
Design and Evaluation of CPU-, GPU-, and FPGA-Based Deployment of a CNN for Motor Imagery Classification in Brain-Computer Interfaces
 , , ,
, , ,
Abstract
:1. Introduction
Authors’ Contributions
- Preliminary validation of a newly collected dataset composed of 29 patients using a BioSemi Active Two gel-based EEG cap.
- Training and fine-tuning of a CNN for motor imagery on the collected data in offline mode.
- Deployment and comparison of the trained CNN over multiple hardware technologies for edge computing: CPU, embedded GPU, and FPGA.
2. Materials and Methods
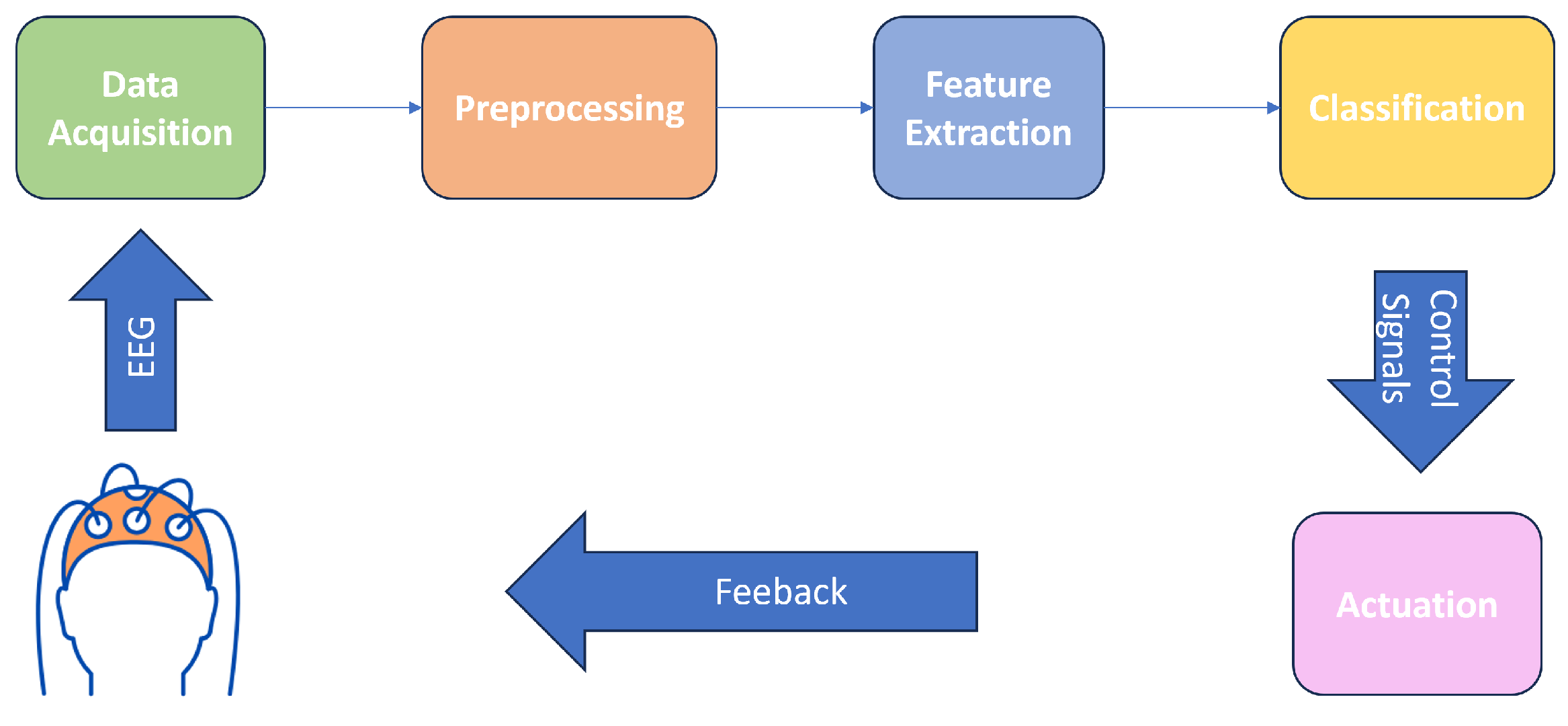
2.1. System Architecture
2.2. Data
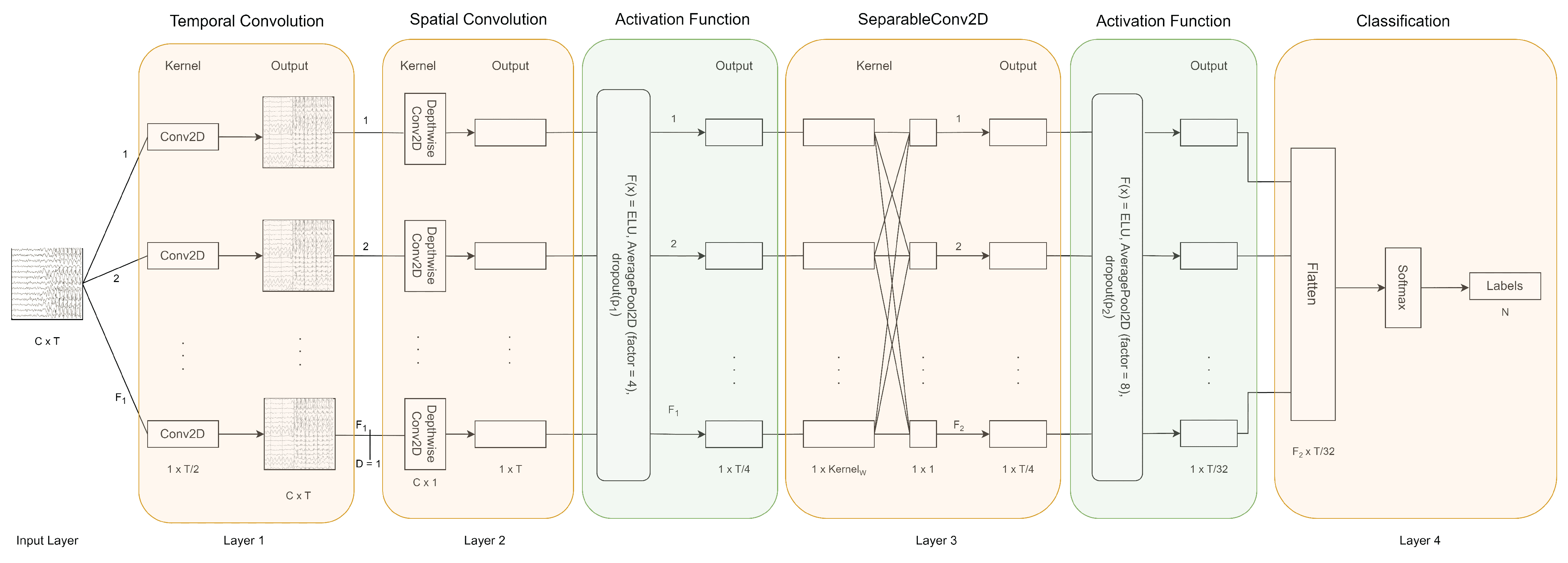
2.3. Convolutional Neural Network Architecture
2.4. Hardware Deployment and Benchmarking
- Accuracy.
- Inference time.
- Power consumption.
- Memory footprint.
