
An Intelligent Detection and Classification Model Based on Computer Vision for Pavement Cracks in Complicated Scenarios

Abstract
:1. Introduction
2. Materials and Methods
2.1. Dataset Description
2.1.1. Image Data Acquisition
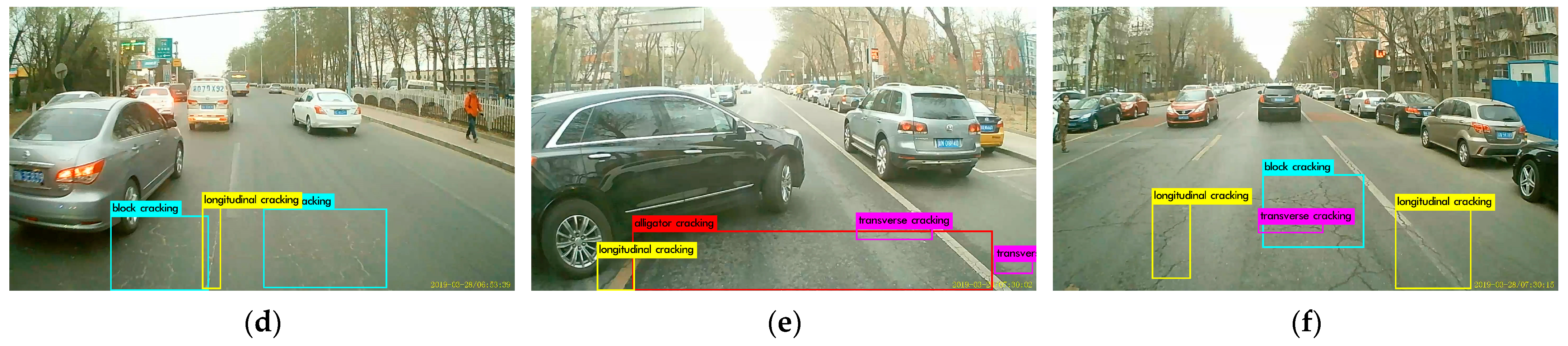
2.1.2. Dataset Introduction
2.1.3. Image Pre-Processing
2.2. Proposed Methodology
2.2.1. YOLOv5 Network
2.2.2. Improvement Methods
- 160 × 160 Detection Layer for Small Targets
- 2.
- Anchor Box Update
- 3.
- Improved Neck Structure Based on Bi-FPN
- 4.
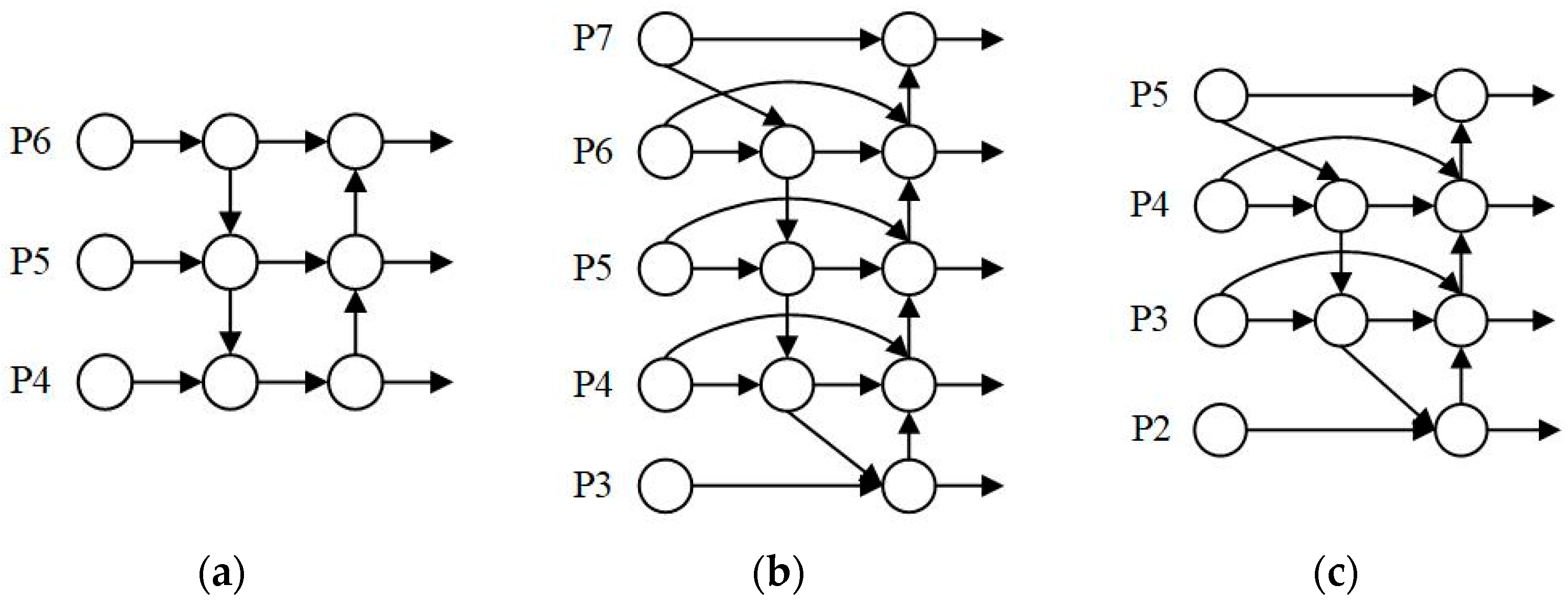
- Improved Cross-Layer Connections
2.2.3. The Overall Architecture of the Proposed Network Based on YOLOv5
3. Experimental Results and Discussion
