| IBM Watson [29] | Generic | Yes |
| Contribution | Scope | Limitations |
|---|---|---|
| [30] | Generic | Standalone service not evaluated within a real platform; BC-compliant client required; fees have to be paid; significant overhead for encryption/decryption; whole data records stored in the public ledger |
| [31] | Generic | Data stored in BC; simulated evaluation system |
| [32] | Generic | Integrity verification process not supported by SCs |
| [33] | Generic | Resource-intensive cryptographic operations required for the clients; simulated BC used |
| [34] | Generic | Gas required for the SC execution; not clear which BC is used for the core functionalities; only data owners can retrieve data, thus there is no support for authorized third-party applications; this a standalone verification service not integrated within a real platform |
| [35] | Smart homes | Limited evaluation results provided; a private bitcoin network is used for BC that cannot support a high number of transactions; no flexibility is provided as SCs are not used; the scheme is not integrated or tested with a real platform |
| [36] | Smart cities | Increased latency due to multiple consensus algorithms’ execution; IoT devices required to send BC transactions |
| vCPUs | RAM | Storage | Operating System | |
|---|---|---|---|---|
| LG infrastructure | 4 | 8 GB | 20 GB HDD | Ubuntu 20.04LTS |
| CI infrastructure— master node | 4 | 10 GB | 30 GB HDD | Ubuntu 20.04LTS |
| CI infrastructure— worker nodes (4×) | 4 | 10 GB | 30 GB HDD/SSD | Ubuntu 20.04LTS |
| CI infrastructure— worker nodes (BC) | 4 | 16 GB | 50 GB SSD | Ubuntu 20.04LTS |
| Software Component | Software Version | Best Performing Configuration |
|---|---|---|
| MicroK8s | 1.26.1 | - |
| Orchestrator | 0.1.0 | • Gunicorn worker type: sync |
| • Gunicorn workers: 9 | ||
| Redis | 7.0.7 | - |
| Keyrock | 8.0.0 | - |
| MySQL | 8.0.32 | - |
| Orion | 3.6.0 | • reqMutexPolicy: none |
| • reqPool: 4 | ||
| MongoDB | 4.4.11 | - |
| QuantumLeap | 0.8.0 | • Gunicorn worker type: gthread |
| • Gunicorn workers: 9 | ||
| CrateDB | 4.6.7 | • Heap size: 2 GB |
| Wilma | 8.0.0 | - |
| Pearl | 0.1.0 | - |
| Hyperledger Fabric | 2.4 | - |
| Parameter | Values |
|---|---|
| Average data update load (Basic scenario—1 replica) | 10–150 requests/s (step = 10) |
| Average data update load (2 replicas) | 10–190 requests/s (step = 10) |
| Average data update load (3 replicas) | 10–240 requests/s (step = 10) |
| Average data update load (4 replicas) | 10–260 requests/s (step = 10) |
| Payload size | 190 bytes |
| Service | Baseline | Two Pods | Three Pods | Four Pods | ||||
|---|---|---|---|---|---|---|---|---|
| CPU | RAM | CPU | RAM | CPU | RAM | CPU | RAM | |
| Orchestrator | 2999 | 281 | 2497 | 572 | 2510 | 850 | 2593 | 1144 |
| QuantumLeap | 1660 | 537 | 1650 | 1058 | 1720 | 1583 | 1750 | 2102 |
| Orion | 1235 | 154 | 1230 | 167 | 1320 | 190 | 1361 | 212 |
| MongoDB | 352 | 75 | 346 | 80 | 353 | 85 | 367 | 89 |
| Crate | 266 | 1808 | 201 | 2130 | 215 | 2201 | 235 | 2230 |
| Wilma | 147 | 62 | 150 | 62 | 142 | 62 | 146 | 58 |
| Redis | 114 | 6 | 119 | 6 | 115 | 7 | 116 | 6 |
| MySQL | 15 | 446 | 14 | 445 | 15 | 446 | 15 | 446 |
| Keyrock | 2 | 74 | 2 | 75 | 3 | 75 | 3 | 74 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zervoudakis, P.; Karamolegkos, N.; Plevridi, E.; Charalampidis, P.; Fragkiadakis, A. EPOPTIS: A Monitoring-as-a-Service Platform for Internet-of-Things Applications. Sensors 2024, 24, 2208. https://0-doi-org.brum.beds.ac.uk/10.3390/s24072208
Zervoudakis P, Karamolegkos N, Plevridi E, Charalampidis P, Fragkiadakis A. EPOPTIS: A Monitoring-as-a-Service Platform for Internet-of-Things Applications. Sensors. 2024; 24(7):2208. https://0-doi-org.brum.beds.ac.uk/10.3390/s24072208
Chicago/Turabian StyleZervoudakis, Petros, Nikolaos Karamolegkos, Eleftheria Plevridi, Pavlos Charalampidis, and Alexandros Fragkiadakis. 2024. "EPOPTIS: A Monitoring-as-a-Service Platform for Internet-of-Things Applications" Sensors 24, no. 7: 2208. https://0-doi-org.brum.beds.ac.uk/10.3390/s24072208