
Deep Learning-Driven Public Opinion Analysis on the Weibo Topic about AI Art
School of Electronic and Electrical Engineering, Shanghai University of Engineering Science, Shanghai 201620, China
*
Author to whom correspondence should be addressed.
Appl. Sci. 2024, 14(9), 3674; https://0-doi-org.brum.beds.ac.uk/10.3390/app14093674
Submission received: 11 March 2024
/
Revised: 22 April 2024
/
Accepted: 23 April 2024
/
Published: 25 April 2024
(This article belongs to the Section Computing and Artificial Intelligence)
Abstract
:Featured Application
Public Opinion Analysis.
Abstract
The emergence of AI Art has ignited extensive debates on social media platforms. Various online communities have expressed their opinions on different facets of AI Art and participated in discussions with other users, leading to the generation of a substantial volume of data. Analyzing these data can provide useful insights into the public’s opinions on AI Art, enable the investigation of the origins of conflicts in online debates, and contribute to the sustainable development of AI Art. This paper presents a deep learning-driven framework for analyzing the characteristics of public opinion on the Weibo topic of AI Art. To classify the sentiments users expressed in Weibo posts, the linguistic feature-enhanced pre-training model (LERT) was employed to improve text representation via the fusion of syntactic features, followed by a bidirectional Simple Recurrent Unit (SRU) embedded with a soft attention module (BiSRU++) for capturing the long-range dependencies in text features, thus improving the sentiment classification performance. Furthermore, a text clustering analysis was performed across sentiments to capture the nuanced opinions expressed by Weibo users, hence providing useful insights about different online communities. The results indicate that the proposed sentiment analysis model outperforms common baseline models in terms of classification metrics and time efficiency, and the clustering analysis has provided valuable insights for in-depth analyses of AI Art.
1. Introduction
With the release of Midjourney and the open sourcing of the Stable Diffusion model [1] in 2022, “AI Art” has become a hot topic on major social media platforms worldwide. AI Art refers to the process of generating and creating images using artificial intelligence algorithms and deep neural network models. Neural network models like the Convolutional Neural Network (CNN), variational autoencoder (VAE), and Generative Adversarial Network (GAN) enable generative models that can comprehend and assimilate abstract features such as painting techniques and styles from existing images, thus facilitating the generation and creation of new images. During its early era, the process of creating images with AI models required a profound comprehension of neural network models for use in network structure design and parameter tuning, making its popularization challenging due to the domain-specific knowledge it demanded. With the advancement of computer vision and natural language processing, models have become capable of acquiring image features at low cost, while neural network structures like the Transformer [2] have improved the understanding of intricate semantics, leading to the rapid development of algorithms such as text-to-image and image-to-image, which in turn has led to the widespread adoption of AI-generated art in the public domain. Today, users can utilize the AI painting functions offered by major platforms to generate and create images using prompt keywords or text.
Nevertheless, the advancement of AI Art technology has been met with controversy. The technical intricacies of generative models are not readily comprehensible to the general public, and the limited interpretability during the training process of generative models has also raised skepticism among the public. The utilization of training data may also raise concerns related to legal issues such as copyright, leading to extensive debates on social media platforms such as X and Weibo. As an emerging technology, the benign development of AI Art depends on the widespread dissemination and comprehension of technical details among the general populace. It also necessitates clarification regarding the diverse areas of interest associated with the technology, so as to effectively address the doubts and concerns of the public. Analyzing public opinion regarding the topic of AI Art on social media platforms can provide useful insights into the various attitudes towards AI Art expressed by different online communities, and shed light on the specific technological aspects that concern the public, thereby supporting the formulation of pertinent laws and regulations by relevant authorities, which themselves hold significant practical implications.
For public opinion analysis of trending topics on social media platforms, sentiment analysis can be utilized to investigate the sentiments of the general public, aiding in the comprehension of users’ opinions, and thereby providing useful insights for further work. In the early era, lexicon-based methods were applied to classifying text sentiments using rule-based methods. On the topic of dementia, Kong et al. [3] collected Weibo posts from 2011 to 2021, and utilized the emotion ontology dictionary provided by DLUT to explore users’ discourse and sentiment towards dementia, offering a foundation for decision-making to authorities considering the growing dementia population in China. Shi et al. [4] studied the Weibo posts created during the outbreak of COVID-19 in early 2020, and combined LDA with lexicon-based sentiment analysis to discuss the evolution process of the public’s concerns, providing useful insights for public health institutions regarding public opinion. To study public opinion related to COVID-19 vaccination, Kwok et al. [5] utilized LDA and lexicon-based sentiment analysis to provide insights into the public’s attitudes from detailed topics and sentiments separately.
Different from lexicon-based methods, machine learning-based methods involve extracting text features and designing classifiers. To examine the antivaccine topic on X, Taeb et al. [6] utilized the Naïve Bayes algorithm for sentiment analysis, followed by topic modeling using LDA. Their findings provide feedback on people’s attitudes and opinions on the COVID-19 vaccine for policymakers. Adamu et al. [7] analyzed tweets discussing the distribution of palliatives by the Nigerian government during COVID-19. They used the SVM classifier to categorize tweets into fine-grained sentiments, and a word cloud was utilized to provide a comprehensive view of people’s attitudes, providing public opinion references to the authorities for the revision and promotion of related policies. To explore the public’s perception of the utilization of ICT in government operations, Risal et al. [8] utilized Naïve Bayes to conduct sentiment analysis of related tweets, followed by topic modeling using LDA. Their results provide useful insights into the usage and development of e-government.
With the development of deep learning technologies, deep neural networks and pre-training models have been utilized to enhance the performance of sentiment analysis models. He et al. [9] collected college students’ opinions from multiple Chinese social platforms and constructed a CNN-based sentiment classification network to conduct sentiment analysis on trending topics discussed by students. They summarized trending discussions on different platforms manually, aiming to help university administrators inform decisions related to these trending topics. El Barachi et al. [10] studied tweets on the topic of climate change, and constructed a framework for analyzing public opinions combining both sentiment analysis and metadata analysis, thereby providing a correlation analysis between the two. Lyu et al. [11] utilized Weibo posts during the COVID-19 outbreak in early 2020. They conducted sentiment analysis using the ERNIE pre-training model and developed a visualization system, offering public health departments a tool for tracking the evolution of public opinion. Focusing on the topic of ChatGPT, Su and Kabala [12] conducted sentiment analysis using multiple pre-training models, followed by a topic classifier to provide a comprehensive view of the public’s sentiments towards ChatGPT.
With the emergence of AI Art technology, there is a growing interest in analyzing the impact of the technology, as well as the public’s attitudes towards it. In ref. [13], the authors analyze the impact of AI Art on artists. They collected comments from various artists on AI Art technology and argued that AI Art needs to be regulated for its development. In ref. [14], the authors collected literature related to generative AI and discussed the potential ethical implications of AI Art. In ref. [15], the authors studied tweets related to generative AI models. By utilizing topic modeling and sentiment analysis, a comparison between occupations and the topic analysis was conducted, offering insights for comprehending the varying attitudes of different occupations. In ref. [16], the authors conducted surveys to interview the general public and performed an empirical analysis to examine the public’s attitude towards AI Art, arguing that it is a double-edged sword.
Through the analysis of related works, sentiment analysis is frequently integrated with topic analysis; however, the results of these analyses are typically reported independently. Aiming to enhance the result of sentiment analysis and provide a more comprehensive view of public opinion, this paper integrates text sentiment analysis with text clustering analysis to develop a framework for analyzing public opinion on the Weibo topic related to AI Art. The contributions of this work are outlined as follows:
- A public opinion analysis was conducted on the Weibo platform with the aim of acquiring Weibo users’ opinions about AI Art. As stated above, the current research on public opinions about AI Art primarily focuses on English-based social media platforms like X and Reddit, with a noticeable absence of analysis on Chinese social media platforms. Therefore, this paper constructed a public opinion analysis framework based on text sentiment analysis and text clustering analysis, with the aim of facilitating the detailed examination of Weibo users’ opinions regarding AI Art and its application in various fields.
