
Single-Image Super-Resolution Method for Rotating Synthetic Aperture System Using Masking Mechanism
 , , ,
, , ,
Abstract
:1. Introduction
2. Materials and Methods
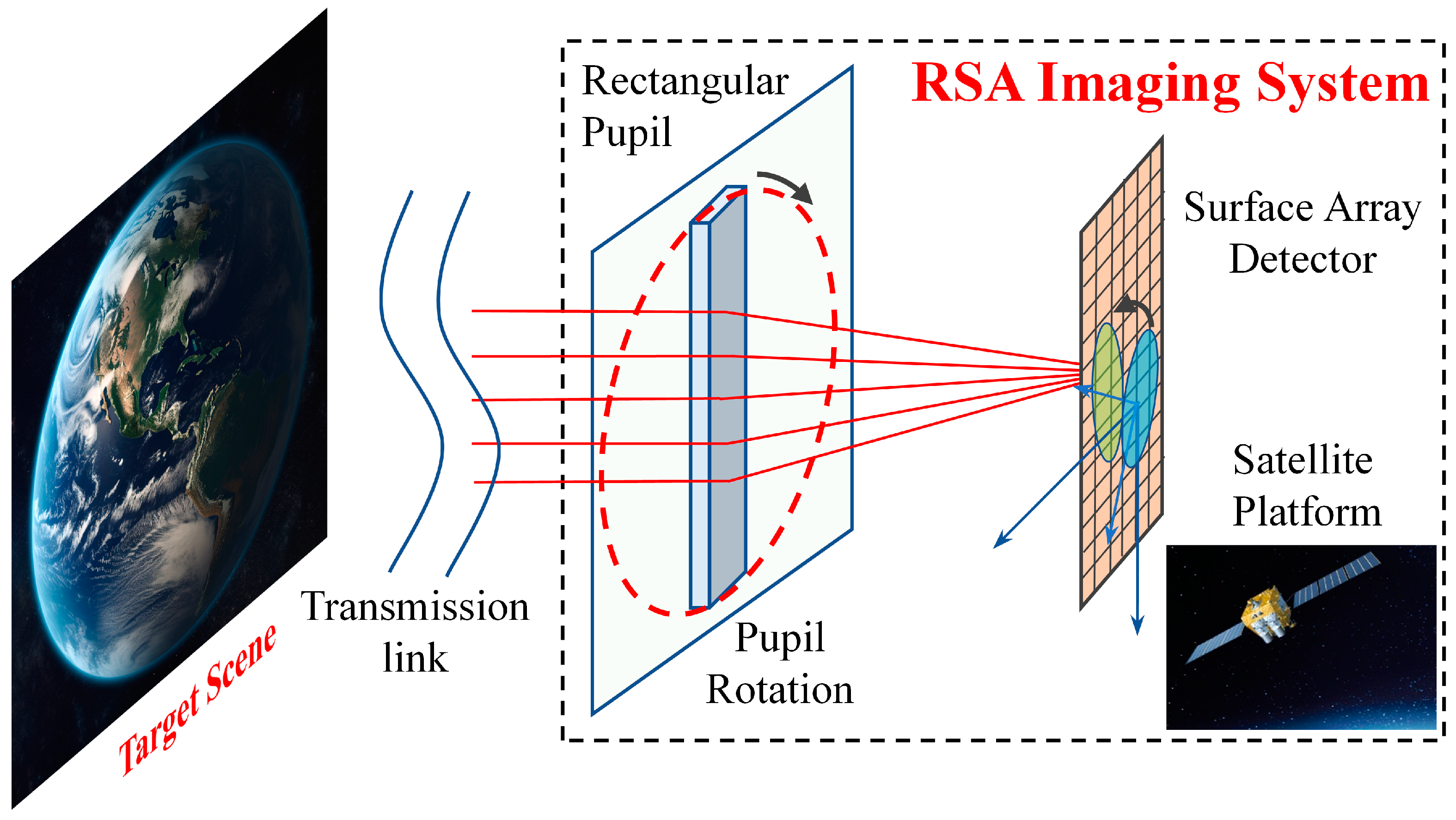
2.1. Analysis of Imaging Mechanism of the RSA System
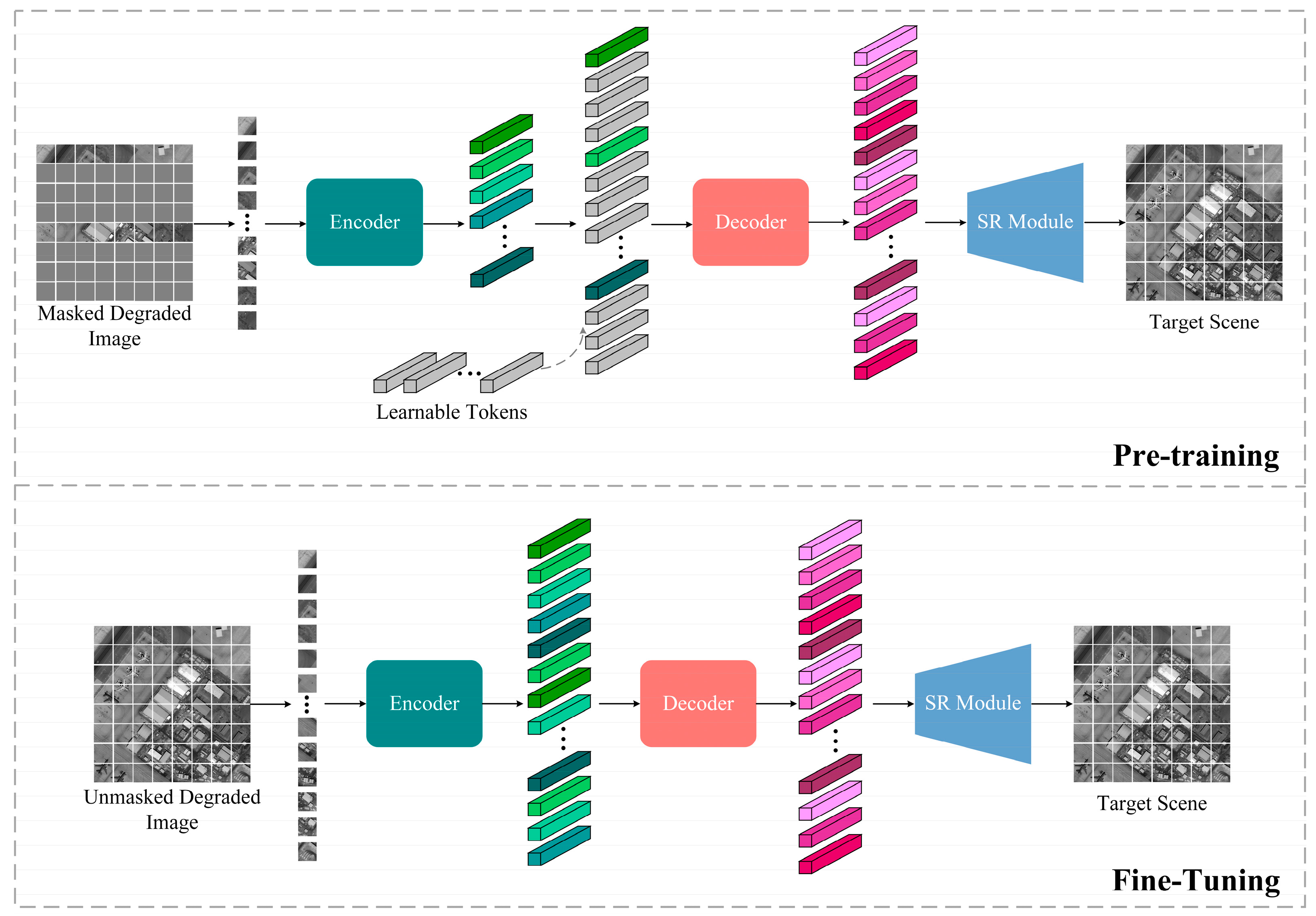
2.2. Overview of the Image Super-Resolution Approach
2.3. Encoder
2.3.1. Masked Autoencoder
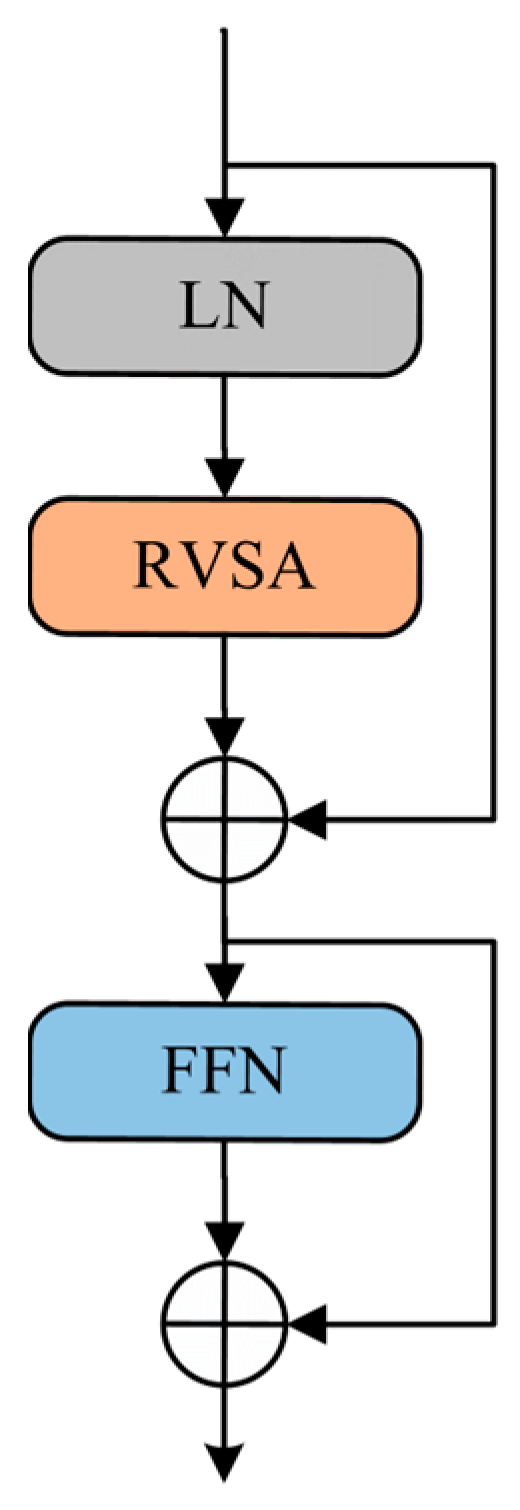
2.3.2. Rotated Varied-Size Window-Based Attention
2.4. Decoder
2.5. Implementation and Training Details
3. Results
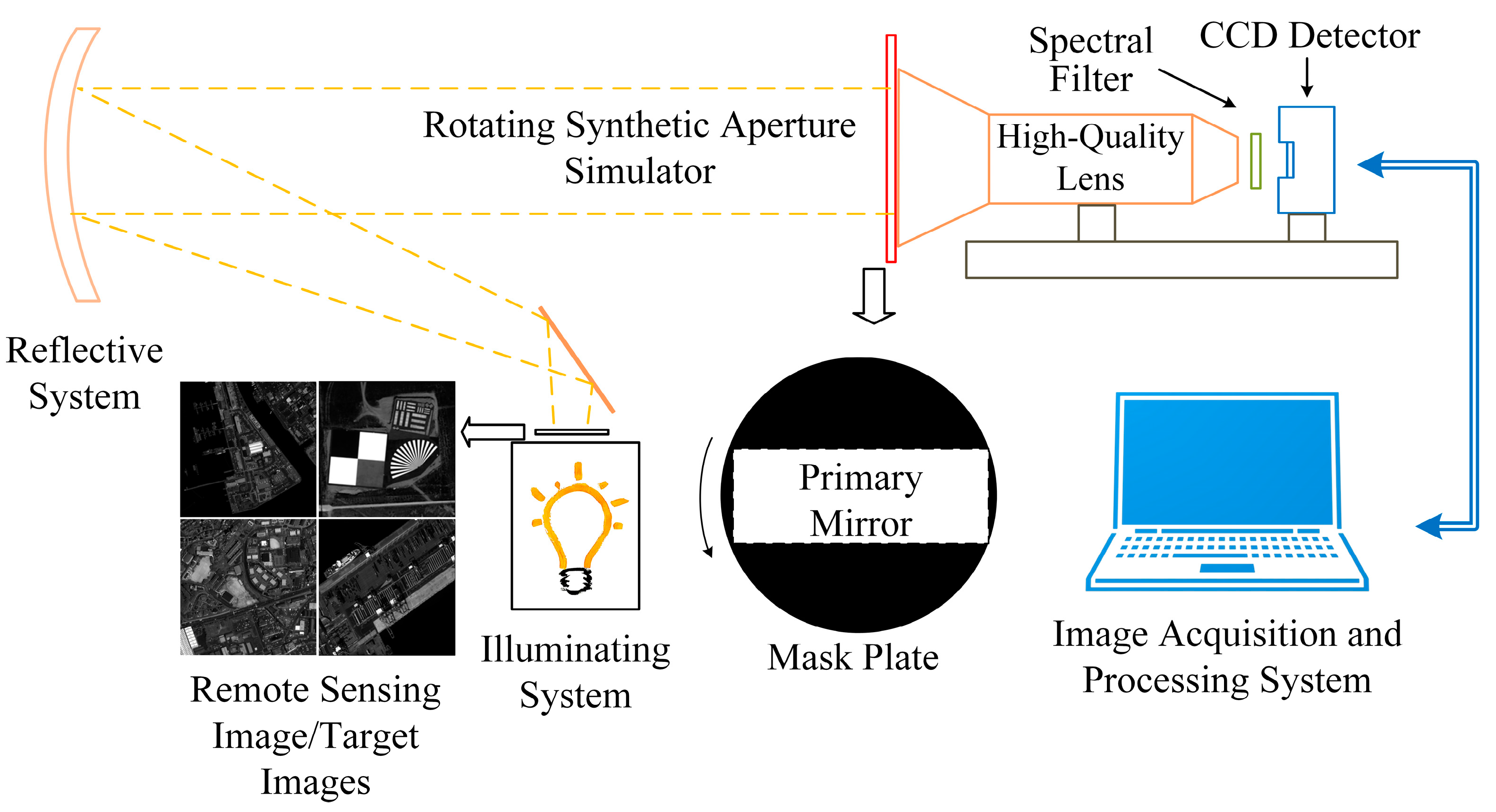
3.1. Experimental Setup
3.2. Experimental Results
3.2.1. Quantitative Results
3.2.2. Qualitative Results
3.2.3. Ablation Study
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yang, X.; Li, F.; Xin, L.; Lu, X.; Lu, M.; Zhang, N. An improved mapping with super-resolved multispectral images for geostationary satellites. Remote Sens. 2020, 12, 466. [Google Scholar] [CrossRef]
- Yao, L.; Liu, Y.; He, Y. A Novel Ship-Tracking Method for GF-4 Satellite Sequential Images. Sensors 2018, 18, 2007. [Google Scholar] [CrossRef]
- Kulkarni, S.C.; Rege, P.P. Pixel Level Fusion Techniques for SAR and Optical Images: A Review. Inf. Fusion 2020, 59, 13–29. [Google Scholar] [CrossRef]
- Yu, W.; You, H.; Lv, P.; Hu, Y.; Han, B. A Moving Ship Detection and Tracking Method Based on Optical Remote Sensing Images from the Geostationary Satellite. Sensors 2021, 21, 7547. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Ye, M.; Zhu, G.; Liu, Y.; Guo, P.; Yan, J. FFCA-YOLO for Small Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5611215. [Google Scholar] [CrossRef]
- Zhao, J. Higher Temporal Evapotranspiration Estimation with Improved SEBS Model from Geostationary Meteorological Satellite Data. Sci. Rep. 2019, 9, 14981. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Zhang, C.; Guo, L.; Xu, S.; Ju, G. Decoupled Object-Independent Image Features for Fine Phasing of Segmented Mirrors Using Deep Learning. Remote Sens. 2022, 14, 4681. [Google Scholar] [CrossRef]