2.4.1. CPU
2.4.2. GPU
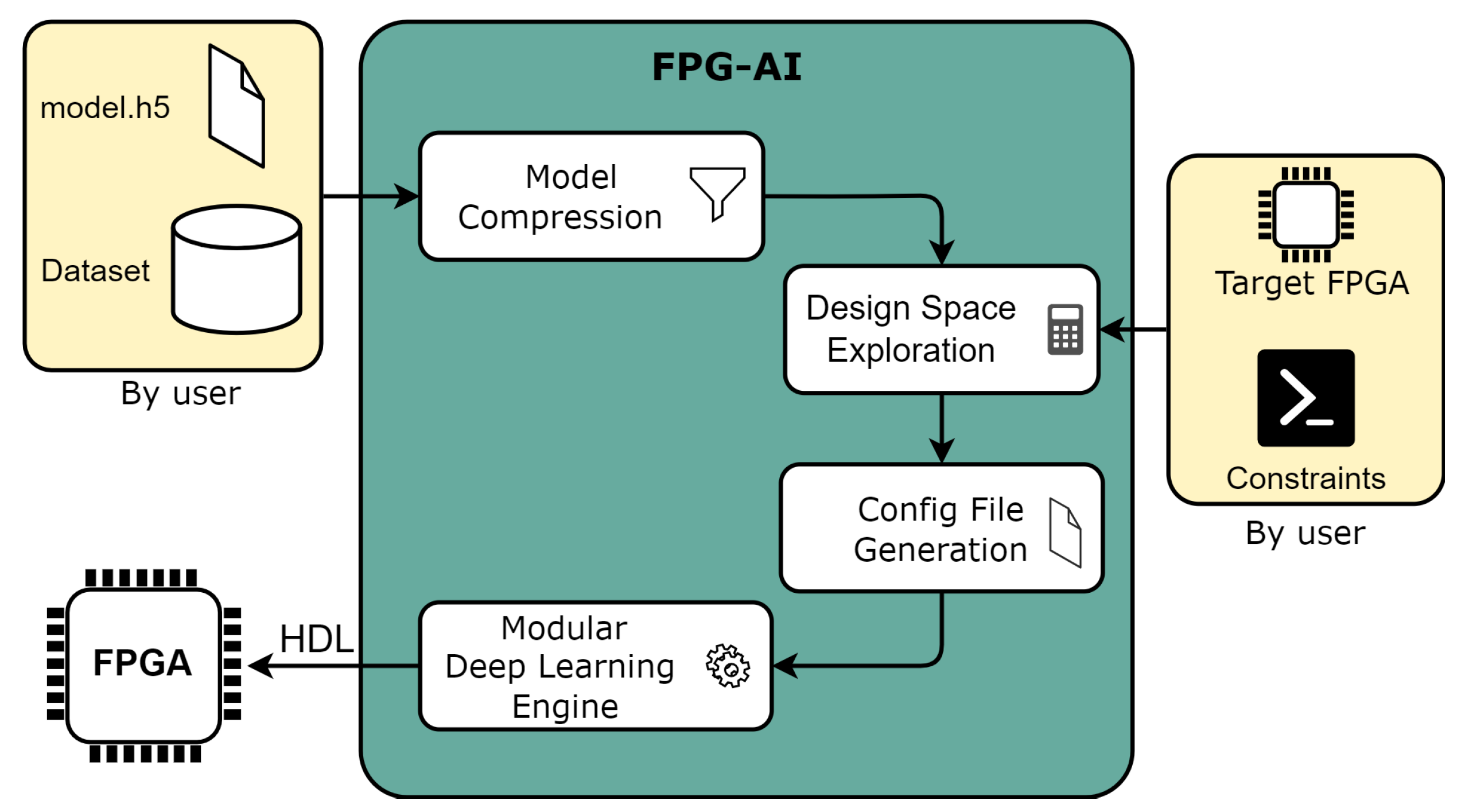
2.4.3. FPGA
3. Results
3.1. Inference on CPU
3.2. Inference on GPU
3.3. Inference on FPGA
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| T | 512 |
| C | 64 |
| D | 2 |
| Kernelw | 16 |
| F1 | 8 |
| F2 | 16 |
| p1 | 0.25 |
| p2 | 0.25 |
| N | 2 |



References
- Zhang, R.; Wang, Q.; Li, K.; He, S.; Qin, S.; Feng, Z.; Chen, Y.; Song, P.; Yang, T.; Zhang, Y.; et al. A BCI-Based Environmental Control System for Patients with Severe Spinal Cord Injuries. IEEE Trans. Biomed. Eng. 2017, 64, 1959–1971. [Google Scholar] [CrossRef]
- Biasiucci, A.; Leeb, R.; Iturrate, I.; Perdikis, S.; Al-Khodairy, A.; Corbet, T.; Schnider, A.; Schmidlin, T.; Zhang, H.; Bassolino, M.; et al. Brain-actuated functional electrical stimulation elicits lasting arm motor recovery after stroke. Nat. Commun. 2018, 9, 2421. [Google Scholar] [CrossRef] [PubMed]
- Ang, K.K.; Guan, C. Brain-computer interface for neurorehabilitation of upper limb after stroke. Proc. IEEE 2015, 103, 944–953. [Google Scholar] [CrossRef]
- Cho, J.H.; Jeong, J.H.; Shim, K.H.; Kim, D.J.; Lee, S.W. Classification of hand motions within EEG signals for non-invasive BCI-based robot hand control. In Proceedings of the 2018 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Miyazaki, Japan, 7–10 October 2018; pp. 515–518. [Google Scholar]
- Frolov, A.A.; Mokienko, O.; Lyukmanov, R.; Biryukova, E.; Kotov, S.; Turbina, L.; Bushkova, Y. Post-stroke rehabilitation training with a motor-imagery-based brain-computer interface (BCI)-controlled hand exoskeleton: A randomized controlled multicenter trial. Front. Neurosci. 2017, 11, 253346. [Google Scholar] [CrossRef]
- Li, Y.; Pan, J.; Wang, F.; Yu, Z. A hybrid BCI system combining P300 and SSVEP and its application to wheelchair control. IEEE Trans. Biomed. Eng. 2013, 60, 3156–3166. [Google Scholar]
- Tariq, M.; Trivailo, P.M.; Simic, M. EEG-based BCI control schemes for lower-limb assistive-robots. Front. Hum. Neurosci. 2018, 12, 312. [Google Scholar] [CrossRef]
- Decety, J. The neurophysiological basis of motor imagery. Behav. Brain Res. 1996, 77, 45–52. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.J.; Jeon, E.J.; Kim, J.S.; Chung, C.K. Characterization of kinesthetic motor imagery compared with visual motor imageries. Sci. Rep. 2021, 11, 3751. [Google Scholar] [CrossRef] [PubMed]
- Lotze, M.; Halsband, U. Motor imagery. J. Physiol. 2006, 99, 386–395. [Google Scholar] [CrossRef]