3.1. Experimental Environment and Settings
3.2. Evaluation Indicators
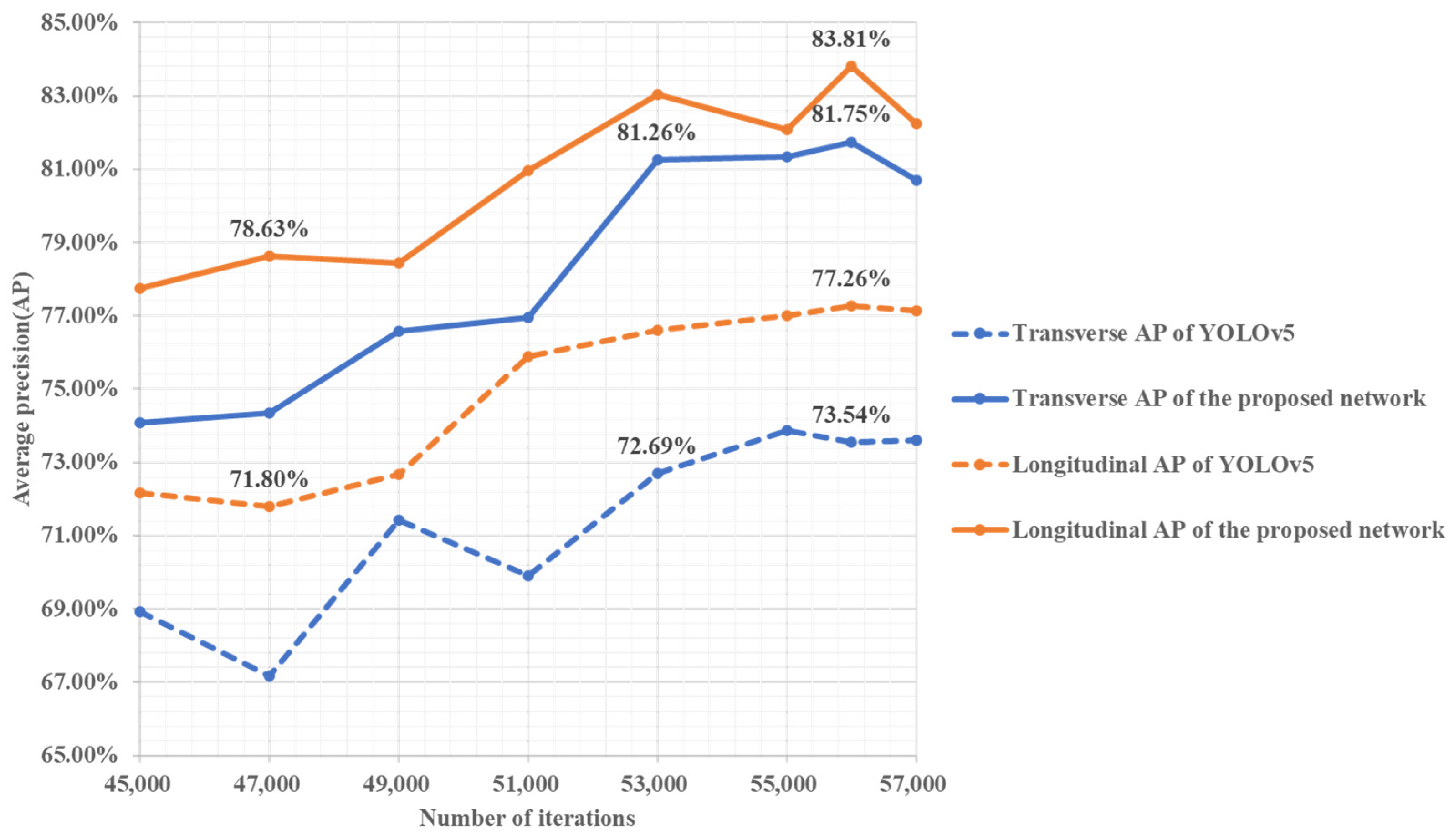
3.3. Experimental Results of the Proposed Crack Detection Model
3.4. Experimental Results of Evaluation Indicators in Engineering
3.5. Validation Test of the Proposed Crack Detection Model
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, L.; Liu, W.; He, Z. A review of research on asphalt pavement design at home and abroad. Highway 2015, 12, 44–49. [Google Scholar]
- Li, Z.; Huang, X.; Chen, G.; Xu, T. Research on Reliability Evaluation of Asphalt Pavement. J. Beijing Univ. Technol. 2012, 8, 1208–1213. [Google Scholar]
- Tarawneh, S.; Sarireh, M. Causes of Cracks and Deterioration of Pavement on Highways in Jordan from Contractors’ Perspective. Civ. Environ. Res. 2013, 3, 16–26. [Google Scholar]
- Ottoa, F.; Liu, P.; Zhang, Z.; Wang, D.; Oeser, M. Influence of temperature on the cracking behavior of asphalt base courses with structural weaknesses. Int. J. Transp. Sci. Technol. 2018, 7, 208–216. [Google Scholar] [CrossRef]
- Miller, J.; Bellinger, W. Distress Identification Manual for the Long-Term Pavement Performance Program, Fifth Revised ed.; United States Department of Transportation Federal Highway Administration: Washington, DC, USA, 2014; pp. 1–16.
- Pavement Distresses. Available online: https://pavementinteractive.org/reference-desk/pavement-management/pavement-distresses/ (accessed on 1 January 2012).