- Jikuya, I.; Uchida, D.; Kino, M.; Kurita, M.; Yamada, K. Development status of the segmented mirror control system in Seimei Telescope. In Advances in Optical and Mechanical Technologies for Telescopes and Instrumentation IV; SPIE: Montréal, QC, Canada, 2020; Volume 11451, pp. 965–973. [Google Scholar]
- Atcheson, P.; Domber, J.; Whiteaker, K.; Britten, J.A.; Dixit, S.N.; Farmer, B. MOIRE: Ground Demonstration of a Large Aperture Diffractive Transmissive Telescope; Oschmann, J.M., Clampin, M., Fazio, G.G., MacEwen, H.A., Eds.; SPIE: Montréal, QC, Canada, 2014; p. 91431W. [Google Scholar]
- Liu, D.; Wang, L.; Yang, W.; Wu, S.; Fan, B.; Wu, F. Stray Light Characteristics of the Diffractive Telescope System. Opt. Eng. 2018, 57, 1. [Google Scholar] [CrossRef]
- Peng, Y.; Fu, Q.; Amata, H.; Su, S.; Heide, F.; Heidrich, W. Computational Imaging Using Lightweight Diffractive-Refractive Optics. Opt. Express 2015, 23, 31393. [Google Scholar] [CrossRef]
- Tang, J.; Wang, K.; Ren, Z.; Zhang, W.; Wu, X.; Di, J.; Liu, G.; Zhao, J. RestoreNet: A deep learning framework for image restoration in optical synthetic aperture imaging system. Opt. Lasers Eng. 2021, 139, 106463. [Google Scholar] [CrossRef]
- Rai, M.R.; Rosen, J. Optical incoherent synthetic aperture imaging by superposition of phase-shifted optical transfer functions. Opt. Lett. 2021, 46, 1712–1715. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.; Yang, F.; Cao, L. Resolution enhancement of long-range imaging with sparse apertures. Opt. Lasers Eng. 2022, 155, 107068. [Google Scholar] [CrossRef]
- Sun, Y.; Zhi, X.; Jiang, S.; Fan, G.; Yan, X.; Zhang, W. Image Fusion for the Novelty Rotating Synthetic Aperture System Based on Vision Transformer. Inf. Fusion 2024, 104, 102163. [Google Scholar] [CrossRef]
- Zhi, X.; Jiang, S.; Zhang, L.; Wang, D.; Hu, J.; Gong, J. Imaging mechanism and degradation characteristic analysis of novel rotating synthetic aperture system. Opt. Lasers Eng. 2021, 139, 106500. [Google Scholar] [CrossRef]
- Sun, Y.; Zhi, X.; Zhang, L.; Jiang, S.; Shi, T.; Wang, N.; Gong, J. Characterization and Experimental Verification of the Rotating Synthetic Aperture Optical Imaging System. Sci. Rep. 2023, 13, 17015. [Google Scholar] [CrossRef]