- Ridderinkhof, K.R.; Brass, M. How kinesthetic motor imagery works: A predictive-processing theory of visualization in sports and motor expertise. J. Physiol. 2015, 109, 53–63. [Google Scholar] [CrossRef]
- Vaid, S.; Singh, P.; Kaur, C. EEG signal analysis for BCI interface: A review. In Proceedings of the 2015 Fifth International Conference on Advanced Computing & CommunicationTechnologies, Haryana, India, 21–22 February 2015; pp. 143–147. [Google Scholar]
- Blankertz, B.; Tomioka, R.; Lemm, S.; Kawanabe, M.; Muller, K.r. Optimizing Spatial filters for Robust EEG Single-Trial Analysis. IEEE Signal Process. Mag. 2008, 25, 41–56. [Google Scholar] [CrossRef]
- Al-Saegh, A.; Dawwd, S.A.; Abdul-Jabbar, J.M. Deep learning for motor imagery EEG-based classification: A review. Biomed. Signal Process. Control 2021, 63, 102172. [Google Scholar] [CrossRef]
- Zhang, X.; Yao, L.; Wang, X.; Monaghan, J.; Mcalpine, D.; Zhang, Y. A survey on deep learning based brain computer interface: Recent advances and new frontiers. arXiv 2019, arXiv:1905.04149. [Google Scholar]
- Altaheri, H.; Muhammad, G.; Alsulaiman, M.; Amin, S.U.; Altuwaijri, G.A.; Abdul, W.; Bencherif, M.A.; Faisal, M. Deep learning techniques for classification of electroencephalogram (EEG) motor imagery (MI) signals: A review. Neural Comput. Appl. 2023, 35, 14681–14722. [Google Scholar] [CrossRef]
- Saibene, A.; Caglioni, M.; Corchs, S.; Gasparini, F. EEG-based BCIs on motor imagery paradigm using wearable technologies: A systematic review. Sensors 2023, 23, 2798. [Google Scholar] [CrossRef] [PubMed]
- Khademi, Z.; Ebrahimi, F.; Kordy, H.M. A review of critical challenges in MI-BCI: From conventional to deep learning methods. J. Neurosci. Methods 2023, 383, 109736. [Google Scholar] [CrossRef]
- Wilson, J.A.; Williams, J.C. Massively parallel signal processing using the graphics processing unit for real-time brain-computer interface feature extraction. Front. Neuroeng. 2009, 2, 653. [Google Scholar] [CrossRef]
- Raimondo, F.; Kamienkowski, J.E.; Sigman, M.; Slezak, D.F. CUDAICA: GPU optimization of infomax-ICA EEG analysis. Comput. Intell. Neurosci. 2012, 2012, 2. [Google Scholar] [CrossRef] [PubMed]
- Shyu, K.K.; Lee, P.L.; Lee, M.H.; Lin, M.H.; Lai, R.J.; Chiu, Y.J. Development of a low-cost FPGA-based SSVEP BCI multimedia control system. IEEE Trans. Biomed. Circuits Syst. 2010, 4, 125–132. [Google Scholar] [CrossRef]
