1. Introduction
The global demand for energy is facing significant challenges and uncertainties, manifested by the decrease in fossil energy reserves and rising prices [
1]. Moreover, the burning of fossil energy sources emits large amounts of carbon dioxide, which leads to atmospheric pollution [
2]. As a result, countries are turning to renewable energy sources, particularly solar energy due to its universality, harmlessness, and immensity and permanence [
3].
According to the International Energy Agency’s (IEA) sustainability program, the number of photovoltaic (PV) plants will increase rapidly, taking up much land [
4]. However, potential problems can be induced during the process of PV industry development, such as competition for land with PV deployment due to increased human activity and damage to biodiversity and the climate due to land change in PV regions [
5]. Consequently, the accurate geo-spatial location of PVs is critical for assessing past impacts and planning to avoid future conflicts.
With the development of satellite sensor technology, many remote-sensing images have been acquired for PV extraction. PV panels can be detected and segmented from remote-sensing images by designing representative features (e.g., color, geometry, and texture) using the threshold segmentation algorithm [
6,
7], the edge detection algorithm [
8,
9], or the SVM algorithm in machine learning [
10,
11]. However, these features vary due to the atmospheric conditions, lighting, and observation scales, resulting in weak accuracy and the generalization of traditional methods [
12,
13]. Moreover, PV plants have been built in various landscapes (e.g., deserts, mountains, and coasts) [
14,
15,
16]. This makes it challenging to accurately identify PVs on a continental scale. Therefore, more than the traditional method is required to cope with these situations [
17].
Deep learning (DL) has been favored in view of its success in object detection and segmentation for remote-sensing areas [
18,
19]. Many researchers began using convolutional neural networks (CNNs) for scene classification, crop yield prediction, and land cover, among other jobs [
20,
21,
22]. For PV extraction, several CNNs were used to localize PVs from remote-sensing images and estimate their sizes [
23,
24,
25,
26]. For example, Yuan et al. [
27] completed large-scale PV segmentation based on CNNs. Jumaboev et al. [
28] compared the PV segmentation effect of deeplabv3+, FPN, and U-Net. However, the above studies focused on using the original DL models without analyzing the characteristics of PV image or improving the models. Therefore, there is a gap in further improving DL methods’ segmentation accuracy and robustness (i.e., the adaptive model design and data combination).
In recent years, the development of computer hardware and remote-sensing technology [
29,
30,
31] has provided a solid foundation for large-scale PV mapping (e.g., global, regional) [
17,
32]. Based on this, we need to design the CNN model to acquire PV features from multi-source remote-sensing images adaptively, in order to complete PV extraction from different regions and scales [
6,
33,
34]. In addition, attention is used to observe crucial local information and combine it with information from other regions to form an overall understanding of the object, thereby enhancing the feature extraction ability. Currently, attention is extensively employed in DL models for remote-sensing image processing to make the model adaptive in acquiring the critical features of the object [
35,
36,
37].
Previous methods have been primarily focused on PV extraction from a single data source and have achieved impressive performance. However, these methods are insufficient to cope with the multi-sourcing of remote-sensing images. The above literature has not widely analyzed the cross-scale extraction of PVs from multi-source images. This study examined the current mainstream CNN models. Many researchers have compared U-Net, DeepLabv3+, PSPNet, and HRNet models on the PASCAL VOC 2012 dataset, and HRNet achieved the best performance [
38,
39]. Therefore, we selected HRNet as the base model and embedded Canny, Median filter, and Polarized Self-Attention (PSA) to design an adaptive FEPVNet. We tested the effectiveness of FEPVNet in PV extraction from Sentinel-2 images and conducted cross-validation using different PV region models. Finally, we constructed three data migration strategies by combining multi-source data and employed the model trained on Sentinel-2 images for PV extraction from Gaofen-2 images, and its Precision reached 94.37%. Our cross-scale PV extraction method is expected to contribute to the large-scale mapping of PV in the future.
The rest of the paper is organized as follows:
Section 2 presents the dataset used.
Section 3 presents the experimental methodology of this study.
Section 4 presents the experimental results of this paper.
Section 5 and
Section 6 present the discussion and conclusions of this paper.
2. Datasets
To construct the cross-scale network model, four types of images are required: a Sentinel-2 image at a 10 m resolution, which is available for download via Google Earth Engine (GEE), a Google-14 (i.e., zoom level is 14) image at a 10 m resolution, a Google-16 (i.e., zoom level is 16) image at a 2 m resolution, all of which can be downloaded through the Google Images’ API, and a Gaofen-2 image at a 2 m resolution, which can be downloaded from the Data Sharing Website of Aerospace Information Research Institute, Chinese Academy of Sciences. Therefore, we first validated the FEPVNet performance using the Sentinel-2 images, then constructed three data migration strategies using the Sentinel-2 and Google images, and finally completed the PV extraction from the Goafen-2 images.