- Zhi, X.; Jiang, S.; Zhang, L.; Hu, J.; Yu, L.; Song, X.; Gong, J. Multi-frame image restoration method for novel rotating synthetic aperture imaging system. Results Phys. 2021, 23, 103991. [Google Scholar] [CrossRef]
- Gendy, G.; He, G.; Sabor, N. Lightweight Image Super-Resolution Based on Deep Learning: State-of-the-Art and Future Directions. Inf. Fusion 2023, 94, 284–310. [Google Scholar] [CrossRef]
- Xiao, Y.; Yuan, Q.; Jiang, K.; He, J.; Wang, Y.; Zhang, L. From Degrade to Upgrade: Learning a Self-Supervised Degradation Guided Adaptive Network for Blind Remote Sensing Image Super-Resolution. Inf. Fusion 2023, 96, 297–311. [Google Scholar] [CrossRef]
- Wei, S.; Cheng, H.; Xue, B.; Shao, X.; Xi, T. Low-Cost and Simple Optical System Based on Wavefront Coding and Deep Learning. Appl. Opt. 2023, 62, 6171. [Google Scholar] [CrossRef]
- Freeman, W.T.; Jones, T.R.; Pasztor, E.C. Example-based super-resolution. IEEE Comput. Graph. Appl. 2002, 22, 56–65. [Google Scholar] [CrossRef]
- Liu, A.; Liu, Y.; Gu, J.; Qiao, Y.; Dong, C. Blind image super-resolution: A survey and beyond. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 5461–5480. [Google Scholar] [CrossRef] [PubMed]
- Chen, H. Real-World Single Image Super-Resolution: A Brief Review. Inf. Fusion 2022, 79, 124–145. [Google Scholar] [CrossRef]
- Lepcha, D.C.; Goyal, B.; Dogra, A.; Goyal, V. Image Super-Resolution: A Comprehensive Review, Recent Trends, Challenges and Applications. Inf. Fusion 2023, 91, 230–260. [Google Scholar] [CrossRef]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Zhang, K.; Zuo, W.; Zhang, L. Learning a single convolutional super-resolution network for multiple degradations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3262–3271. [Google Scholar]
- Wang, X.; Xie, L.; Dong, C.; Shan, Y. Real-esrgan: Training real-world blind super-resolution with pure synthetic data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1905–1914. [Google Scholar]
- Bell-Kligler, S.; Shocher, A.; Irani, M. Blind super-resolution kernel estimation using an internal-gan. arXiv 2019, arXiv:1909.06581. [Google Scholar]