- A sentiment analysis model, LERT_BiSRU++, was developed. By incorporating linguistic features of Part of Speech Tagging, Named Entity Recognition, and Dependency Parsing in the pre-training phase, LERT achieves a better representation of Weibo texts compared to traditional word embedding models such as Word2vec. To capture the long-distance dependencies in textual data, the attention-embedded bidirectional Simple Recurrent Unit, BiSRU++, was employed, thereby improving the classification accuracy and time efficiency of the model.
- A text clustering analysis was conducted to enhance the sentiment analysis procedure. To investigate the nuanced opinions revealed in the sentiment analysis results, this study utilizes a text clustering analysis that leverages the LERT model and autoencoders for text representation and dimension reduction, and subsequently applies K-means clustering algorithms to generate clusters. For the detailed opinion extraction, the C-TF-IDF algorithm was employed to extract keywords from each cluster, thus facilitating a fine-grained representation of opinions with both positive and negative sentiments. By integrating sentiment analysis with clustering analysis, the interpretability of results in public opinion analysis has been improved, offering valuable insights for the advancement of AI Art technologies.
The rest of this article is organized as follows. Section 2 illustrates the overall architecture of the proposed public opinion analysis method, together with the datasets’ description and experimental design. Section 3 provides the results of experiments, followed by detailed discussions of experimental results and public opinion analysis. Finally, a brief conclusion is drawn in Section 4.
2. Materials and Methods
Focusing on the “AI Art” topic on Weibo, this paper constructed a public opinion analysis framework consisting of data collection, text preprocessing, sentiment analysis, and cluster analysis. The overall structure is depicted in Figure 1.
2.1. LERT_BiSRU++ Sentiment Analysis Model
To examine the emotional tendencies of Weibo posts within the AI Art topic, the LERT_BiSRU++ sentiment analysis model was constructed. Considering the low density and informal nature of Weibo short texts, the linguistic feature-enhanced pre-training model, LERT, was employed to enhance the efficacy of text representation. To capture the long-distance dependency in Weibo posts, the BiSRU++ module was utilized for improving both classification metrics and time efficiency. The proposed model is described in Figure 2.
2.1.1. LERT
The first step in calculating the semantics expressed by texts is text representation. By transforming the unstructured texts into vectors, text representation facilitates the computation of text, enabling the analysis of text semantics. Based on large corpora, a Masked Language Model (MLM), and a Transformer network, BERT has achieved bidirectional contextual text feature extraction and dynamic text semantic representation through the tokenization of the text. In comparison to the fixed-length contextual windows used by Word2vec, BERT demonstrates superior capabilities in capturing the generic semantic features of the pre-training corpora. However, as the complexity of downstream tasks increases, the generic text representation produced by BERT may encounter challenges in capturing the deep semantic features that exist within the complex corpora used in downstream tasks, which could potentially result in a decline in the performance of deep learning models.
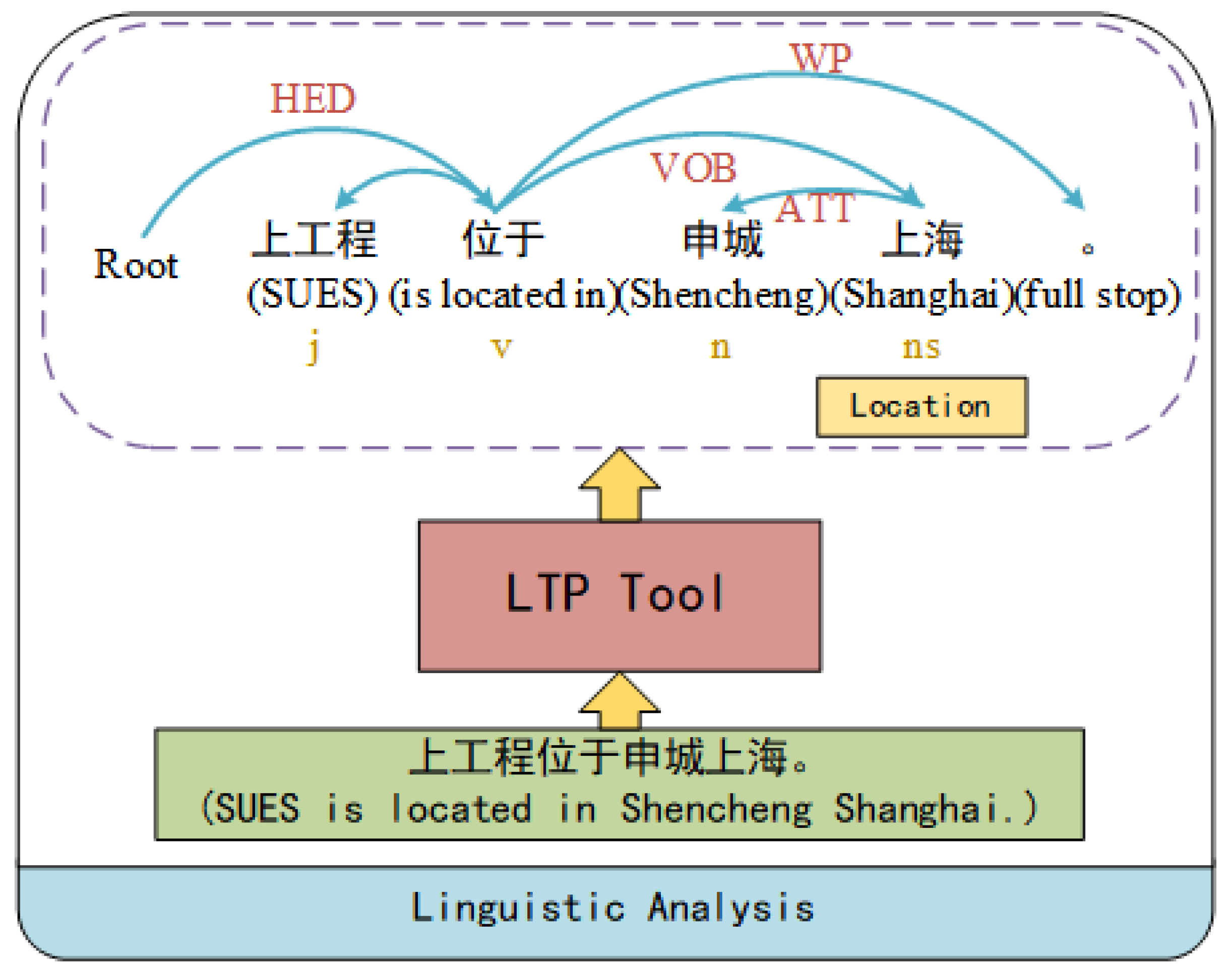
The learning process of BERT primarily involves the MLM, which focuses on acquiring knowledge of dependency relationships, combinations, and semantic associations among the input text tokens. Through extensive training on large-scale corpora, BERT can acquire an understanding of certain grammatical principles. This process does not explicitly incorporate grammatical knowledge, which can be useful in enhancing the extraction of deep text features when facing a complex corpus. Based on this concept, the LERT model [17] incorporates three natural language processing tasks—Part-Of-Speech Tagging (POS), Named Entity Recognition (NER), and Dependency Parsing (DEP)—to enrich the pre-training corpora. This procedure is achieved by using the LTP tool [18], as illustrated in Figure 3.
For the input sentence “SUES is located in Shencheng Shanghai”, the word segmentation tool first segments it into four words: “SUES”, “is located in”, “Shencheng”, “Shanghai”. Then, the POS task identifies the part of speech for each word and annotates them accordingly (in Figure 2, the gold letter represents the POS labels for each word). Subsequently, the NER task involves identifying entities within a given text (in Figure 2, the word “Shanghai” is recognized as a location). Finally, the DEP task integrates the results of the above two tasks, establishing the syntactic connections between individual words in the sentence (in Figure 2, relationships are presented in blue curves and capitalized red letters). Through this process, LERT augments pre-training corpora by incorporating linguistic features, thereby creating weakly supervised data.