- Heelan, C.; Nurmikko, A.V.; Truccolo, W. FPGA implementation of deep-learning recurrent neural networks with sub-millisecond real-time latency for BCI-decoding of large-scale neural sensors (104 nodes). In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; pp. 1070–1073. [Google Scholar]
- Sannelli, C.; Vidaurre, C.; Müller, K.R.; Blankertz, B. A large scale screening study with a SMR-based BCI: Categorization of BCI users and differences in their SMR activity. PLoS ONE 2019, 14, e0207351. [Google Scholar] [CrossRef]
- Ins, B. BioSemi Active Two EEG Cap, 2001. Available online: https://www.biosemi.com/products.htm (accessed on 21 April 2024).
- Klonowski, W. Everything you wanted to ask about EEG but were afraid to get the right answer. Nonlinear Biomed. Phys. 2009, 3, 1–5. [Google Scholar] [CrossRef] [PubMed]
- Perrin, F.; Pernier, J.; Bertrand, O.; Echallier, J.F. Spherical splines for scalp potential and current density mapping. Electroencephalogr. Clin. Neurophysiol. 1989, 72, 184–187. [Google Scholar] [CrossRef] [PubMed]
- Hyvärinen, A.; Oja, E. Independent component analysis: Algorithms and applications. Neural Netw. Off. J. Int. Neural Netw. Soc. 2000, 13, 411–430. [Google Scholar] [CrossRef]
- Arnau, S.; Sharifian, F.; Wascher, E.; Larra, M.F. Removing the cardiac field artifact from the EEG using neural network regression. Psychophysiology 2023, 60, e14323. [Google Scholar] [CrossRef]
- Yuan, H.; Liu, T.; Szarkowski, R.; Rios, C.; Ashe, J.; He, B. Negative covariation between task-related responses in alpha/beta-band activity and BOLD in human sensorimotor cortex: An EEG and fMRI study of motor imagery and movements. NeuroImage 2010, 49, 2596–2606. [Google Scholar] [CrossRef] [PubMed]
- De Lange, F.; Jensen, O.; Bauer, M.; Toni, I. Interactions between posterior gamma and frontal alpha/beta oscillations during imagined actions. Front. Hum. Neurosci. 2008, 2, 269. [Google Scholar] [CrossRef] [PubMed]
- Lashgari, E.; Liang, D.; Maoz, U. Data augmentation for deep-learning-based electroencephalography. J. Neurosci. Methods 2020, 346, 108885. [Google Scholar] [CrossRef] [PubMed]
- Lawhern, V.J.; Solon, A.J.; Waytowich, N.R.; Gordon, S.M.; Hung, C.P.; Lance, B.J. EEGNet: A compact convolutional neural network for EEG-based brain–computer interfaces. J. Neural Eng. 2018, 15, 056013. [Google Scholar] [CrossRef]
- TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: https://www.tensorflow.org/ (accessed on 21 April 2024).