- Emad, M.; Peemen, M.; Corporaal, H. Dualsr: Zero-shot dual learning for real-world super-resolution. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 1630–1639. [Google Scholar]
- Kim, J.; Jung, C.; Kim, C. Dual back-projection-based internal learning for blind super-resolution. IEEE Signal Process. Lett. 2020, 27, 1190–1194. [Google Scholar] [CrossRef]
- Yuan, Y.; Liu, S.; Zhang, J.; Zhang, Y.; Dong, C.; Lin, L. Unsupervised image super-resolution using cycle-in-cycle generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 701–710. [Google Scholar]
- Fritsche, M.; Gu, S.; Timofte, R. Frequency separation for real-world super-resolution. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019; pp. 3599–3608. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Wang, D.; Zhang, Q.; Xu, Y.; Zhang, J.; Du, B.; Tao, D.; Zhang, L. Advancing plain vision transformer towards remote sensing foundation model. IEEE Trans. Geosci. Remote Sens. 2022, 61, 5607315. [Google Scholar] [CrossRef]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16000–16009. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1874–1883. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Li, Y.; Mao, H.; Girshick, R.; He, K. Exploring plain vision transformer backbones for object detection. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part IX. Springer Nature: Cham, Switzerland, 2022; pp. 280–296. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Sun, Y.; Zhi, X.; Jiang, S.; Gong, J.; Shi, T.; Wang, N. Imaging Simulation Method for Novel Rotating Synthetic Aperture System Based on Conditional Convolutional Neural Network. Remote Sens. 2023, 15, 688. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | General Meaning | Type |
|---|---|---|
| SRGAN [26] | Generative adversarial networks for image super-resolution | Explicit methods rely on external training datasets |
| EDSR [27] | Enhanced deep residual networks for image super-resolution | |
| SRMD [28] | Image super-resolution networks for multiple degradations | |
| Real-ESRGAN [29] | Real-world enhanced super-resolution generative adversarial networks | |