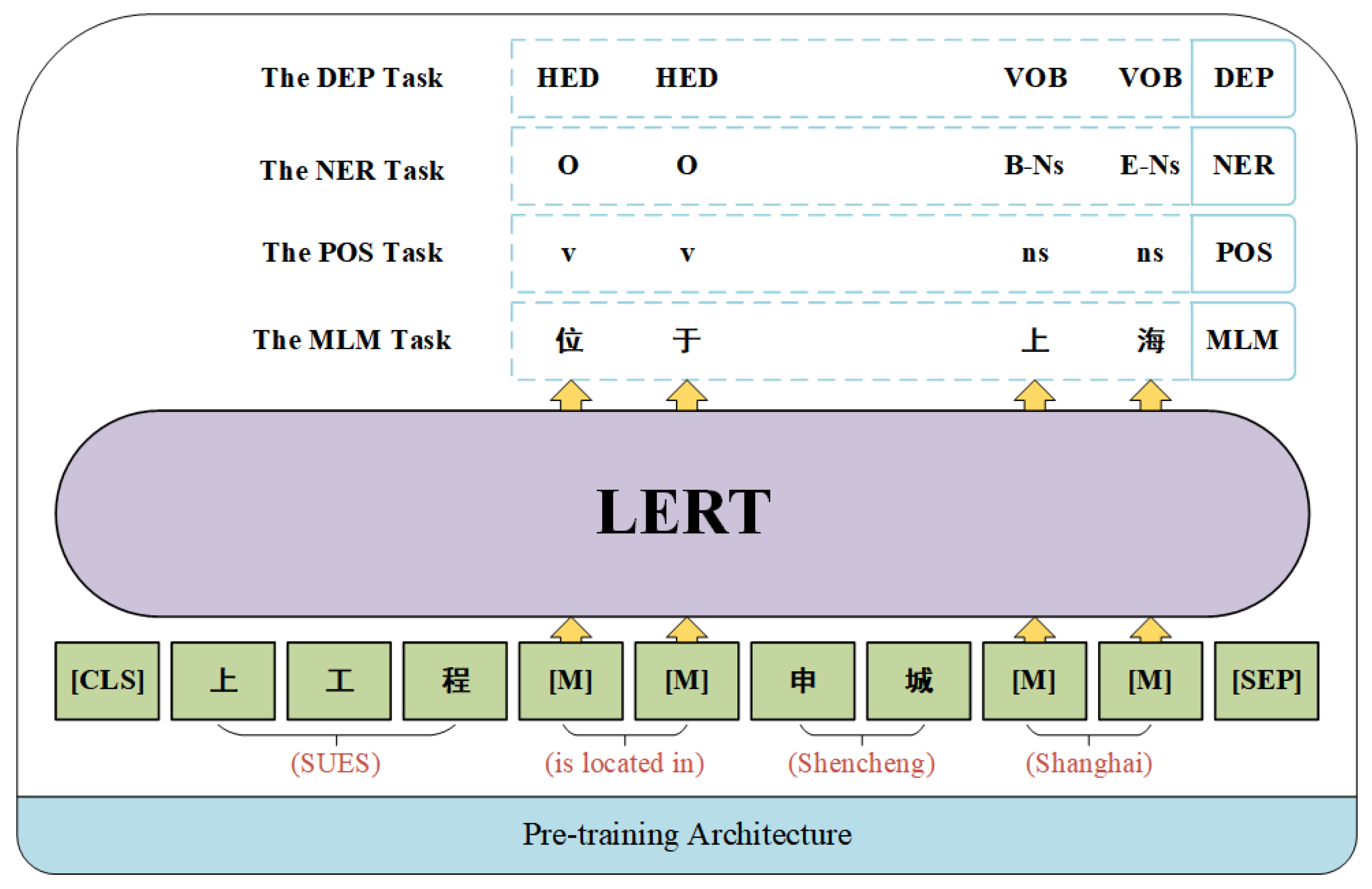
To learn the linguistic features in pre-training corpora, LERT enhances the BERT model via multi-task learning, as illustrated in Figure 4. LERT adopts the MLM task from BERT and integrates the linguistic features into the pre-training phase to enable the model to recognize these linguistic labels explicitly.
For an input sequence of length , BERT encodes it into a feature representation of dimension , with the final hidden state denoted as . The MLM masks characters (in Figure 4, the words “is located in” and “Shanghai” are masked) within the input sequence, and the final hidden state of the masked segment is noted as . For the pooled output, the hidden state is processed through a fully connected layer (Feed Forward Network, FFN) and regularization to generate a probability vector for multi-class assignments in the vocabulary of the whole corpora, as depicted below.
The prediction of the masked word can be viewed as a multi-class classification task within the vocabulary of size in the corpora. The classifier employs the softmax function to generate the probability vector for the masking position , as depicted below.
Based on the above equations, BERT uses the Cross-Entropy function to optimize the training process, producing the overall loss function of the MLM task as below.
To incorporate the linguistic features into the pre-training process, LERT uses fully connected layers to map the prediction task of linguistic labels to the final output. This process is depicted in Equation (4).
In Equation (4), is the character of the location in the input sequence, stands for one of three NLP tasks, denotes the number of linguistic labels for each task. Similar to the MLM task, LERT optimizes the learning process using the Cross-Entropy function, thereby producing the loss function of LERT as below.
To explore the impacts of different linguistic tasks during the training process, LERT implements a scheduled learning rate for each task during the pre-training phase by controlling the training steps of each task. Based on the relationship between POS, NER, and DEP, LERT posits the contributions of three NLP tasks as , and, setting the by the same rate, produces the loss function as below.
Through the above procedure, LERT leverages the linguistic features of three NLP tasks, enabling the model to acquire grammatical knowledge in pre-training corpora through multi-task learning, and enhances the model by improving its ability to understand and represent complex semantics.
2.1.2. SRU++
In specific downstream tasks, the corpus used may exhibit distinctions from the corpora used in the pre-training stage. Additionally, semantic features related to emotional tendencies might be present in long-range dependencies throughout the text, which can be challenging for pre-trained models to capture. To tackle these issues, RNN architectures are used to capture long-range dependencies.
RNN utilizes the output from the previous time step combined with the input of the current time step to transmit dependencies, allowing the propagation of long-range information throughout the input sequence. To mitigate issues such as gradient vanishing and exploding, the LSTM model incorporates gate structures to selectively filter out both the output of the previous time step and the input of the current time step, enhancing the information transmission process and reducing the occurrence of gradient vanishing and exploding. However, due to its network structures, the LSTM model depends on having access to all information from the previous time step, exhibiting a high degree of seriality. Consequently, this can result in relatively low computational efficiency during both the training and inference processes when facing large amounts of data.
