

Learning to Execute Timed-Temporal-Logic Navigation Tasks under Input Constraints in Obstacle-Cluttered Environments †
 , , ,
, , ,
Abstract
:1. Introduction
Related Works and Contributions
- We significantly extend the path planner of [30] by considering more generic workspaces, unicycle robot dynamics, and input constraints.
- The implemented low-level controller guarantees the robot’s safe navigation within workspaces cluttered with obstacles, requiring no prior knowledge of the system or extensive parameter tuning, which facilitates the integration into realistic experimental setups.
2. Preliminaries
3. Problem Formulation
- (i)
- , for all
- (ii)
- , for all
- (iii)
- , for all
4. Methodology
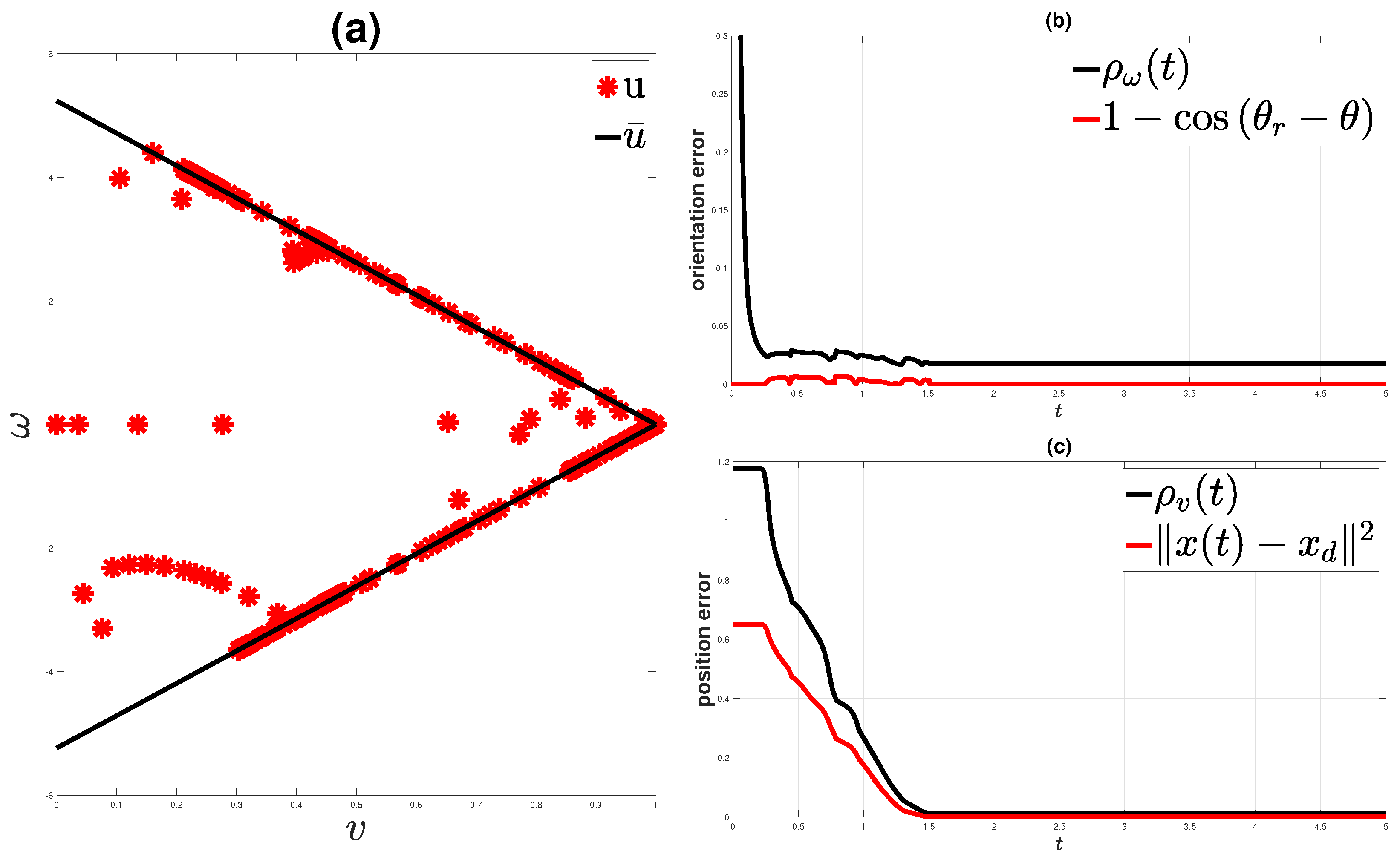
4.1. Motion Controller
4.2. High-Level Plan Generation
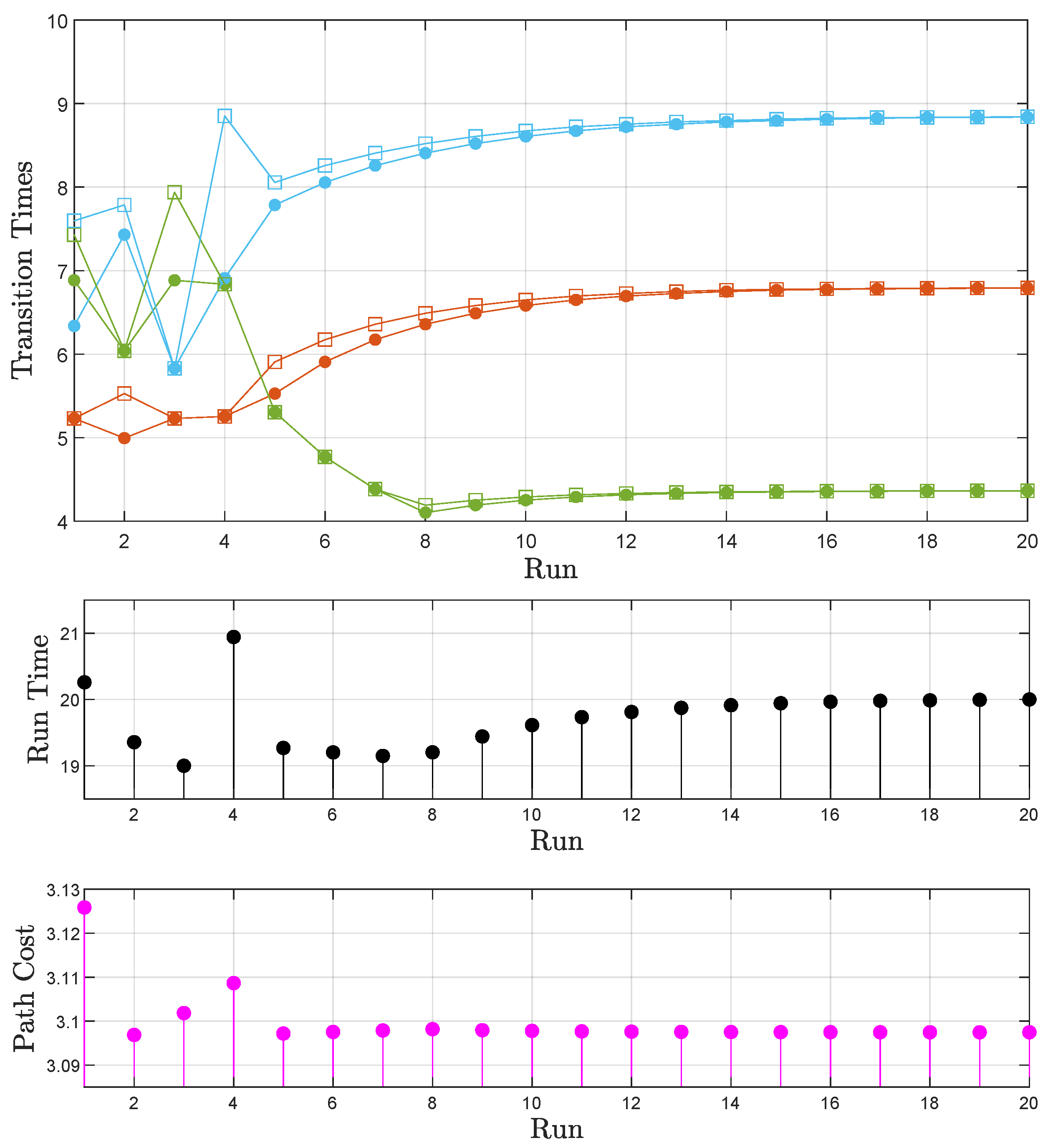
4.3. Iterative Learning
| Algorithm 1 Iterative Learning Algorithm |
| Input: Product Büchi Automaton , Initial position , Formula , Input Constraint level Output: Optimal Cost Path:
|
5. Simulation Study
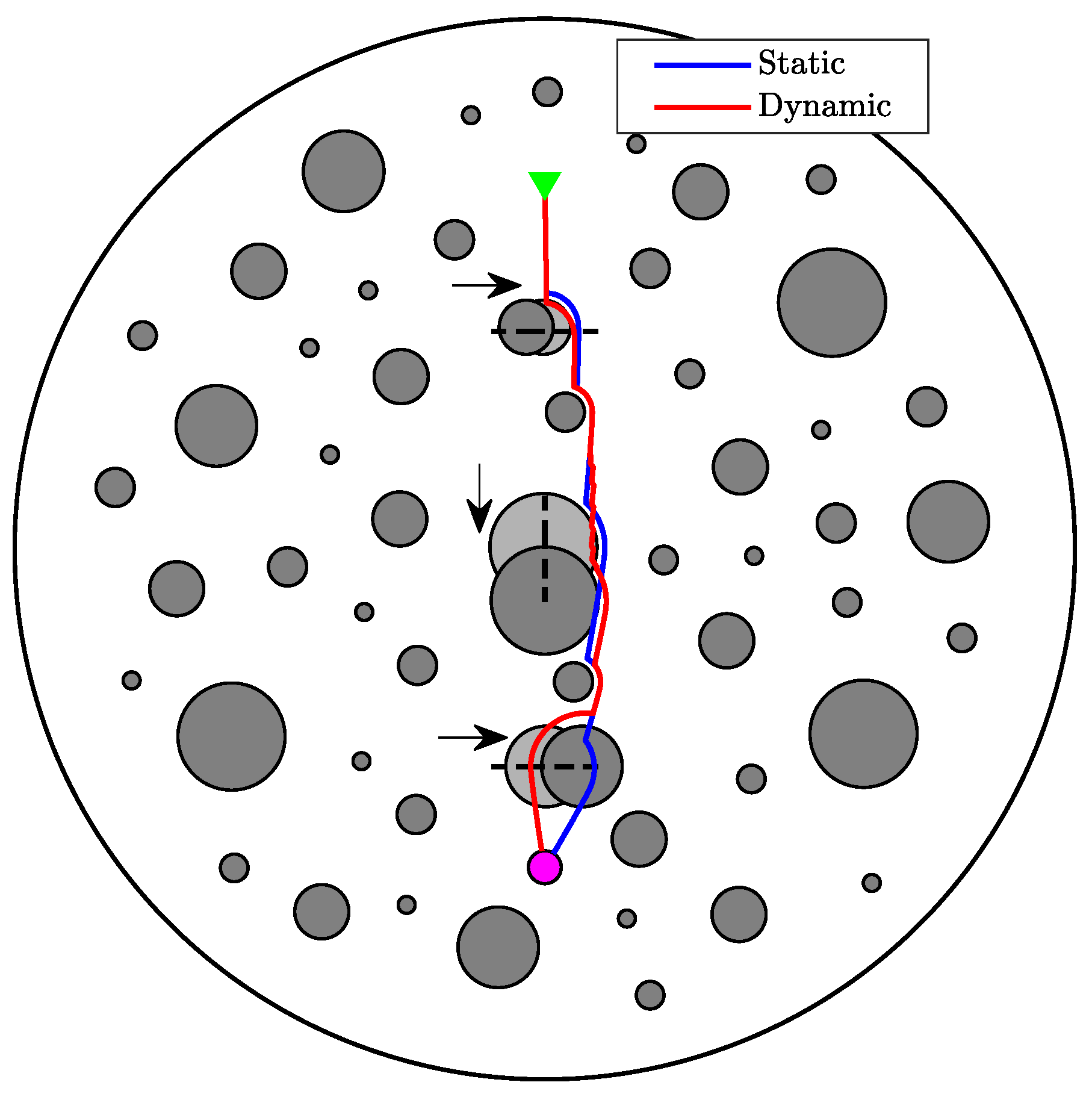
5.1. Dynamic Obstacle Environment
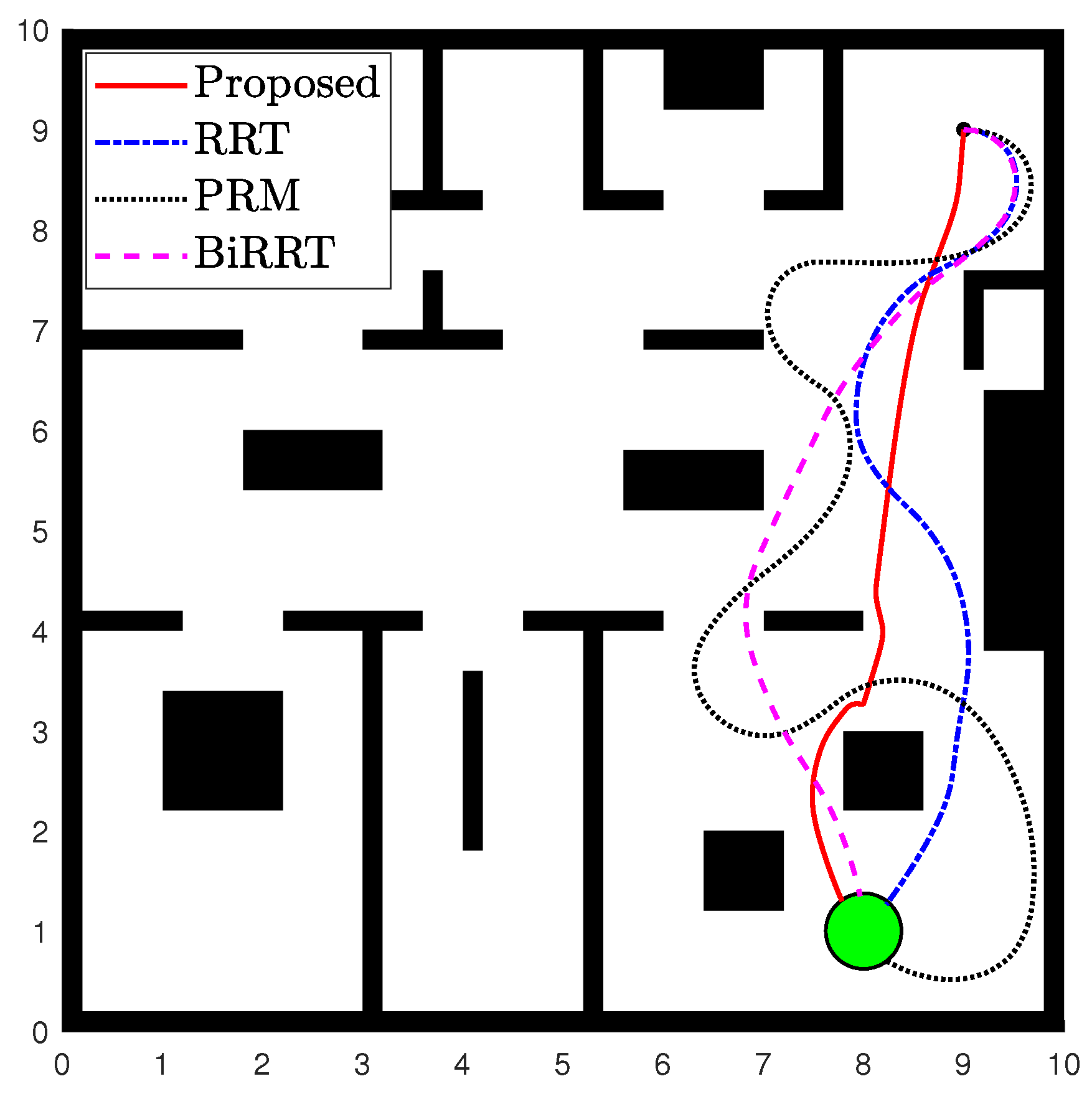
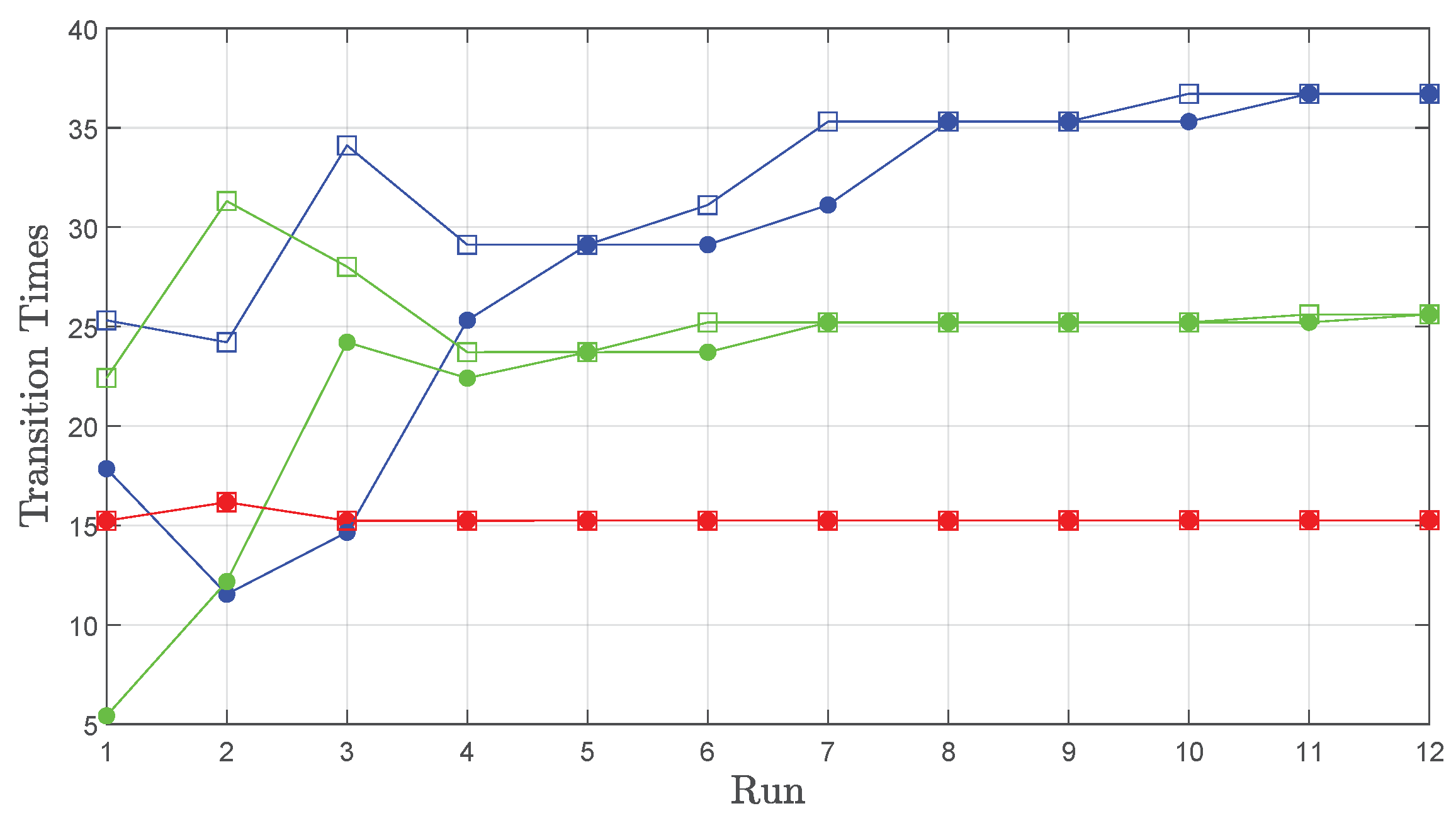
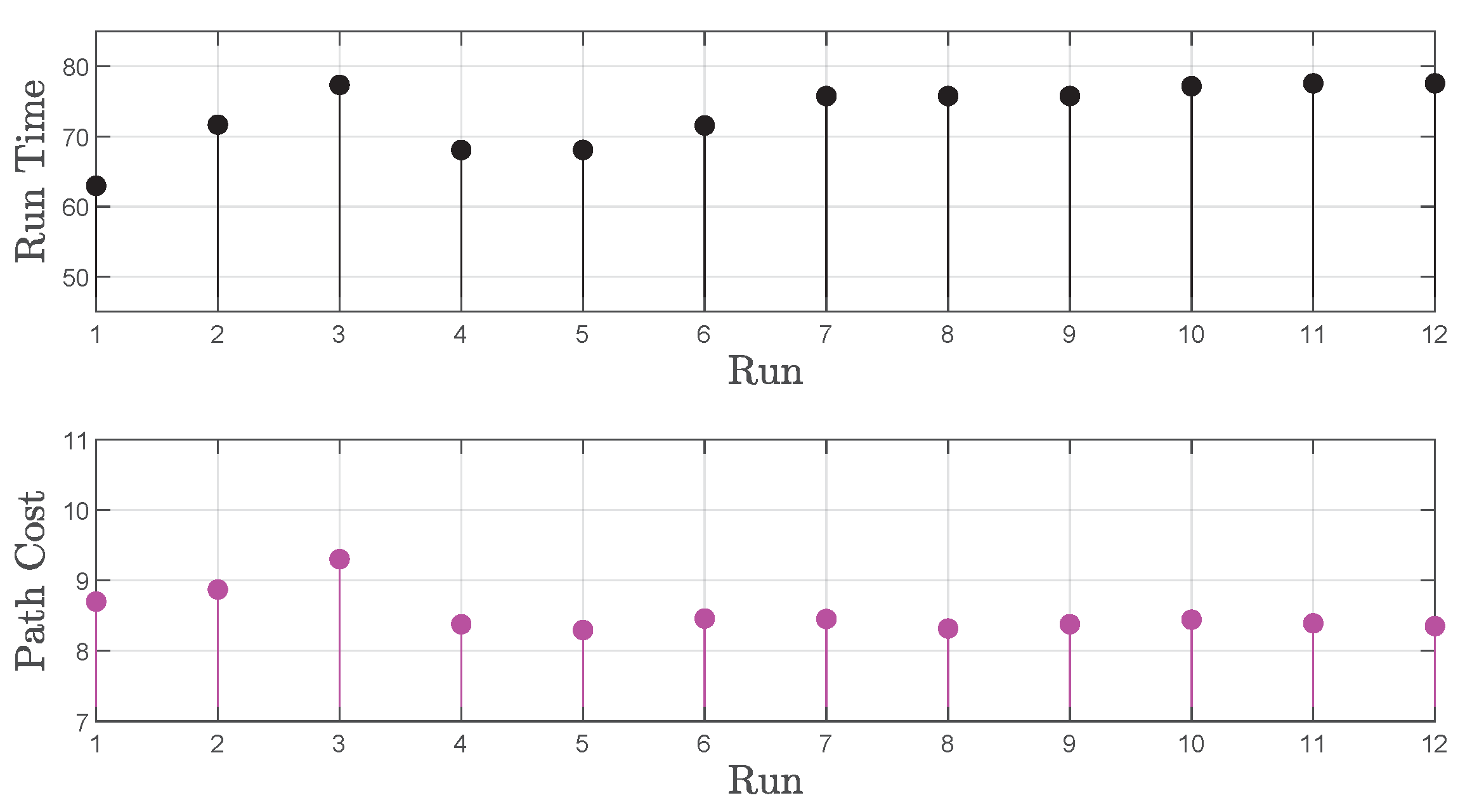
5.2. Comparison of Path Planners
- Proposed motion controller (Section 4.1)
- Rapidly Exploring Random Tree (RRT) planner
- Probabilistic Road Map (PRM) planner
- Bidirectional Rapidly Exploring Random Tree (BiRRT) planner
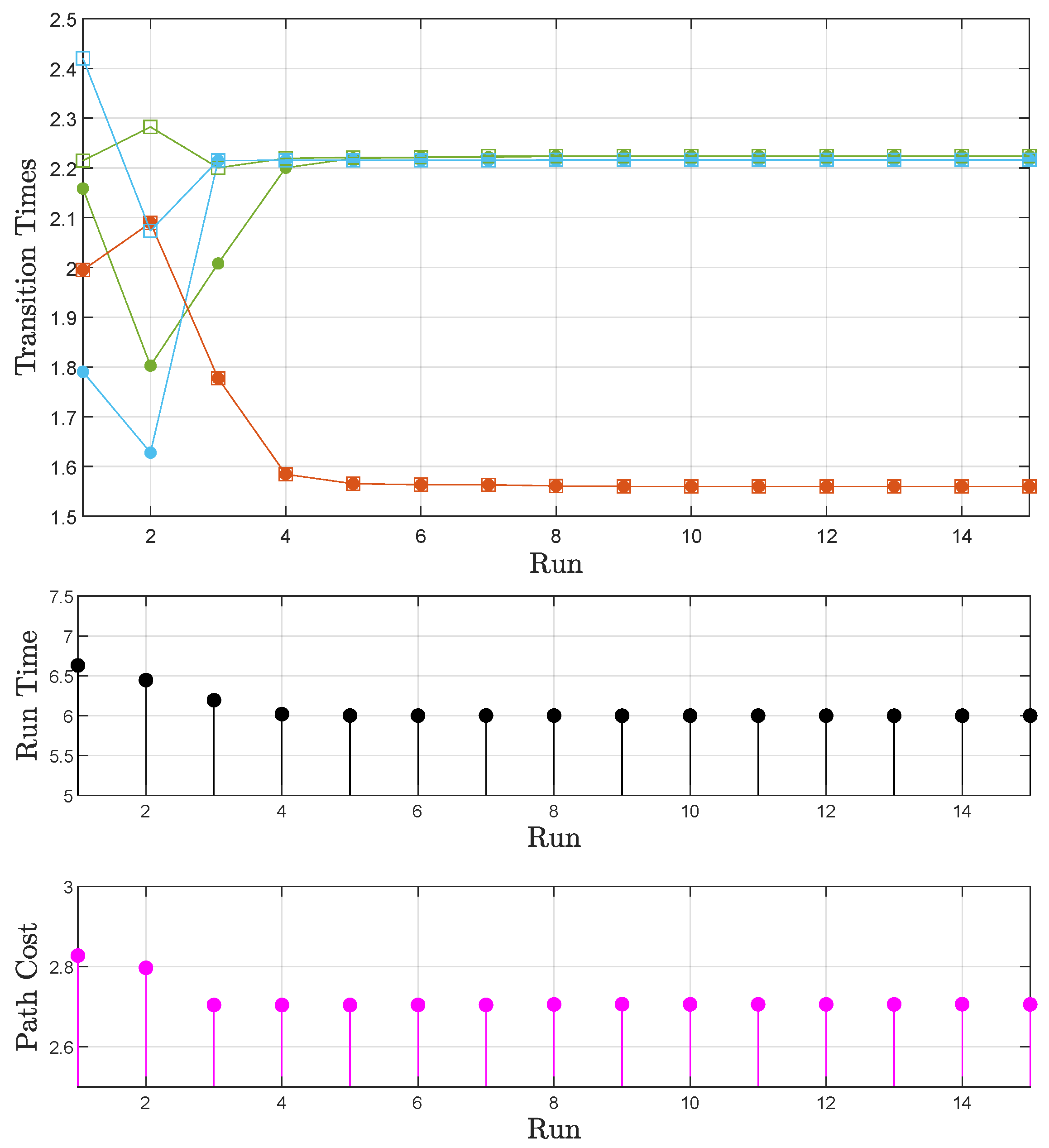
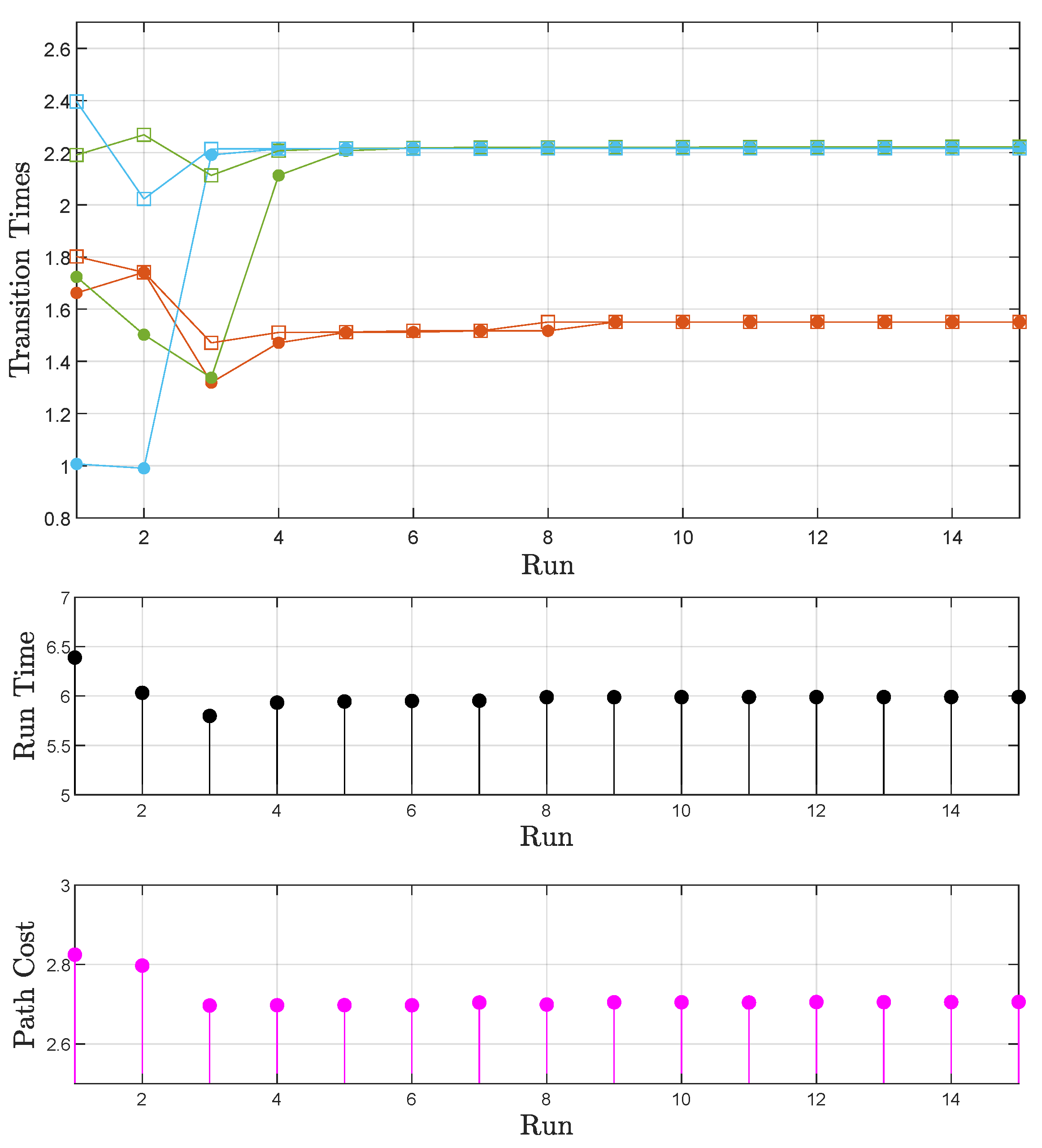
5.3. Examination of the Proposed Scheme
- Case A: The time available for task execution is sufficient. After the reassignment of the transition times through the iterative learning algorithm, the satisfaction of the formula in the time frame is possible.