| KernelGAN [30] | Generative adversarial networks for kernel estimation | Explicit methods rely on internal statistics |
| DualSR [31] | Dual learning for image super-resolution | |
| DBPI [32] | Dual back-projection-based internal learning | |
| CinCGAN [33] | Cycle-in-cycle generative adversarial networks for image super-resolution | Implicit methods |
| FSSR [34] | Frequency separation for image super-resolution |
| Config | Pre-training | Fine-Tuning |
|---|---|---|
| Optimizer | AdamW [42] | |
| Base Learning Rate | 1.5 × 10−4 | 1 × 10−3 |
| Weight Decay | 0.05 | |
| Optimizer Momentum | ||
| Batch Size | 256 | 64 |
| Learning Rate Schedule | Cosine Decay [43] | |
| Scene Type | Method | Aspect Ratio 3 | Aspect Ratio 4 | Aspect Ratio 5 | Aspect Ratio 6 | Aspect Ratio 7 | Aspect Ratio 8 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | ||
| Airports | Bicubic | 28.63 | 0.8160 | 27.68 | 0.7992 | 26.87 | 0.7833 | 26.09 | 0.7677 | 25.73 | 0.7608 | 25.15 | 0.7505 |
| SRGAN | 32.46 | 0.9022 | 31.41 | 0.8802 | 30.46 | 0.8573 | 29.37 | 0.8358 | 28.82 | 0.8237 | 28.07 | 0.8084 | |
| EDSR | 32.57 | 0.9195 | 31.52 | 0.8981 | 30.54 | 0.8782 | 29.42 | 0.8555 | 28.89 | 0.8455 | 28.02 | 0.8263 | |
| SRMD | 32.47 | 0.9228 | 31.31 | 0.9027 | 30.36 | 0.8841 | 29.46 | 0.8660 | 29.04 | 0.8580 | 28.37 | 0.8462 | |
| Real-ESRGAN | 32.68 | 0.9054 | 31.79 | 0.8829 | 30.77 | 0.8570 | 29.55 | 0.8273 | 28.89 | 0.8136 | 28.04 | 0.7952 | |
| DualSR | 34.22 | 0.9517 | 32.68 | 0.9294 | 31.22 | 0.9044 | 30.02 | 0.8812 | 29.49 | 0.8709 | 28.66 | 0.8553 | |
| FSSR | 32.28 | 0.9105 | 31.07 | 0.8926 | 30.13 | 0.8763 | 29.25 | 0.8603 | 28.85 | 0.8532 | 28.20 | 0.8427 | |
| Proposed | 35.96 | 0.9584 | 34.68 | 0.9384 | 32.24 | 0.9142 | 30.40 | 0.8827 | 29.31 | 0.8745 | 28.80 | 0.8554 | |
| Harbors | Bicubic | 27.98 | 0.8351 | 26.77 | 0.8193 | 26.05 | 0.8073 | 25.41 | 0.7982 | 24.99 | 0.7914 | 24.49 | 0.7847 |
| SRGAN | 31.37 | 0.9333 | 30.11 | 0.9156 | 29.27 | 0.8997 | 28.59 | 0.8891 | 28.06 | 0.8806 | 27.53 | 0.8732 | |
| EDSR | 31.40 | 0.9409 | 30.17 | 0.9233 | 29.26 | 0.9070 | 28.62 | 0.8958 | 28.16 | 0.8907 | 27.61 | 0.8816 | |