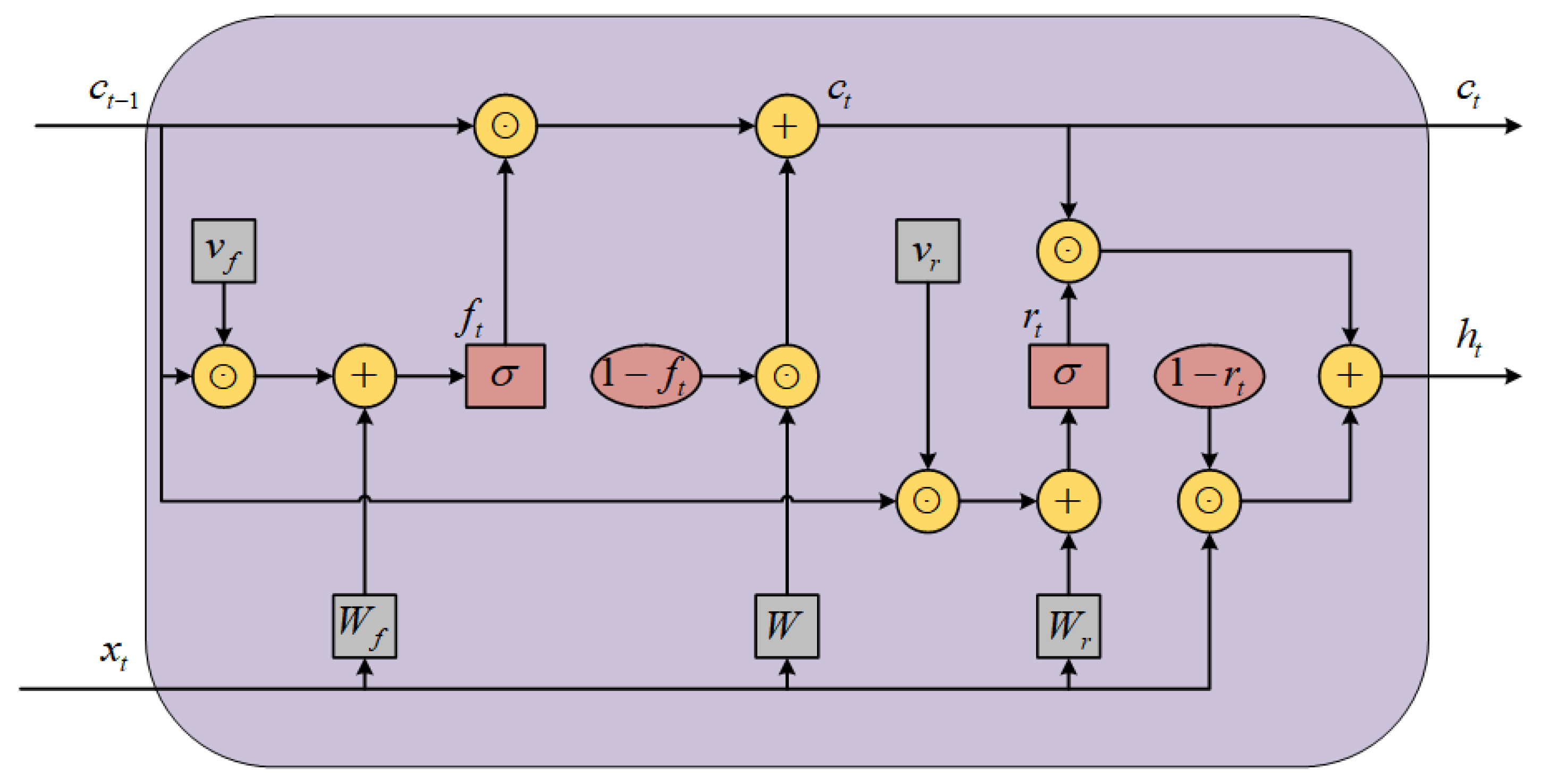
To tackle the above issues, an SRU [19] enhances the calculation process of the gate structures to improve computational efficiency in a parallelized way, which is achieved by introducing light recurrent units and a highway network. The structure of the SRU is depicted in Figure 5.
In contrast to LSTM, SRU utilizes only the forget gate to compute the current cell status , as illustrated in Equations (7) and (8).
In SRU, the calculation of the forget gate uses a learnable vector to map the cell status of the previous time step, , into the calculation process, which enables the SRU to calculate and correlated to the known dimension of input data, achieving the parallelization of computation. Moreover, SRU uses the Hadamard product to replace the original matrix product used in LSTM, combined with the conjugate operation, , to further accelerate the calculation process.
Moreover, SRU introduces the highway network to improve the propagation of gradients when facing deeper network structures. SRU utilizes the reset gate to control the transmission of information, combined with a skip connection to optimize, as depicted in Equations (9) and (10).
Apart from using the conjugate operation to simplify the model parameters, the introduction of used in Equation (10) allows the calculation of the hidden state to use the input of the current time step, which helps with the gradient clipping process during training stages.
To further improve the parallelization, SRU uses batch multiplication to enhance the calculation process of matrices . For a batch input with size and dimension of , the batch multiplication can be described as follows:
For the current time step , , , and stand for the multiplication results of three matrices used in SRU, which change the equation of SRU as follows:
In Equation (10), the process uses a linear transformation to calculate , which can be optimized using self-attention mechanisms. Based on this, SRU++ [20] uses a self-attention module to enhance the feature selection process, as depicted in Figure 6.
For an input sequence with dimension , the self-attention module calculates the matrix as follows:
SRU++ uses two kinds of optimization strategies in the self-attention module. First, the calculation of and uses instead of , which is useful in simplifying the model. Second, the projection trick used in SRU++ projects the input into a lower dimension , which helps reduce the dimension of from to , thereby improving computation efficiency. The introduction of the attention weight matrix is depicted as follows:
In Equation (19), is a learnable matrix, and controls the effect of . By improving the calculation process and introducing self-attention mechanisms, SRU++ achieves better performance compared to LSTM.
2.2. Clustering Analysis
To further investigate in detail the users’ opinions within the positive and negative emotions derived from the sentiment analysis model, a text clustering analysis was employed. Given the high-dimensional text representation produced by LERT, an autoencoder network was employed to conduct nonlinear dimensionality reduction, followed by a K-means clustering analysis producing detailed user opinion clusters. Then, the C-TF-IDF keyword extraction algorithm was utilized for generating keywords for clusters in both positive and negative sentiments, thereby yielding discernible fine-grained users’ opinions related to AI Art. The structure of clustering analysis is depicted in Figure 7.
2.2.1. Autoencoder
The vectors derived from LERT encompass a great amount of nonlinear semantic structural information. In order to enhance the computational efficiency of clustering algorithms, it is imperative to select an appropriate dimensionality reduction technique to decrease the number of features while preserving essential information.
With the advancement of deep learning technology, neural networks are being employed for dimensionality reduction tasks, elevating their abilities to capture nonlinear features. As a type of unsupervised learning neural network structure, autoencoders [21] employ an encoder–decoder architecture to accomplish nonlinear dimensionality reduction. In contrast to PCA, which relies on linear transformations, autoencoders employ nonlinear activation functions to capture the nonlinear patterns within the original features. The structure of an autoencoder is depicted in Figure 8.
As shown in Figure 8, given the input with a dimension of , the encoder compresses it into the hidden state with a dimension of m, followed by the decoder reconstructing the input to . By computing the loss between and , the autoencoder learns the dimensionality reduction process without supervision. The training process of the autoencoder is depicted as follows:
2.2.2. Clustering Analysis and Keyword Extraction
This paper selected K-means for the clustering analysis. Compared to DBSCAN and spectral clustering, K-means benefits from its simple structure and high calculation efficiency, which is important for carrying out public opinion analysis in a timely fashion. Considering that the discussions about AI Art are unevenly distributed over time, K-means++ was utilized to optimize the original K-means clustering algorithm.
The K-means clustering algorithm partitions text data into clusters, where each cluster consists of text sharing similar semantic features, while the semantics expressed in different clusters vary. In order to acquire the detailed opinions expressed by users related to different sentiments, a keyword extraction algorithm is necessary to represent the opinions with a list of keywords for each cluster, thereby enabling the visual presentation of in-depth discussion content.
For the selection of number of clusters , the elbow method is utilized. In the process of determining , with an increase in the number of clusters, the partition of data becomes more refined, leading to higher cohesion within each cluster and a gradual decrease in the sum of squared errors (SSE). The calculation of the SSE is as follows:
In Equation (22), is one of the clusters, is one point in , is the centroid of . When is relatively low, increasing it will enhance the cohesion of the clusters, consequently causing a swift reduction in the SSE; however, when is extensive, additional increments will not yield a significant reduction in the SSE; rather, the result will be clustering overlapping, which can have a negative effect on the accurate identification of detailed topics. By identifying the knee point on the curve of SSE, it is possible to determine an appropriate that balances the accuracy of clustering and the complexity of the model.
The TF-IDF algorithm is a frequently used method for keyword extraction. It operates by computing the product of the word’s frequency and its inverse document frequency to assess the significance of the word within the text. For each cluster, the TF-IDF algorithm can be applied independently to extract keywords. However, this process assumes homogeneity in the word distribution characteristics within each cluster, overlooking the varying significance of words within clusters.
To solve this, the C-TF-IDF keyword extraction algorithm [22] employs the calculation method of TF-IDF, while considering the varying importance of words in different clusters. The calculation process of the C-TF-IDF algorithm is described as follows:
In Equation (23), is any word in the whole corpus, stands for the specific cluster generated from K-means. is the frequency of word in cluster , is the length of words for all clusters, and stands for the number of documents that consist of word . Compared to the individual calculation of each cluster, the C-TF-IDF algorithm assesses the differences in word distribution characteristics between clusters, enabling the better extraction of keywords representing the semantic information of clusters.