- Case B: The time available for task execution is not sufficient. Here, the scheme should again be able to find the optimal path while also taking into account the inability to satisfy the formula in the requested time frame.
5.3.1. Sphere World
Sphere World: Case A
Sphere World: Case B
5.3.2. Generalized World
Generalized World: Case A
Generalized World: Case B
6. Experimental Study
- Single-path run: https://youtu.be/S3jF7IsD2U8 (accessed on 6 February 2024)
- Full iterative learning process: https://youtu.be/4uaStlYZing (accessed on 6 February 2024)
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MTL | Metric Temporal Logic |
| MITL | Metric Interval Temporal Logic |
| TBA | Timed Büchi Automaton |
| APC | Adaptive Performance Control |
| Set of real numbers | |
| Set of non-negative numbers | |
| Set of positive numbers | |
| Absolute value of a scalar | |
| Spectral (euclidean) norm of a matrix (vector), respectively | |
| Infinity norm | |
| MITL formula | |
| Free space | |
| Points of interest within the free space | |
| Labeling function | |
| Prescribed time interval | |
| Orientation of robot | |
| u | Commanded linear velocity of robot |
| Commanded angular velocity of robot | |
| Nominal linear velocity of robot | |
| Nominal angular velocity of robot | |
| Performance functions regarding the evolution of position and orientation error, respectively | |
| Continuous function vanishing when | |
| Saturation function constraining the vector within a compact set based on the radial distance of from the origin |
References
- Bhatia, A.; Kavraki, L.E.; Vardi, M.Y. Sampling-based motion planning with temporal goals. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 3–7 May 2010; pp. 2689–2696. [Google Scholar]