| SRMD | 31.77 | 0.9440 | 30.30 | 0.9253 | 29.44 | 0.9111 | 28.70 | 0.9007 | 28.20 | 0.8928 | 27.63 | 0.8851 | |
| Real-ESRGAN | 30.65 | 0.9187 | 29.48 | 0.9015 | 28.72 | 0.8840 | 28.02 | 0.8723 | 27.60 | 0.8640 | 27.05 | 0.8560 | |
| DualSR | 34.55 | 0.9668 | 31.89 | 0.9438 | 30.54 | 0.9252 | 29.45 | 0.9123 | 28.82 | 0.9028 | 28.12 | 0.8936 | |
| FSSR | 32.65 | 0.9433 | 30.88 | 0.9253 | 29.84 | 0.9109 | 29.02 | 0.9009 | 28.47 | 0.8932 | 27.85 | 0.8857 | |
| Proposed | 36.38 | 0.9712 | 34.59 | 0.9544 | 31.79 | 0.9312 | 30.57 | 0.9132 | 29.39 | 0.9043 | 28.55 | 0.8941 | |
| Residential areas | Bicubic | 28.42 | 0.8031 | 27.69 | 0.7853 | 26.55 | 0.7636 | 25.81 | 0.7436 | 25.37 | 0.7326 | 24.84 | 0.7219 |
| SRGAN | 31.59 | 0.8844 | 30.59 | 0.8669 | 29.81 | 0.8394 | 29.02 | 0.8181 | 28.31 | 0.8168 | 27.73 | 0.8055 | |
| EDSR | 31.92 | 0.8948 | 31.04 | 0.8784 | 30.14 | 0.8472 | 29.30 | 0.8270 | 28.74 | 0.8213 | 28.07 | 0.7993 | |
| SRMD | 32.23 | 0.9095 | 31.34 | 0.8880 | 30.01 | 0.8626 | 29.14 | 0.8393 | 28.63 | 0.8267 | 28.01 | 0.8143 | |
| Real-ESRGAN | 32.15 | 0.8839 | 31.32 | 0.8547 | 29.85 | 0.8113 | 28.73 | 0.7794 | 28.04 | 0.7592 | 27.22 | 0.7382 | |
| DualSR | 33.92 | 0.9455 | 32.73 | 0.9216 | 30.85 | 0.8892 | 29.67 | 0.8583 | 29.03 | 0.8428 | 28.32 | 0.8279 | |
| FSSR | 32.10 | 0.9006 | 31.14 | 0.8807 | 29.88 | 0.8579 | 29.00 | 0.8362 | 28.49 | 0.8243 | 27.89 | 0.8128 | |
| Proposed | 36.36 | 0.9557 | 34.85 | 0.9408 | 31.83 | 0.9026 | 30.35 | 0.8679 | 29.52 | 0.8499 | 28.48 | 0.8316 | |
| Yards | Bicubic | 27.19 | 0.8143 | 26.31 | 0.7987 | 25.50 | 0.7833 | 24.67 | 0.7677 | 24.44 | 0.7629 | 24.03 | 0.7563 |
| SRGAN | 30.67 | 0.9140 | 29.75 | 0.8937 | 28.96 | 0.8715 | 27.86 | 0.8415 | 27.60 | 0.8453 | 26.89 | 0.8268 | |
| EDSR | 30.73 | 0.9133 | 29.80 | 0.8978 | 29.01 | 0.8786 | 27.90 | 0.8521 | 27.65 | 0.8467 | 27.04 | 0.8342 | |
| SRMD | 30.86 | 0.9212 | 29.80 | 0.9025 | 28.84 | 0.8847 | 27.87 | 0.8666 | 27.60 | 0.8612 | 27.12 | 0.8535 | |
| Real-ESRGAN | 30.22 | 0.8902 | 29.44 | 0.8692 | 28.81 | 0.8494 | 27.58 | 0.8193 | 27.33 | 0.8130 | 26.58 | 0.7963 | |
| DualSR | 32.68 | 0.9467 | 27.77 | 0.9124 | 29.67 | 0.9006 | 28.54 | 0.8808 | 28.14 | 0.8736 | 27.58 | 0.8641 | |