2.3. Experiments
2.3.1. Data Collection and Preprocessing
To verify the effectiveness of the proposed sentiment analysis model, we conducted an evaluation using the public Weibo sentiment dataset, weibo2018 [23]. For the collection of data from Weibo posts related to the “AI Art” Weibo topic, a Weibo crawler was employed to gather and categorize Weibo posts between August 2022 and August 2023, using the keyword “AI Art”. A total of 21,200 Weibo posts were collected.
According to the criteria established by weibo2018, the collected Weibo posts were manually labeled into positive and negative sentiment categories. Posts exhibiting positive sentiments demonstrated the endorsement of AI Art and acknowledged the potential advancements in this field, while posts reflecting negative sentiment opposed AI Art and raised worries and questions regarding its progress. For the training procedure of the proposed model, each dataset was divided into a training set and a test set according to the ratio 8:2. The statistical features of the three datasets are described in Table 1.
To further describe the features of the two datasets and explain the labeling metrics of the AI Art topic dataset, samples of positive and negative posts are selected and shown in Table 2.
The public dataset weibo2018 comprises Weibo posts spanning from 2017 to 2018, covering diverse topics, primarily emphasizing text sentiment annotations, and is suitable to evaluate the overall performance of models. The AI Art topic dataset comprises Weibo posts discussing AI Art from August 2022 (the open sourcing of Stable Diffusion) to August 2023, demonstrating a high level of timeliness. The labeling process of the AI Art topic dataset comprehensively analyzes attitudes towards the potential of AI Art, the applications of AI Art, and the overall sentiment expressed in the Weibo posts, with the aim to emphasize the central themes of discussions among Weibo users.
For text data preprocessing, this article first uses regular expression matching to remove the hyperlinks, symbols, and numbers from the original Weibo posts. To segment the texts into word lists, the word tokenizer provided by HanLP [24] is employed, followed by the removal of stop words based on the stop word list.
2.3.2. Experimental Settings
The LERT pre-training model used in the sentiment analysis model was chinese-lert-base, provided by the Joint Laboratory of HIT and iFLYTEK Research (also known as HFL). The parameters of the sentiment analysis model and autoencoder are described in Table 3 and Table 4.
For the text clustering analysis, this paper utilizes the autoencoder network to reduce the dimensionality of the 768-dimensional input generated by LERT to 64 dimensions for clustering analysis.
2.3.3. Evaluation Criteria
To assess the classification efficacy of the proposed sentiment analysis model, accuracy (Acc), precision (P), recall (R), and Score were selected as evaluation metrics. The computation of the four metrics relies on the confusion matrix derived from the predicted results of the model, as outlined in Table 5.
Following the definition above, the calculation of the four evaluation criteria can be described as follows:
Based on the evaluation criteria mentioned above, this paper introduces several baseline sentiment analysis models as follows:
- Word2vec_BiLSTM [10]: This model uses Word2vec to generate text representation in the form of word embeddings with a dimension of 200, followed by a bidirectional LSTM network to capture the long-range dependencies in the input text sequence. The model’s settings are the same as the parameters described in Table 2.
- LERT: Similar to BERT-WWM, the model uses LERT for text representation. The model’s settings are the same as the parameters described in Table 2.
- LERT_BiLSTM: This model utilizes LERT as the embedding layer for the model; the text embedding generated in the last hidden layer was calculated using the bidirectional LSTM network to capture the long-range dependencies in the input text sequence. The model’s settings are the same as the parameters described in Table 2.
- LERT_BiSRU: By changing the LSTM to the SRU network, this model utilizes the SRU network for accelerating the training and inference process. The model’s settings are the same as the parameters described in Table 2.
- LERT_BiSRU++: As the proposed model in this paper, this model improves both time efficiency and classification accuracy by using parallelized calculations and the self-attention module.
To further discuss the influence of attention dimensions settings on the performance of the SRU++ model, this paper conducted the following ablation experiments. By setting the attention dimension in the SRU++ unit as 64, 128, 256, 512, 768, and computing the average time cost for training, a visualization of the effect of different attention dimension settings was conducted and discussed.
3. Results and Discussion
3.1. Sentiment Analysis Model Performance Evaluation
Firstly, the text sentiment analysis model proposed in this paper and the baseline models are evaluated from a quantitative analysis standpoint, using the evaluation metrics described in Section 2.3.3. All the models were trained for 50 epochs, and the best performances were recorded for a benchmark comparison. The results are shown in Table 6 and Table 7.
As the results indicate, the Word2vec_BiLSTM model exhibits worse performance across the evaluation metrics. As a static text representation model, Word2vec is constrained by its shallow network architecture and the limited contextual window, which hinders its ability to effectively address challenges like polysemy and non-standard expressions in Weibo posts, thereby impacting the efficiency of extracting profound semantic features from Weibo posts.
Benefiting from the MLM and bidirectional Transformer architecture, the BERT-WWM model demonstrated better efficacy in text representation than Word2vec. Moreover, the LERT pre-trained model, augmented with linguistic features and multi-task learning, achieved better performance than the BERT-WWM. The integration of linguistic features enhances the model’s capacity to comprehend and depict intricate semantics, thereby improving the performance of sentiment analysis when handling complex corpora.
In comparison with the model utilizing the text representation pooled from the model for classification, the integration of LSTM, SRU, and SRU++ demonstrated additional enhancements across the evaluation metrics. When applied to the Weibo corpus, pre-trained models exhibited limited effectiveness in capturing distinctive expressions and features unique to the Weibo platform. The incorporation of RNNs enhances the model’s ability to emphasize sequential characteristics in Weibo posts. By capturing long-distance dependencies, the model can effectively acquire the emotional semantic features within the text, consequently enhancing the classification accuracy of the model.
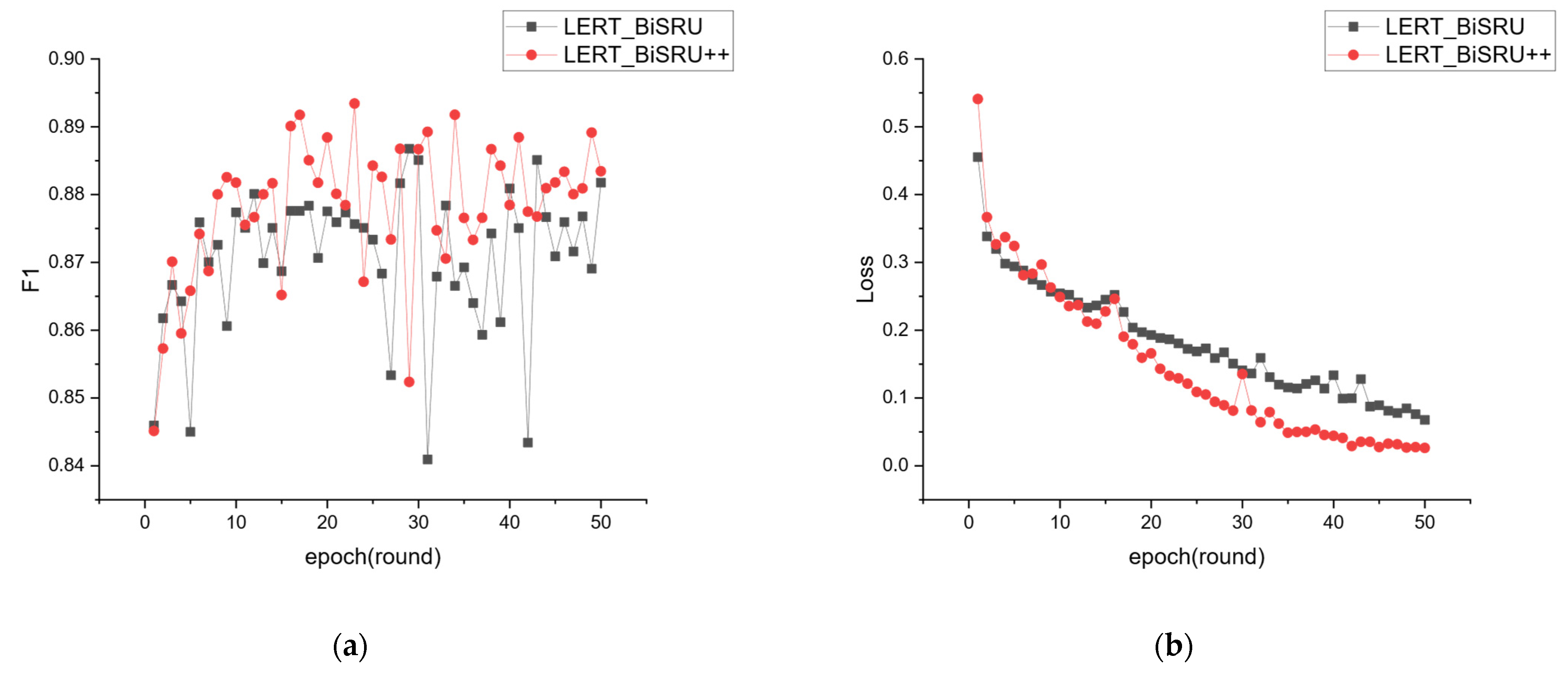
To investigate the influence of the self-attention module embedded in the SRU++ unit, this paper visualizes the variation process of the value and loss value during the training process of LERT_BiSRU and LERT_BiSRU++ on both the weibo2018 dataset and the AI Art Weibo topic dataset, as illustrated in Figure 9 and Figure 10.