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A next-generation hyperparameter optimization framework. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2623–2631. [Google Scholar]
- NVIDIA; Vingelmann, P.; Fitzek, F.H. CUDA, release: 10.2.89, 2020. Available online: https://developer.nvidia.com/cuda-toolkit (accessed on 21 April 2024).
- NVIDIA. Jetson Nano 2GB Developer Kit, 2020. Available online: https://developer.nvidia.com/embedded/learn/get-started-jetson-nano-2gb-devkit (accessed on 21 April 2024).
- Pacini, T.; Rapuano, E.; Fanucci, L. FPG-AI: A Technology-Independent Framework for the Automation of CNN Deployment on FPGAs. IEEE Access 2023, 11, 32759–32775. [Google Scholar] [CrossRef]
- Pacini, T.; Rapuano, E.; Tuttobene, L.; Nannipieri, P.; Fanucci, L.; Moranti, S. Towards the Extension of FPG-AI Toolflow to RNN Deployment on FPGAs for On-board Satellite Applications. In Proceedings of the 2023 European Data Handling & Data Processing Conference (EDHPC), Juan-Les-Pins, France, 2–6 October 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Xilinx, A. Xilinx Ultrascale+ ZU7EV Datasheet, 2022. Available online: https://docs.xilinx.com/v/u/en-US/ds891-zynq-ultrascale-plus-overview (accessed on 21 April 2024).





| Average Inference Time (ms) | Average Power Consumption (W) | Average Memory Footprint (Mb) | Average Test Accuracy | |
|---|---|---|---|---|
| Average over participants | 121.57 | 13.22 | 476 | 81 |
| 5 W Mode Average Inference Time (ms) | 10 W Mode Average Inference Time (ms) | Average Memory Footprint (Mb) | Average Test Accuracy | |
|---|---|---|---|---|
| Average over participants | 415 | 81 |
| Average Inference Time (ms) | Average Power Consumption (W) | Average Memory Footprint (Mb) | Average Test Accuracy | |
|---|---|---|---|---|
| Average over participants | 12.97 | 1.47 | 6.37 | 77 |
| CPU | FPGA | Jetson Nano | ||
|---|---|---|---|---|
| Power consumption (W) | 5 | 10 | ||
| Inference time (ms) | ||||
| FOM (W × s) | 29.36 | 79.25 | 122.1 | |
| Memory footprint (Mb) | 476 | 6.37 | 415 | |
| Test accuracy | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pacini, F.; Pacini, T.; Lai, G.; Zocco, A.M.; Fanucci, L. Design and Evaluation of CPU-, GPU-, and FPGA-Based Deployment of a CNN for Motor Imagery Classification in Brain-Computer Interfaces. Electronics 2024, 13, 1646. https://0-doi-org.brum.beds.ac.uk/10.3390/electronics13091646
Pacini F, Pacini T, Lai G, Zocco AM, Fanucci L. Design and Evaluation of CPU-, GPU-, and FPGA-Based Deployment of a CNN for Motor Imagery Classification in Brain-Computer Interfaces. Electronics. 2024; 13(9):1646. https://0-doi-org.brum.beds.ac.uk/10.3390/electronics13091646
Chicago/Turabian StylePacini, Federico, Tommaso Pacini, Giuseppe Lai, Alessandro Michele Zocco, and Luca Fanucci. 2024. "Design and Evaluation of CPU-, GPU-, and FPGA-Based Deployment of a CNN for Motor Imagery Classification in Brain-Computer Interfaces" Electronics 13, no. 9: 1646. https://0-doi-org.brum.beds.ac.uk/10.3390/electronics13091646