- Belta, C.; Isler, V.; Pappas, G.J. Discrete abstractions for robot motion planning and control in polygonal environments. IEEE Trans. Robot. 2005, 21, 864–874. [Google Scholar] [CrossRef]
- Fainekos, G.E.; Girard, A.; Kress-Gazit, H.; Pappas, G.J. Temporal logic motion planning for dynamic robots. Automatica 2009, 45, 343–352. [Google Scholar] [CrossRef]
- Kloetzer, M.; Belta, C. Automatic deployment of distributed teams of robots from temporal logic motion specifications. IEEE Trans. Robot. 2009, 26, 48–61. [Google Scholar] [CrossRef]
- Kress-Gazit, H.; Fainekos, G.E.; Pappas, G.J. Temporal-logic-based reactive mission and motion planning. IEEE Trans. Robot. 2009, 25, 1370–1381. [Google Scholar] [CrossRef]
- Loizou, S.G.; Kyriakopoulos, K.J. Automatic synthesis of multi-agent motion tasks based on ltl specifications. In Proceedings of the 2004 43rd IEEE conference on decision and control (CDC)(IEEE Cat. No. 04CH37601), Nassau, Bahamas, 14–17 December 2004; Volume 1, pp. 153–158. [Google Scholar]
- Guo, M.; Johansson, K.H.; Dimarogonas, D.V. Motion and action planning under LTL specifications using navigation functions and action description language. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 240–245. [Google Scholar]
- Bouyer, P.; Laroussinie, F.; Markey, N.; Ouaknine, J.; Worrell, J. Timed temporal logics. In Models, Algorithms, Logics and Tools: Essays Dedicated to Kim Guldstrand Larsen on the Occasion of His 60th Birthday; Springer: Cham, Switzerland, 2017; pp. 211–230. [Google Scholar]
- Verginis, C.K.; Dimarogonas, D.V. Timed abstractions for distributed cooperative manipulation. Auton. Robot. 2018, 42, 781–799. [Google Scholar] [CrossRef]