As illustrated in Figure 9 and Figure 10, the LERT_BiSRU++ model demonstrated a quicker convergence rate compared to the LERT_BiSRU model during the learning phase, displaying a more consistent and smoother curve in both value and loss value. By incorporating a self-attention module in the batch multiplication process, SRU++ benefits from the feature selection process provided by the self-attention calculation process, enabling the model to identify crucial features in the word embedding provided by the LERT model. Consequently, the LERT_BiSRU++ model achieves a faster learning process and higher classification accuracy.
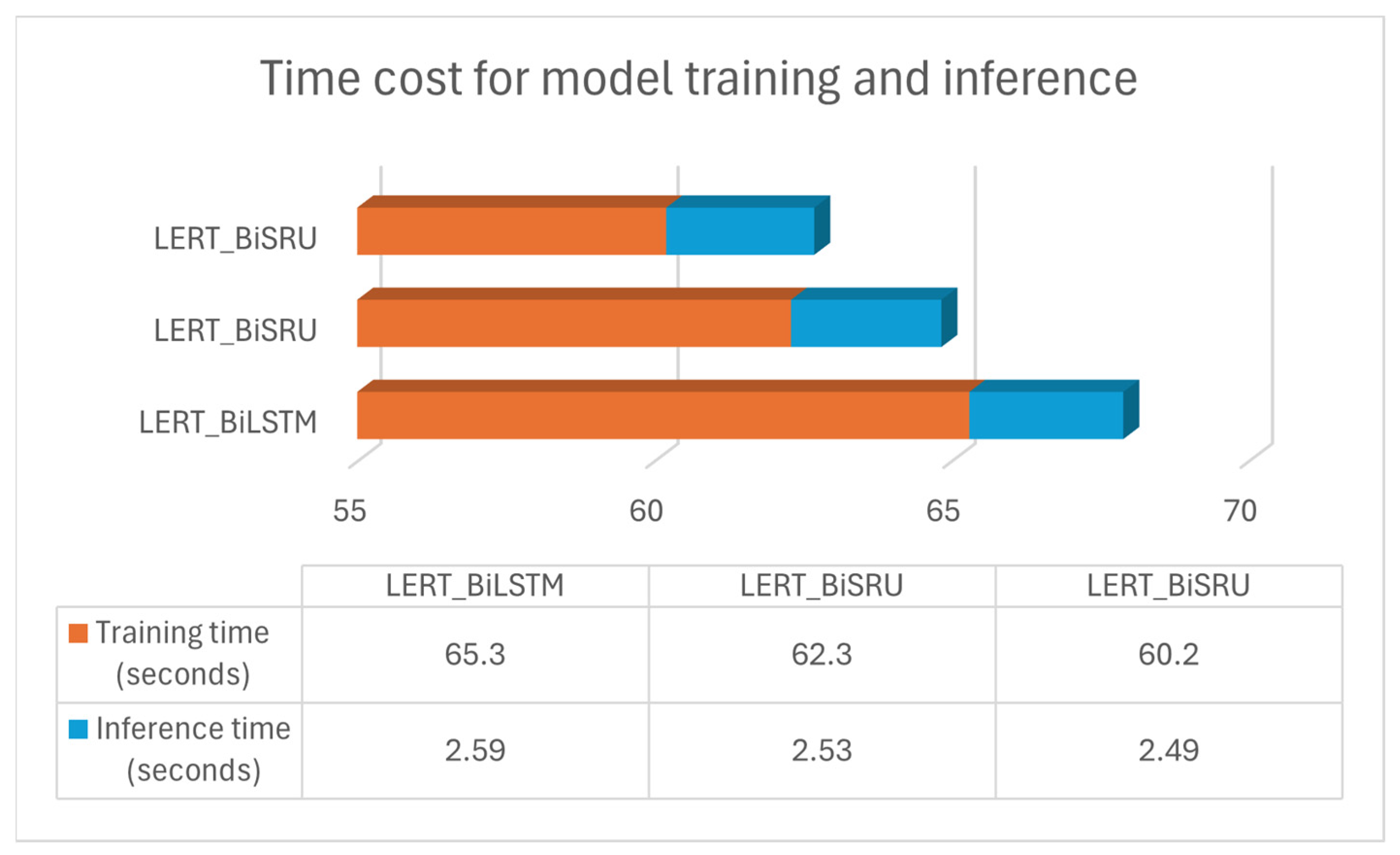
To investigate the acceleration impact of the SRU and SRU++ network, the average times taken for training and inference for the three models on the weibo2018 dataset were computed for visualization. The results are illustrated in Figure 11.
As illustrated in Figure 10, the training and inference processes of LERT_BiSRU and LERT_BiSRU++ cost less time in comparison to LERT_BiLSTM. By leveraging lightweight recurrent units, the SRU and SRU++ units eliminate the reliance on the hidden state from the preceding time step in computations, opting for cell states instead, thereby enabling the parallelization of the calculation process. The incorporation of the Hadamard product also improves the computational efficiency of the model when dealing with high-dimensional inputs. In the SRU++, the employment of the self-attention module slightly increased the training and inference time, but with the projection techniques, the total time cost remained relatively lower than that of the LSTM unit.
For the ablation experiments on the setting of the self-attention dimension, the result is shown in Figure 12.
As illustrated in Figure 12, the setting of the self-attention dimension exhibits a strong correlation with the performance of the model. When the attention dimension ranged from 64 to 256, the model’s performance showed improvement compared to the SRU. The optimal performance was achieved at 384, which is half of the input dimension. When the attention dimension was set to 512 and 768, not only did the model’s performance decrease, but the training time of the model also approached or exceeded that of the model utilizing LSTM. Hence, selecting the suitable attention dimension is crucial for enhancing the performance of the model.
3.2. Public Opinion Analysis Results
To explore the fine-grained opinions expressed by Weibo users under different sentiments, the proposed sentiment analysis model was employed to categorize the sentiment of 21,200 Weibo posts, generating a compilation of positive and negative sentiment posts. The results of the sentiment analysis are depicted in Figure 13.
As shown in Figure 13, the number of Weibo posts showing positive attitudes towards AI Art is 13,567, while the other 7633 Weibo posts show negative attitudes. The advancements of AI Art technology have been applied in various fields, including aiding human creativity and facilitating public participation in artistic endeavors, benefiting the public with easy access to art creation. Meanwhile, the abuse of AI Art also raises public concerns and disapproval of the technology.
To derive detailed opinions with different sentiments, the text clustering analysis method described in Section 2.2 was utilized to generate opinion clusters and extract keyword representations for each cluster. By using the elbow method, the number of clusters was set to six for both positive and negative posts, providing a comprehensive analysis of the detailed aspects of the different opinions, as depicted in Table 8 and Table 9.
As shown in Table 9, the clustering analysis results for positive Weibo posts indicate that the Weibo users holding a positive attitude towards AI Art technology mainly focus on the benefits and potentials of the technology. Cluster 1 describes the process of creating images with the model, followed by cluster 4 depicting the details of the model. In clusters 3 and 5, the users who experienced creating their own images with the tool expressed their emotions, such as “happy”, “pleasant”, “lol”, “funny” and “unreasonable”, indicating that the popularization of AI Art has enabled the public to create their own images with their boundless imagination. For clusters 2 and 6, we see that the emergence of AI Art has caught the attention of companies like Tencent, followed by the launch of various models by many companies. As a result, the stock market is also paying great attention to this emerging technology for its unlimited potential.