- Fawzy, M.; Shrakawy, A.; Hassan, A.; Khalifa, Y. Enhancing sustainability for pavement maintenance decision-making through image processing-based distress detection. Innov. Infrastruct. Solut. 2024, 9, 58. [Google Scholar] [CrossRef]
- Molenaar, A. Structural Performance and Design of Flexible Road Constructions and Asphalt Concrete Overlays. Ph.D. Thesis, Delft University of Technology, Delft, The Netherlands, 1983. [Google Scholar]
- Vaitkus, A.; Čygas, D.; Motiejūnas, A.; Pakalnis, A.; Miškinis, D. Improvement of road pavement maintenance models and technologies. Balt. J. Road Bridg. Eng. 2016, 11, 242–249. [Google Scholar] [CrossRef]
- Chuo, E. Overview of the development of foreign road automatic detection systems. Transp. Stand. 2009, 17, 96–99. [Google Scholar]
- Gao, F. Research and Implementation of Road Comprehensive Information Collection System. Master’s Thesis, Changan University, Xian, China, 2009. [Google Scholar]
- Qureshi, W.; Hassan, S.; McKeever, S.; Power, D.; Mulry, B.; Feighan, K.; O’Sullivan, D. An Exploration of Recent Intelligent Image Analysis Techniques for Visual Pavement Surface Condition Assessment. Sensors 2022, 22, 9019. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Liu, T.; Wang, X. Advanced pavement distress recognition and 3D reconstruction by using GA-DenseNet and binocular stereo vision. Measurement 2022, 201, 111760. [Google Scholar] [CrossRef]
- Hou, Y.; Li, Q.; Zhang, C.; Lu, G.; Ye, Z.; Chen, Y.; Wang, L.; Cao, D. The State-of-the-Art Review on Applications of Intrusive Sensing, Image Processing Techniques, and Machine Learning Methods in Pavement Monitoring and Analysis. Engineering 2021, 7, 845–856. [Google Scholar] [CrossRef]
- Feldman, D.; Pyle, T.; Lee, J. Automated Pavement Condition Survey Manual; California Department of Transportation: Los Angeles, CA, USA, 2015. [Google Scholar]
- Majidifard, H.; Jin, P.; Adu-Gyamfi, Y.; Buttlar, W. Pavement Image Datasets: A New Benchmark Dataset to Classify and Densify Pavement Distresses. In Proceedings of the TRB 99th Annual Meeting, Washington, DC, USA, 12–16 January 2020. [Google Scholar]
- Klette, R. Concise Computer Vision; Springer: London, UK, 2014; pp. 287–330. [Google Scholar]
- Morris, T. Computer Vision and Image Processing; Palgrave Macmillan Ltd.: New York, NY, USA, 2004; pp. 287–330. [Google Scholar]
- O’Mahony, N.; Campbell, S.; Carvalho, A.; Harapanahalli, S.; Hernandez, G.; Krpalkova, L.; Riordan, D.; Walsh, J. Deep Learning vs. Traditional Computer Vision. In Advances in Computer Vision, Proceedings of the 2019 Computer Vision Conference (CVC), Las Vegas, CA, USA, 2–3 May 2019; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 128–144. [Google Scholar]
- Chen, L.; Li, S.; Bai, Q.; Yang, J.; Jiang, S.; Miao, Y. Review of Image Classification Algorithms Based on Convolutional Neural Networks. Remote Sens. 2021, 13, 4712. [Google Scholar] [CrossRef]
- Chai, J.; Zeng, H.; Li, A.; Ngai, E. Deep learning in computer vision: A critical review of emerging techniques and application scenarios. Mach. Learn. Appl. 2021, 6, 100134. [Google Scholar] [CrossRef]
- Sarker, I. Deep Learning: A Comprehensive Overview on Techniques, Taxonomy, Applications and Research Directions. SN Comput. Sci. 2021, 2, 420. [Google Scholar] [CrossRef] [PubMed]
- Valente, J.; António, J.; Mora, C.; Jardim, S. Developments in Image Processing Using Deep Learning and Reinforcement Learning. J. Imaging 2023, 9, 207. [Google Scholar] [CrossRef] [PubMed]
- Nasser, M.; Yusof, U. Deep Learning Based Methods for Breast Cancer Diagnosis: A Systematic Review and Future Direction. Diagnostics 2023, 13, 161. [Google Scholar] [CrossRef]
- Prerna, S. Systematic review of data-centric approaches in artificial intelligence and machine learning. Data Sci. Manag. 2023, 6, 144–157. [Google Scholar]