- Verginis, C.K.; Vrohidis, C.; Bechlioulis, C.P.; Kyriakopoulos, K.J.; Dimarogonas, D.V. Reconfigurable motion planning and control in obstacle cluttered environments under timed temporal tasks. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 951–957. [Google Scholar]
- Faied, M.; Mostafa, A.; Girard, A. Dynamic optimal control of multiple depot vehicle routing problem with metric temporal logic. In Proceedings of the 2009 American Control Conference, St. Louis, MO, USA, 10–12 June 2009; pp. 3268–3273. [Google Scholar]
- Fu, J.; Topcu, U. Computational methods for stochastic control with metric interval temporal logic specifications. In Proceedings of the 2015 54th IEEE Conference on Decision and Control (CDC), Osaka, Japan, 15–18 December 2015; pp. 7440–7447. [Google Scholar]
- Karaman, S.; Frazzoli, E. Vehicle routing problem with metric temporal logic specifications. In Proceedings of the 2008 47th IEEE Conference on Decision and Control, Cancun, Mexico, 9–11 December 2008; pp. 3953–3958. [Google Scholar]
- Edelkamp, S.; Lahijanian, M.; Magazzeni, D.; Plaku, E. Integrating temporal reasoning and sampling-based motion planning for multigoal problems with dynamics and time windows. IEEE Robot. Autom. Lett. 2018, 3, 3473–3480. [Google Scholar] [CrossRef]
- Zhou, Y.; Maity, D.; Baras, J.S. Timed automata approach for motion planning using metric interval temporal logic. In Proceedings of the 2016 European Control Conference (ECC), Aalborg, Denmark, 29 June–1 July 2016; pp. 690–695. [Google Scholar]
- Andersson, S.; Nikou, A.; Dimarogonas, D.V. Control synthesis for multi-agent systems under metric interval temporal logic specifications. IFAC-PapersOnLine 2017, 50, 2397–2402. [Google Scholar] [CrossRef]
- Nikou, A.; Boskos, D.; Tumova, J.; Dimarogonas, D.V. On the timed temporal logic planning of coupled multi-agent systems. Automatica 2018, 97, 339–345. [Google Scholar] [CrossRef]