In contrast to Table 8, Table 9 provides a comprehensive overview of detailed opinions that convey negative emotions. The fast pace of development of AI Art has aroused many concerns, such as whether human artists and illustrators will be replaced in the future, as described in cluster 1. Based on this, cluster 2 argues that the emotion artists infuse during their creation is essential for a picture or illustration, which does not exist in the image produced by models. In cluster 3, the copyright problem is discussed from the perspective of Weibo users supporting human artists (also known as “teachers”), which reflects the absence of relevant laws, regulations, and oversight about AI Art applications and their products. The fast pace of AI Art also raises concerns among human artists, as the advancement of technology may replace humans in various industries, which might result in their being laid off (depicted in clusters 4 and 5). In cluster 6, the users expressed excessive negative emotions, resulting from the concerns in clusters 1 to 5, which may be harmful to maintaining a harmonious community environment in Weibo.
The clustering results of positive posts indicate that the advancement of AI Art technology allows the public to engage in artistic creation using AI, thus reducing the barriers to entry for participation in art creation. Furthermore, AI Art technology has garnered investments from companies like Tencent, offering assistance in analyzing market trends and drawing increased interest towards AI Art technology. To conclude, the results are beneficial for the advancement of AI Art technology.
On the other hand, the results of clustering analysis on negative posts highlight the limitations of AI Art technology in its current stage. The rapid development of AI Art has sparked apprehensions regarding the future. Furthermore, being an emerging technology, the copyright and intellectual property concerns associated with AI-generated artwork have incited controversy, resulting in the proliferation of highly critical comments on social media platforms. Hence, the advancement of AI Art technology necessitates the dissemination of detailed information about relevant technologies to enhance the public comprehension of it. Additionally, it calls for authorities to enact legislation pertaining to copyright to mitigate the potential misuse of AI Art technology. In light of the polarization of public opinion resulting from the inappropriate use, it is imperative for the authorities not only to penalize those who misuse the technology but also to enhance the oversight of such extreme posts.
4. Conclusions
This study focuses on the analysis of public opinion on the Weibo topic of AI Art. Commencing with text sentiment analysis and text clustering analysis, a deep learning-driven framework was developed to examine users’ nuanced opinions on the topic. For sentiment analysis, the LERT_BiSRU++ sentiment analysis model was developed for the binary classification of Weibo posts related to the topic. The experimental results showed that the proposed model achieved better results in terms of both classification metrics and computational efficiency. To delve deeper into the nuanced opinions expressed by users carrying different sentiments, a text clustering analysis based on an autoencoder network, K-means, and C-TF-IDF keyword extraction was conducted to produce keyword lists representing the detailed opinions expressed by users. The results of the clustering analysis offer valuable data on public opinion that can be used by relevant authorities in the establishment of laws and regulations, along with the healthy development of AI Art.
The work presented in this paper offers an analysis that provides a framework for further research. Firstly, the LERT pre-training model was employed to enhance text representation within the intricate semantic context of Weibo. In topics like AI Art, where timeliness plays a crucial role, novel internet terms and expressions are consistently emerging, and are difficult for pre-trained models to capture. Collecting and integrating this external knowledge into pre-training models has the potential to further improve the performance of sentiment analysis models. Secondly, the K-means clustering algorithm was utilized for clustering analysis, and the results demonstrated the presence of hierarchical relationships among various topics. These hierarchical relationships can be more effectively extracted through clustering algorithms like DBSCAN and spectral clustering. Finally, the emergence of AI Art technology has ignited significant discussions worldwide. Conducting a multi-language analysis can enhance the comprehension of the public’s attitudes towards AI Art, offering a more comprehensive basis for the sustainable development of AI Art technology.
Author Contributions
Conceptualization, W.W.; Software, W.W.; Data curation, R.H.; Writing—original draft, W.W.; Writing—review and editing, W.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Kong, D.; Chen, A.; Zhang, J.; Xiang, X.; Lou, W.V.; Kwok, T.; Wu, B. Public discourse and sentiment toward dementia on Chinese Social Media: Machine Learning analysis of Weibo Posts. J. Med. Internet Res. 2022, 24, e39805. [Google Scholar] [CrossRef] [PubMed]
- Shi, W.-z.; Zeng, F.; Zhang, A.; Tong, C.; Shen, X.; Liu, Z.; Shi, Z. Online public opinion during the first epidemic wave of COVID-19 in China based on Weibo data. Humanit. Soc. Sci. Commun. 2022, 9, 159. [Google Scholar] [CrossRef]
- Kwok, S.W.H.; Vadde, S.K.; Wang, G. Tweet Topics and Sentiments Relating to COVID-19 Vaccination Among Australian Twitter Users: Machine Learning Analysis. J. Med. Internet Res. 2021, 23, e26953. [Google Scholar] [CrossRef] [PubMed]
- Taeb, M.; Chi, H.; Yan, J. Applying Machine Learning to Analyze Anti-Vaccination on Tweets. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021; pp. 4426–4430. [Google Scholar] [CrossRef]
- Adamu, H.; Lutfi, S.L.; Malim, N.H.A.H.; Hassan, R.; Di Vaio, A.; Mohamed, A.S.A. Framing twitter public sentiment on Nigerian government COVID-19 palliatives distribution using machine learning. Sustainability 2021, 13, 3497. [Google Scholar] [CrossRef]
- Risal, A.; Fathahillah, F.; Sulaiman, D. Classification of Sentiment Analysis and Community Opinion Modeling Topics for Application of ICT in Government Operations. Int. J. Environ. Eng. Educ. 2023, 5, 35–44. [Google Scholar] [CrossRef]
- He, M.; Ma, C.; Wang, R. A Data-Driven Approach for University Public Opinion Analysis and Its Applications. Appl. Sci. 2022, 12, 9136. [Google Scholar] [CrossRef]
- El Barachi, M.; AlKhatib, M.; Mathew, S.; Oroumchian, F. A novel sentiment analysis framework for monitoring the evolving public opinion in real-time: Case study on climate change. J. Clean. Prod. 2021, 312, 127820. [Google Scholar] [CrossRef]
- Lyu, X.; Chen, Z.; Wu, D.; Wang, W. Sentiment analysis on Chinese Weibo regarding COVID-19. In Proceedings of the Natural Language Processing and Chinese Computing: 9th CCF International Conference, NLPCC 2020, Zhengzhou, China, 14–18 October 2020; pp. 710–721. [Google Scholar] [CrossRef]
- Su, Y.; Kabala, Z.J. Public Perception of ChatGPT and Transfer Learning for Tweets Sentiment Analysis Using Wolfram Mathematica. Data 2023, 8, 180. [Google Scholar] [CrossRef]
- Jiang, H.H.; Brown, L.; Cheng, J.; Khan, M.; Gupta, A.; Workman, D.; Hanna, A.; Flowers, J.; Gebru, T. AI Art and its Impact on Artists. In Proceedings of the 2023 AAAI/ACM Conference on AI, Ethics, and Society, Montreal, QC, Canada, 8–10 August 2023; pp. 363–374. [Google Scholar] [CrossRef]
- Vyas, B. Ethical Implications of Generative AI in Art and the Media. Int. J. Multidiscip. Res. 2024, 4. [Google Scholar] [CrossRef]
- Miyazaki, K.; Murayama, T.; Uchiba, T.; An, J.; Kwak, H. Public perception of generative AI on Twitter: An empirical study based on occupation and usage. EPJ Data Sci. 2024, 13, 2. [Google Scholar] [CrossRef]
- Brewer, P.R.; Cuddy, L.; Dawson, W.; Stise, R. Artists or art thieves? media use, media messages, and public opinion about artificial intelligence image generators. AI SOCIETY 2024, 1–11. [Google Scholar] [CrossRef]
- Cui, Y.; Che, W.; Wang, S.; Liu, T. Lert: A linguistically-motivated pre-trained language model. arXiv 2022, arXiv:2211.05344. [Google Scholar]
- Che, W.; Feng, Y.; Qin, L.; Liu, T. N-LTP: An open-source neural language technology platform for Chinese. arXiv 2020, arXiv:2009.11616. [Google Scholar]
- Lei, T.; Zhang, Y.; Wang, S.I.; Dai, H.; Artzi, Y. Simple recurrent units for highly parallelizable recurrence. arXiv 2017, arXiv:1709.02755. [Google Scholar]
- Lei, T. When attention meets fast recurrence: Training language models with reduced compute. arXiv 2021, arXiv:2102.12459. [Google Scholar]
- Baldi, P. Autoencoders, unsupervised learning, and deep architectures. In Proceedings of the ICML Workshop on Unsupervised and Transfer Learning, Bellevue, WA, USA, 2 July 2011; pp. 37–49. [Google Scholar]
- Grootendorst, M. BERTopic: Neural topic modeling with a class-based TF-IDF procedure. arXiv 2022, arXiv:2203.05794. [Google Scholar]
- Dataset: Weibo2018. Available online: https://github.com/dengxiuqi/weibo2018 (accessed on 26 September 2018).