| FSSR | 31.37 | 0.9145 | 30.11 | 0.8969 | 29.06 | 0.8806 | 28.01 | 0.8642 | 27.70 | 0.8590 | 27.20 | 0.8519 | |
| Proposed | 35.63 | 0.9621 | 33.47 | 0.9395 | 30.87 | 0.9155 | 29.18 | 0.8836 | 28.46 | 0.8756 | 28.14 | 0.8684 | |
| Farmland | Bicubic | 32.60 | 0.8556 | 31.35 | 0.8472 | 30.74 | 0.8426 | 29.93 | 0.8367 | 29.19 | 0.8319 | 28.71 | 0.8285 |
| SRGAN | 36.33 | 0.9586 | 34.90 | 0.9505 | 34.25 | 0.9455 | 33.35 | 0.9389 | 32.58 | 0.9344 | 32.06 | 0.9309 | |
| EDSR | 36.70 | 0.9620 | 35.22 | 0.9534 | 34.49 | 0.9472 | 33.54 | 0.9406 | 32.82 | 0.9360 | 32.25 | 0.9326 | |
| SRMD | 37.05 | 0.9651 | 35.52 | 0.9553 | 34.81 | 0.9500 | 33.85 | 0.9432 | 32.98 | 0.9376 | 32.42 | 0.9338 | |
| Real-ESRGAN | 31.73 | 0.8473 | 31.71 | 0.8376 | 31.28 | 0.8308 | 30.21 | 0.8221 | 29.27 | 0.8110 | 28.75 | 0.8076 | |
| DualSR | 37.43 | 0.9717 | 35.78 | 0.9610 | 34.91 | 0.9533 | 33.88 | 0.9466 | 33.00 | 0.9410 | 32.46 | 0.9373 | |
| FSSR | 35.62 | 0.9522 | 34.29 | 0.9458 | 33.69 | 0.9411 | 32.85 | 0.9346 | 32.18 | 0.9311 | 31.70 | 0.9280 | |
| Proposed | 38.85 | 0.9766 | 37.05 | 0.9645 | 35.66 | 0.9590 | 33.25 | 0.9483 | 33.34 | 0.9430 | 31.92 | 0.9292 | |
| Forests | Bicubic | 30.30 | 0.7985 | 29.38 | 0.7772 | 28.70 | 0.7612 | 27.85 | 0.7409 | 27.24 | 0.7271 | 27.10 | 0.7237 |
| SRGAN | 33.47 | 0.8739 | 31.95 | 0.8446 | 31.07 | 0.8252 | 29.98 | 0.8008 | 29.24 | 0.7835 | 29.05 | 0.7788 | |
| EDSR | 33.65 | 0.8828 | 32.69 | 0.8533 | 31.92 | 0.8299 | 30.95 | 0.8037 | 30.14 | 0.7803 | 29.90 | 0.7706 | |
| SRMD | 34.34 | 0.9045 | 33.22 | 0.8791 | 32.43 | 0.8601 | 31.43 | 0.8364 | 30.73 | 0.8204 | 30.57 | 0.8164 | |
| Real-ESRGAN | 32.96 | 0.8610 | 32.15 | 0.8276 | 31.41 | 0.7998 | 30.47 | 0.7710 | 29.55 | 0.7402 | 29.22 | 0.7248 | |
| DualSR | 36.65 | 0.9493 | 34.52 | 0.9120 | 33.44 | 0.8892 | 32.12 | 0.8607 | 31.25 | 0.8399 | 31.00 | 0.8340 | |
| FSSR | 33.50 | 0.8797 | 32.56 | 0.8604 | 31.90 | 0.8459 | 31.01 | 0.8265 | 30.37 | 0.8129 | 30.22 | 0.8100 | |
| Proposed | 38.04 | 0.9530 | 36.33 | 0.9313 | 34.48 | 0.9005 | 32.39 | 0.8650 | 31.50 | 0.8427 | 31.19 | 0.8341 | |