- Verginis, C.K.; Dimarogonas, D.V. Distributed cooperative manipulation under timed temporal specifications. In Proceedings of the 2017 American Control Conference (ACC), Seattle, WA, USA, 24–26 May 2017; pp. 1358–1363. [Google Scholar]
- Wang, W.; Schuppe, G.; Tumova, J. Decentralized Multi-agent Coordination under MITL Specifications and Communication Constraints. In Proceedings of the 2023 31st Mediterranean Conference on Control and Automation (MED), Limassol, Cyprus, 26–29 June 2023; pp. 842–849. [Google Scholar]
- Hustiu, S.; Dimarogonas, D.; Mahulea, C.; Kloetzer, M. Multi-robot Motion Planning under MITL Specifications based on Time Petri Nets. In Proceedings of the 2023 European Control Conference (ECC), Bucharest, Romania, 13–16 June 2023. [Google Scholar]
- Gol, E.A.; Belta, C. Time-constrained temporal logic control of multi-affine systems. Nonlinear Anal. Hybrid Syst. 2013, 10, 21–33. [Google Scholar] [CrossRef]
- He, K.; Lahijanian, M.; Kavraki, L.E.; Vardi, M.Y. Towards manipulation planning with temporal logic specifications. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 346–352. [Google Scholar]
- Barbosa, F.S.; Lindemann, L.; Dimarogonas, D.V.; Tumova, J. Integrated Motion Planning and Control Under Metric Interval Temporal Logic Specifications. In Proceedings of the 2019 18th European Control Conference (ECC), Naples, Italy, 25–28 June 2019; pp. 2042–2049. [Google Scholar]
- Seong, H.; Lee, K.; Cho, K. Reactive Planner Synthesis Under Temporal Logic Specifications. IEEE Access 2024, 12, 13260–13276. [Google Scholar] [CrossRef]
- Huang, Z.; Lan, W.; Yu, X. A Formal Control Framework of Autonomous Vehicle for Signal Temporal Logic Tasks and Obstacle Avoidance. IEEE Trans. Intell. Veh. 2024, 9, 1930–1940. [Google Scholar] [CrossRef]