- Zhang, L.; Yang, F.; Zhang, Y.; Zhu, Y. Road crack detection using deep convolutional neural network. In Proceedings of the IEEE International Conference on Image Processing, Phoenix, AZ, USA, 25–28 September 2016. [Google Scholar]
- Yusof, N.; Osman, K.; Noor, M.; Ibrahim, A.; Tahir, N.; Yusof, N. Crack Detection and Classification in Asphalt Pavement Images using Deep Convolution Neural Network. In Proceedings of the 2018 8th IEEE International Conference on Control System, Computing and Engineering (ICCSCE), Penang, Malaysia, 23–25 November 2018. [Google Scholar]
- Zhang, A.; Wang, K.; Li, B.; Yang, E.; Dai, X.; Peng, Y.; Fei, Y.; Liu, Y.; Li, J.; Chen, C. Automated Pixel-Level Pavement Crack Detection on 3D Asphalt Surfaces Using a Deep-Learning Network. Comput.-Aided Civ. Infrastruct. Eng. 2017, 32, 805–819. [Google Scholar] [CrossRef]
- Mandal, V.; Uong, L.; Adu-Gyamfi, Y. Automated Road Crack Detection Using Deep Convolutional Neural Networks. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018. [Google Scholar]
- Nie, M.; Wang, C. Pavement Crack Detection based on yolov3. In Proceedings of the 2019 2nd International Conference on Safety Produce Informatization (IICSPI), Chongqing, China, 28–30 November 2019. [Google Scholar]
- Cao, W.; Zou, Y.; Luo, M.; Zhang, P.; Wang, W.; Huang, W. Deep Discriminant Learning-based Asphalt Road Cracks Detection via Wireless Camera Network. In Proceedings of the 2019 Computing, Communications and IoT Applications (ComComAp), Shenzhen, China, 26–28 October 2019. [Google Scholar]
- Maeda, H.; Sekimoto, Y.; Seto, T.; Kashiyama, T.; Omata, H. Road Damage Detection and Classification Using Deep Neural Networks with Smartphone Images. Comput. Civ. Infrastruct. Eng. 2018, 33, 1127–1141. [Google Scholar] [CrossRef]
- Maeda, H.; Kashiyama, T.; Sekimoto, Y.; Seto, T.; Omata, H. Generative adversarial network for road damage detection. Comput.-Aided Civ. Infrastruct. Eng. 2020, 36, 47–60. [Google Scholar] [CrossRef]
- Ruseruka, C.; Mwakalonge, J.; Comert, G.; Siuhi, S.; Ngeni, F.; Major, K. Pavement Distress Identification Based on Computer Vision and Controller Area Network (CAN) Sensor Models. Sustainability 2023, 15, 6438. [Google Scholar] [CrossRef]
- Wang, Y. Intelligent Detection System of Pavement Crack Based on Deep Learning. Master’s Thesis, University of Science and Technology Beijing, Beijing, China, 2021. [Google Scholar]
- Sun, C.; Shrivastava, A.; Singh, S.; Gupta, A. Revisiting Unreasonable Effectiveness of Data in Deep Learning Era. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Chen, J.; Luo, S.; Li, L.; Dan, H.; Zhao, L. Temperature distribution and method-experience prediction model of asphalt pavement. J. Cent. South Univ. 2013, 44, 1647–1656. [Google Scholar]
- Wang, K.; Hao, P. Prediction model of temperature in different layers of asphalt pavement. J. Chang. Univ. 2017, 37, 24–30. [Google Scholar]
- Epps, J.; Monismith, C. Fatigue of asphalt concrete mixtures—Summary of existing information. In Fatigue of Compacted Bituminous Aggregate Mixtures; Gallaway, B., Ed.; ASTM International: West Conshohocken, PA, USA, 1972; pp. 19–45. [Google Scholar]
- Tang, G.; Ni, J.; Zhao, Y.; Gu, Y.; Cao, W. A Survey of Object Detection for UAVs Based on Deep Learning. Remote Sens. 2024, 16, 149. [Google Scholar] [CrossRef]
- Xu, H.; Su, X.; Wang, Y.; Cai, H.; Cui, K.; Chen, X. Automatic Bridge Crack Detection Using a Convolutional Neural Network. Appl. Sci. 2019, 9, 2867. [Google Scholar] [CrossRef]
- Li, L.; Ma, W.; Li, L.; Lu, C. Research on detection algorithm for bridge cracks based on deep learning. Acta Autom. Sin. 2019, 45, 1727–1742. [Google Scholar]
- Cui, L. CrackForest Dataset. Available online: https://github.com/cuilimeng/CrackForest-dataset (accessed on 11 May 2017).