| Scene Type | Method | Aspect Ratio 3 | Aspect Ratio 4 | Aspect Ratio 5 | Aspect Ratio 6 | Aspect Ratio 7 | Aspect Ratio 8 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | ||
| Average | Bicubic | 29.19 | 0.8204 | 28.20 | 0.8045 | 27.40 | 0.7902 | 26.63 | 0.7758 | 26.16 | 0.7678 | 25.72 | 0.7609 |
| SRGAN | 32.65 | 0.9111 | 31.45 | 0.8919 | 30.64 | 0.8731 | 29.70 | 0.8540 | 29.10 | 0.8474 | 28.55 | 0.8373 | |
| EDSR | 32.83 | 0.9189 | 31.74 | 0.9007 | 30.89 | 0.8813 | 29.95 | 0.8624 | 29.40 | 0.8534 | 28.64 | 0.8408 | |
| SRMD | 33.12 | 0.9278 | 31.91 | 0.9088 | 30.98 | 0.8921 | 30.07 | 0.8754 | 29.53 | 0.8661 | 29.02 | 0.8582 | |
| Real-ESRGAN | 31.73 | 0.8844 | 30.98 | 0.8622 | 30.14 | 0.8387 | 29.09 | 0.8152 | 28.45 | 0.8002 | 27.81 | 0.7864 | |
| DualSR | 34.91 | 0.9553 | 32.56 | 0.9300 | 31.77 | 0.9103 | 30.61 | 0.8900 | 29.95 | 0.8785 | 29.36 | 0.8687 | |
| FSSR | 32.92 | 0.9168 | 31.68 | 0.9003 | 30.75 | 0.8854 | 29.86 | 0.8705 | 29.34 | 0.8623 | 28.85 | 0.8552 | |
| Proposed | 36.87 | 0.9628 | 35.16 | 0.9448 | 32.81 | 0.9205 | 31.02 | 0.8935 | 30.25 | 0.8817 | 29.51 | 0.8688 | |
| Training Method | One-Stage | Two-Stage-Random Mask | Two-Stage-Strip Mask |
|---|---|---|---|
| PSNR | 32.07 | 31.91 | 32.61 |
| SSIM | 0.9038 | 0.9024 | 0.9120 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Y.; Zhi, X.; Jiang, S.; Shi, T.; Song, J.; Yang, J.; Wang, S.; Zhang, W. Single-Image Super-Resolution Method for Rotating Synthetic Aperture System Using Masking Mechanism. Remote Sens. 2024, 16, 1508. https://0-doi-org.brum.beds.ac.uk/10.3390/rs16091508
Sun Y, Zhi X, Jiang S, Shi T, Song J, Yang J, Wang S, Zhang W. Single-Image Super-Resolution Method for Rotating Synthetic Aperture System Using Masking Mechanism. Remote Sensing. 2024; 16(9):1508. https://0-doi-org.brum.beds.ac.uk/10.3390/rs16091508
Chicago/Turabian StyleSun, Yu, Xiyang Zhi, Shikai Jiang, Tianjun Shi, Jiachun Song, Jiawei Yang, Shengao Wang, and Wei Zhang. 2024. "Single-Image Super-Resolution Method for Rotating Synthetic Aperture System Using Masking Mechanism" Remote Sensing 16, no. 9: 1508. https://0-doi-org.brum.beds.ac.uk/10.3390/rs16091508