- Yu, X.; Yin, X.; Lindemann, L. Efficient STL Control Synthesis Under Asynchronous Temporal Robustness Constraints. In Proceedings of the 2023 62nd IEEE Conference on Decision and Control (CDC), Singapore, 13–15 December 2023; pp. 6847–6854. [Google Scholar]
- Li, S.; Park, D.; Sung, Y.; Shah, J.; Roy, N. Reactive Task and Motion Planning under Temporal Logic Specifications. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 9228–9234. [Google Scholar]
- Fotiadis, F.; Verginis, C.K.; Vamvoudakis, K.G.; Topcu, U. Assured learning-based optimal control subject to timed temporal logic constraints. In Proceedings of the 2021 60th IEEE Conference on Decision and Control (CDC), Austin, TX, USA, 14–17 December 2021; pp. 750–756. [Google Scholar]
- Bonnah, E.; Nguyen, L.; Hoque, K. Motion Planning Using Hyperproperties for Time Window Temporal Logic. IEEE Robot. Autom. Lett. 2023, 8, 4386–4393. [Google Scholar] [CrossRef]
- Vrohidis, C.; Vlantis, P.; Bechlioulis, C.P.; Kyriakopoulos, K.J. Prescribed time scale robot navigation. IEEE Robot. Autom. Lett. 2018, 3, 1191–1198. [Google Scholar] [CrossRef]
- Trakas, P.S.; Bechlioulis, C.P. Approximation-free Adaptive Prescribed Performance Control for Unknown SISO Nonlinear Systems with Input Saturation. In Proceedings of the 2022 IEEE 61st Conference on Decision and Control (CDC), Cancun, Mexico, 6–9 December 2022; pp. 4351–4356. [Google Scholar]
- Alur, R.; Dill, D.L. A theory of timed automata. Theor. Comput. Sci. 1994, 126, 183–235. [Google Scholar] [CrossRef]
- Bouyer, P.; Markey, N.; Ouaknine, J.; Worrell, J. The cost of punctuality. In Proceedings of the 22nd Annual IEEE Symposium on Logic in Computer Science (LICS 2007), Wroclaw, Poland, 10–14 July 2007; pp. 109–120. [Google Scholar]