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Ultralytics. yolov5. Available online: https://github.com/ultralytics/yolov5/ (accessed on 26 June 2020).
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, 2004, 10934. [Google Scholar]
- Zaidi, S.; Ansari, M.; Aslam, A.; Kanwal, N.; Asghar, M.; Lee, B. A Survey of Modern Deep Learning based Object Detection Models. Digit. Signal Process. 2022, 126, 103514. [Google Scholar] [CrossRef]
- Ren, Z.; Zhang, H.; Li, Z. Improved YOLOv5 Network for Real-Time Object Detection in Vehicle-Mounted Camera Capture Scenarios. Sensors 2023, 23, 4589. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Yang, B.; Zong, Z.; Chen, C.; Sun, W.; Mi, X.; Wu, W.; Huang, R. Real time approach for underground objects detection from vehicle-borne ground penetrating radar. Acta Geod. Cartogr. Sin. 2020, 49, 874–882. [Google Scholar]
- Wu, H.; Yao, L.; Xu, Z.; Li, Y.; Ao, X.; Chen, Q.; Li, Z.; Meng, B. Road pothole extraction and safety evaluation by integration of point cloud and images derived from mobile mapping sensor. Adv. Eng. Inform. 2019, 42, 100936. [Google Scholar] [CrossRef]
- Tan, Y.; Li, Y. UAV Photogrammetry-Based 3D Road Distress Detection. ISPRS Int. J. Geo-Inf. 2019, 8, 409. [Google Scholar] [CrossRef]
- Wang, D.; Lyu, H.; Tang, F.; Ye, C.; Zhang, F.; Wang, S.; Ni, Y.; Leng, Z.; Lu, G.; Liu, P. Road Structural Defects Detection and Digitalization Based on 3D Ground Penetrating Radar Technology: A State-of-the-art Review. China J. Highw. Transp. 2023, 36, 1–19. [Google Scholar]
- Li, Y.; Sun, S.; Song, W.; Zhang, J.; Teng, Q. CrackYOLO: Rural Pavement Distress Detection Model with Complex Scenarios. Electronics 2024, 13, 312. [Google Scholar] [CrossRef]
- Xu, X.; Zhao, M.; Shi, P.; Ren, R.; He, X.; Wei, X.; Yang, H. Crack Detection and Comparison Study Based on Faster R-CNN and Mask R-CNN. Sensors 2022, 22, 1215. [Google Scholar] [CrossRef] [PubMed]
- Wu, L.; Duan, Z.; Liang, C. Research on Asphalt Pavement Disease Detection Based on Improved YOLOv5s. J. Sens. 2023, 2023, 688–695. [Google Scholar] [CrossRef]
- Yu, G.; Zhou, X. An Improved YOLOv5 Crack Detection Method Combined with a Bottleneck Transformer. Mathematics 2023, 11, 2377. [Google Scholar] [CrossRef]
- Ren, J.; Zhao, G.; Ma, Y.; Zhao, D.; Liu, T.; Yan, J. Automatic Pavement Crack Detection Fusing Attention Mechanism. Electronics 2022, 11, 3622. [Google Scholar] [CrossRef]
- Canestrari, F.; Ingrassia, L. A review of top-down cracking in asphalt pavements: Causes, models, experimental tools and future challenges. J. Traffic Transp. Eng. 2020, 7, 541–572. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image Source | Image Number | Transverse | Longitudinal | Block | Alligator | |