- He, H.; Choi, J.D. The stem cell hypothesis: Dilemma behind multi-task learning with transformer encoders. arXiv 2021, arXiv:2109.06939. [Google Scholar]
- Cui, Y.; Che, W.; Liu, T.; Qin, B.; Yang, Z. Pre-training with whole word masking for chinese bert. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 3504–3514. [Google Scholar] [CrossRef]
Figure 1.
The overall structure of the public opinion framework.

Figure 2.
The LERT_BiSRU++ sentiment analysis model’s structure.

Figure 3.
The process of acquiring linguistic labels using the LTP tool.

Figure 4.
The structure of LERT.

Figure 5.
The structure of SRU.

Figure 6.
The structure of SRU++.

Figure 7.
The structure of clustering analysis.

Figure 8.
The structure of the autoencoder.

Figure 9.
(a) The value, (b) the loss value variation process during the training process (weibo2018).
Figure 9.
(a) The value, (b) the loss value variation process during the training process (weibo2018).

Figure 10.
(a) The value, (b) the loss value variation process during the training process (AI Art).
Figure 10.
(a) The value, (b) the loss value variation process during the training process (AI Art).

Figure 11.
Time cost for model training and inference (weibo2018).

Figure 12.
The effect of attention dimension settings on model’s performance (weibo2018).

Figure 13.
The sentiment distribution in the AI Art Weibo topic.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Statistical features of the public datasets.
| Characteristics | Weibo2018 | Topic Dataset |
|---|---|---|
| Average length | 80 | 75 |
| Positive samples | 5842 | 3500 |
| Negative samples | 4658 | 3500 |
Table 2.
Samples of positive and negative posts in two datasets.
| Dataset | Weibo2018 | Topic Dataset |
|---|---|---|
| Positive samples | Suddenly remembered that I have achieved a small goal, 27 June 2017 | I posted two decent AI-generated artworks, getting closer to mastering AI Art. |
| I don’t think this set of pictures looks anything like me, but it’s kind of nice. It has reignited hope in life. | #AI Art, I advise you not to be too far-fetched #I have seen a lot of AI-generated artworks! I think they are very wonderful. | |
| The beauty of yesterday~Spring, cherry blossoms with you. #Viewing cherry blossom in Tongji University# | #Will artists be replaced by AI?# I think with the development of AI technology, it is not impossible for AI to replace humans to some extent in the future. I am actually looking forward to it. | |
| Negative samples | Heartbreak in 2018, questioning from the soul! | AI Art is too disgusting, pure piracy behaviour. |
| Please don’t diss me. It’s not eve summer yet and I’m already as dark as charcoal… Thank you all… | Taking AI-generated artwork to apply for copyright and commercial use, do you not realize that you may be infringing on other’s rights? Truly speechless. | |
| Being tortured by the forced updates of Windows10, having to reinstall the software everytime there is an update. | #Drawers’ club is too insular #If there are a few more AI artist, I will have to change careers |
Table 3.
The parameters of the sentiment analysis model.
| Parameter | Value |
|---|---|
| Batch_size | 64 |
| Learning_rate | |
| Hidden_size | 384 |
| Max_len | 128 |
| Drop_rate | 0.2 |
| SRU++ Attention dim | 384 |
| Epoch | 50 |
| Optimizer | AdamW |
Table 4.
The parameters of the autoencoder.
| Parameter | Value |
|---|---|
| Batch_size | 256 |
| Learning_rate | |
| Hidden_size | 64 |
| Max_len | 128 |
| Epoch | 30 |
| Optimizer | AdamW |
Table 5.
The definition of the confusion matrix.
| Actual Positive | Actual Negative | |
|---|---|---|
| Predicted Positive | TP | FP |
| Predicted Negative | FN | TN |
Table 6.
The experiment results on the weibo2018 dataset.
| Acc | P | R | F1 | |
|---|---|---|---|---|
| Word2vec_BiLSTM | 0.856 | 0.862 | 0.861 | 0.862 |
| BERT-WWM | 0.903 | 0.881 | 0.885 | 0.883 |
| LERT | 0.907 | 0.884 | 0.887 | 0.886 |
| LERT_BiLSTM | 0.922 | 0.907 | 0.911 | 0.909 |
| LERT_BiSRU | 0.918 | 0.905 | 0.903 | 0.904 |
| LERT_BiSRU++ | 0.932 | 0.921 | 0.918 | 0.92 |
Table 7.
The experiment results on the “AI Art” Weibo topic dataset.
| Acc | P | R | F1 | |
|---|---|---|---|---|
| Word2vec_BiLSTM | 0.834 | 0.837 | 0.836 | 0.837 |
| BERT-WWM | 0.855 | 0.855 | 0.853 | 0.855 |
| LERT | 0.862 | 0.861 | 0.859 | 0.860 |
| LERT_BiLSTM | 0.883 | 0.884 | 0.883 | 0.883 |
| LERT_BiSRU | 0.887 | 0.887 | 0.887 | 0.887 |
| LERT_BiSRU++ | 0.893 | 0.893 | 0.894 | 0.893 |
Table 8.
Clustering analysis results for positive Weibo posts.
| No. | Keywords |
|---|---|
| 1 | generate, style, thing, photo, human, function, work, description, create, try, tool |
| 2 | Tencent, art, model, stock price increase, world, way, intelligent, program, success, stock |
| 3 | design, world, technology, bring, create, support, future, program, model, style, good |
| 4 | prompt words, information, hidden, create, art, technology, model, sampling, storage, design, |
| 5 | style, generate, picture, happy, pleasant, try, unreasonable, idea, lol, funny |
| 6 | art, technology, time and space, design, create, future, develop, enable, tool, bring, explore |
Table 9.
Clustering analysis results for negative Weibo posts.
| No. | Keywords |
|---|---|
| 1 | artist, human, substitute, create, problem, technology, generate, auxiliary, tool, art |
| 2 | human, art, artist, create, substitute, emotion, original, copyright, problem, work |
| 3 | teachers, artist, copyright, plagiarism, standard, art, attention, problem, future, company |
| 4 | artist, develop, illustrator, art, process, style, industry, cake, idea, illustration |
| 5 | artist, generator, answer, work, substitute, victim, relationship, robot, problem, innovation |
| 6 | hate, disgraceful, disgusted, strongly hate, excessive, mute, boycott, capital, company, future |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Wan, W.; Huang, R. Deep Learning-Driven Public Opinion Analysis on the Weibo Topic about AI Art. Appl. Sci. 2024, 14, 3674. https://0-doi-org.brum.beds.ac.uk/10.3390/app14093674
AMA Style
Wan W, Huang R. Deep Learning-Driven Public Opinion Analysis on the Weibo Topic about AI Art. Applied Sciences. 2024; 14(9):3674. https://0-doi-org.brum.beds.ac.uk/10.3390/app14093674
Chicago/Turabian StyleWan, Wentong, and Runcai Huang. 2024. "Deep Learning-Driven Public Opinion Analysis on the Weibo Topic about AI Art" Applied Sciences 14, no. 9: 3674. https://0-doi-org.brum.beds.ac.uk/10.3390/app14093674
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.