- D’Souza, D.; Prabhakar, P. On the expressiveness of MTL in the pointwise and continuous semantics. Int. J. Softw. Tools Technol. Transf. 2007, 9, 1–4. [Google Scholar] [CrossRef]
- Ouaknine, J.; Worrell, J. On the decidability of metric temporal logic. In Proceedings of the 20th Annual IEEE Symposium on Logic in Computer Science (LICS’05), Chicago, IL, USA, 26–29 June 2005; IEEE: Piscataway, NJ, USA, 2005; pp. 188–197. [Google Scholar]
- Chen, X.; Jia, Y.; Matsuno, F. Tracking Control for Differential-Drive Mobile Robots With Diamond-Shaped Input Constraints. IEEE Trans. Control Syst. Technol. 2014, 22, 1999–2006. [Google Scholar] [CrossRef]
- Loizou, S.G. The navigation transformation. IEEE Trans. Robot. 2017, 33, 1516–1523. [Google Scholar] [CrossRef]
- Vlantis, P. Distributed Cooperation of Multiple Robots under Operational Constraints via Lean Communication. Ph.D. Thesis, National Technical University of Athens, Athens, Greece, 2020. [Google Scholar]
- Brihaye, T.; Geeraerts, G.; Ho, H.M.; Monmege, B. Mighty L: A Compositional Translation from MITL to Timed Automata. In Proceedings of the Computer Aided Verification: 29th International Conference, CAV 2017, Heidelberg, Germany, 24–28 July 2017; Proceedings, Part I 30. Springer: Cham, Switzerland, 2017; pp. 421–440. [Google Scholar]
- Baier, C.; Katoen, J.P. Principles of Model Checking; MIT Press: Cambridge, MA, USA, 2008. [Google Scholar]
- Grisetti, G.; Stachniss, C.; Burgard, W. Improving grid-based slam with rao-blackwellized particle filters by adaptive proposals and selective resampling. In Proceedings of the 2005 IEEE International Conference on Robotics and Automation, Barcelona, Spain, 18–22 April 2005; pp. 2432–2437. [Google Scholar]