|---|---|---|---|---|---|---|
| Experimental collecting | Camera, car | 1281 | 723 | 1700 | 394 | 373 |
| Driving recorder, bus | 462 | 99 | 571 | 25 | 15 | |
| Online searching | 2264 | 944 | 1675 | 440 | 923 | |
| Total | 4007 | 1766 | 3946 | 859 | 1311 | |
| Test Set | Transverse | Longitudinal | Block | Alligator |
|---|---|---|---|---|
| Labeling box number | 135 | 237 | 64 | 156 |
| Detection Network | Average Precision (AP) | Mean Average Precision (mAP) | |||
|---|---|---|---|---|---|
| Transverse | Longitudinal | Block | Alligator | Test Set | |
| Faster-RCNN | 66.27% | 70.44% | 92.24% | 84.87% | 78.46% |
| YOLOv3 | 72.62% | 75.83% | 98.31% | 90.13% | 84.22% |
| YOLOv5 | 73.54% | 77.26% | 98.38% | 90.42% | 84.90% |
| The proposed network | 81.75% | 83.81% | 98.20% | 92.83% | 89.15% |
| Detection Network | Missed Detection Rate | False Detection Rate | ||||
|---|---|---|---|---|---|---|
| Transverse | Longitudinal | Block | Alligator | Test Set | Test Set | |
| YOLOv5 | 13.33% | 9.70% | 3.13% | 6.41% | 8.95% | 0% |
| The proposed network | 2.96% | 2.53% | 0% | 1.92% | 2.20% | 0% |
| Evaluation Indicators | Transverse | Longitudinal | Block | Alligator |
|---|---|---|---|---|
| Missed detection rate | 5.26% | 4.05% | 5.56% | 0% |
| False detection rate | 0% | 0.12% | 0% | 0% |
| Method | Detection Object | Accuracy | Systematic Error | Cost |
|---|---|---|---|---|
| Image processing (the proposed method) | Transverse, longitudinal, block, and alligator | mAP: 89.15% | Missed detection rate: 2.20% | Hundreds of dollars |
| 3D GPR [53] | Rainwater wells, cables, pipes, steel mesh, and cavities | mAP: 92.00% | / | Tens of thousand dollars |
| 3D laser scanning [54] | Potholes | / | Mean error: 1.5–2.8 cm | Hundreds of thousand dollars |
| UAVs [55] | Cavities and bulges | / | Hight dimension error: 1 cm | Thousands of dollars |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Qi, Q.; Sun, L.; Xian, W.; Ma, T.; Lu, C.; Zhang, J. An Intelligent Detection and Classification Model Based on Computer Vision for Pavement Cracks in Complicated Scenarios. Appl. Sci. 2024, 14, 2909. https://0-doi-org.brum.beds.ac.uk/10.3390/app14072909
Wang Y, Qi Q, Sun L, Xian W, Ma T, Lu C, Zhang J. An Intelligent Detection and Classification Model Based on Computer Vision for Pavement Cracks in Complicated Scenarios. Applied Sciences. 2024; 14(7):2909. https://0-doi-org.brum.beds.ac.uk/10.3390/app14072909
Chicago/Turabian StyleWang, Yue, Qingjie Qi, Lifeng Sun, Wenhao Xian, Tianfang Ma, Changjia Lu, and Jingwen Zhang. 2024. "An Intelligent Detection and Classification Model Based on Computer Vision for Pavement Cracks in Complicated Scenarios" Applied Sciences 14, no. 7: 2909. https://0-doi-org.brum.beds.ac.uk/10.3390/app14072909