- Grisetti, G.; Stachniss, C.; Burgard, W. Improved techniques for grid mapping with rao-blackwellized particle filters. IEEE Trans. Robot. 2007, 23, 34–46. [Google Scholar] [CrossRef]
- Dellaert, F.; Fox, D.; Burgard, W.; Thrun, S. Monte carlo localization for mobile robots. In Proceedings of the 1999 IEEE International Conference on Robotics and Automation (Cat. No. 99CH36288C), Detroit, MI, USA, 10–15 May 1999; Volume 2, pp. 1322–1328. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Environment | Transition Time | Transition Distance |
|---|---|---|
| Static Obstacle Environment | tu | du |
| Dynamic Obstacle Environment | tu | du |
| Path Planner | Transition Time | Transition Distance |
|---|---|---|
| (Time Units (tu)) | (Distance Units (du)) | |
| Proposed Motion Controller | tu | du |
| RRT | tu | du |
| PRM | tu | du |
| BiRRT | tu | du |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tolis, F.C.; Trakas, P.S.; Blounas, T.-F.; Verginis, C.K.; Bechlioulis, C.P. Learning to Execute Timed-Temporal-Logic Navigation Tasks under Input Constraints in Obstacle-Cluttered Environments. Robotics 2024, 13, 65. https://0-doi-org.brum.beds.ac.uk/10.3390/robotics13050065
Tolis FC, Trakas PS, Blounas T-F, Verginis CK, Bechlioulis CP. Learning to Execute Timed-Temporal-Logic Navigation Tasks under Input Constraints in Obstacle-Cluttered Environments. Robotics. 2024; 13(5):65. https://0-doi-org.brum.beds.ac.uk/10.3390/robotics13050065
Chicago/Turabian StyleTolis, Fotios C., Panagiotis S. Trakas, Taxiarchis-Foivos Blounas, Christos K. Verginis, and Charalampos P. Bechlioulis. 2024. "Learning to Execute Timed-Temporal-Logic Navigation Tasks under Input Constraints in Obstacle-Cluttered Environments" Robotics 13, no. 5: 65. https://0-doi-org.brum.beds.ac.uk/10.3390/robotics13050065