We utilized the PV location information from the open-source global PV installation list [
32] to select the vector sample with PVs. The above four categories of raster images were downloaded according to the boundaries of these vector samples, and the vector samples were transformed into PV labels of the corresponding category. The labels with incorrect PV boundaries were redrawn using LabelMe. The sample images of Sentinel-2 that we used consist of three bands: red (B4), green (B3), and blue (B2), while the sample label images are grayscale images. These images were cut into 1024 × 1024 pixels, forming four datasets with properties shown in
Table 1. The dataset was divided into three parts, one training set, one validation set, and one test set. The results were poor when training the model on Sentinel-2 images and directly extracting PVs from Gaofen-2 images. Therefore, we consider combining multiple PV features to complete the transfer work of the Sentinel-2 model. We aimed to utilize the images from Sentinel-2 and Google of different resolutions to perform cross-scale PV extraction in Gaofen-2 imagery without using Gaofen-2 imagery to train the model. As a result, only the training set of Google images was needed. For model training, we used Gaofen-2 imagery as the validation set and test set. Thus, Google images did not require validation and test sets, and Gaofen-2 imagery did not need a training set. Finally, we used data augmentation such as rotation, color transformation, and noise injection to augment the dataset.
3. Methodology
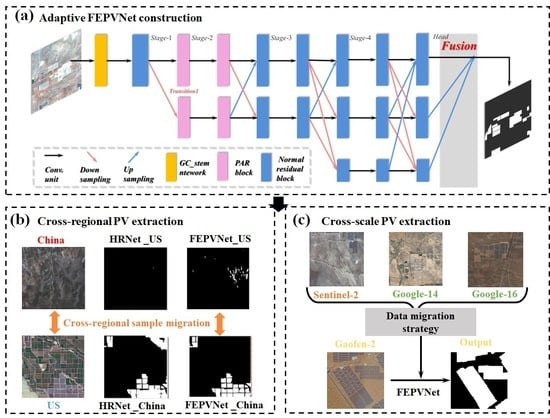
The methodology framework consists of five parts as shown in
Figure 1: (a) completing the PV dataset by converting the vector samples into labels for the multi-source images, (b) validating the advantages of our improved module through ablation experiments of FEPVNet, (c) comparing the PV extraction ability of different models on the Sentinel-2 dataset, (d) using FEPVNet for cross-validation of the Sentinel-2 images in different regions, and (e) completing a PV cross-scale extraction from multi-source remote-sensing images using FEPVNet and the migration strategy.
3.1. Proposal of a Filter-Embedded Neural Network
As shown in
Figure 2, HRNet comprises a stem network for initial feature extraction and a multi-scale resolution main body network. The main body network contains four stages, each using residual blocks to extract features. At the end of each stage, a Transition branch is added, where the output features are downsampled by a factor of two, and the channels are expanded by a factor of two. Finally, the head uses bilinear interpolation to upsample the low-resolution feature maps and connects the completed upsample feature maps to the output predicted binarized maps.
Several modifications were made to improve the HRNet model, including adding high-low pass filtering, polarized parallel attention, and a deep separable convolution. Four different stem networks were constructed: LG_stem, which combines Laplacian and Gaussian filters, SG_stem, which combines Sobel and Gaussian filters, CG_stem, which combines Canny and Gaussian filters, and CM_stem, which combines Canny and Median filters. In addition, the Polarized Self-Attention–residual (PAR), Single Depthwise Separable (SDS) residual and Double Depthwise Separable (DDS) residual blocks were constructed to replace the standard residual blocks at different stages of the HRNet main network. The performance of these modules was evaluated on Sentinel-2 images in terms of efficiency, Precision, Recall, F1-score, and Intersection over Union (IoU) to determine the best configuration for our model.
The best-performing FEPVNet model embedded the Canny and Median filter into the stem and replaced the normal residual block in the second stage using the PAR. Considering that FEPVNet has a large number of parameters, we used an SDS block to replace the normal residual block, which dramatically reduced the number of parameters and improved the computational efficiency, and this model was named FESPVNet.
3.1.1. Stem Network Embedded Filtering
When an image is input into the HRNet model, it is initially processed by the stem network, which consists of two stride-2 3 × 3 convolutions, resulting in a feature map that is 1/4 the size of the original image. The architecture of the stem network utilized in HRNet is depicted in
Figure 3a.
To enhance the stem network’s capability for an adaptive extraction of the boundary features, we constructed the high-pass filter (HPF) residual structure depicted in the left half of
Figure 3b. This was achieved by using traditional computer vision methods such as Canny [
40], Sobel [
41], and Laplacian [
42] high-pass filters. We then embedded these filters into the stem network so that the network could obtain images containing edge features. Next, we embedded low-pass filters, such as Gaussian and Median [
43,
44], into the stem network. as shown in the right half of
Figure 3b, to filter out the noise in the feature maps. Finally, we experimented with combining the above filters and determined that it was optimal to embed the Canny and Median filters into the stem network.
The following are the steps for edge detection by Canny:
- 1.
To perform the image smoothing, a Gaussian filter with a two-dimensional Gaussian kernel is used to carry out a convolution calculation to complete a weighted average of the image. This process is effective in filtering out the high-frequency noise in the image. The calculation process is as follows:
- 2.
The edges are determined based on the image’s gradient amplitude and gradient direction. Here, the gradient amplitude and direction are calculated using the Sobel operator for the image with the following equation:
- 3.
To remove the non-boundary points, non-maximum suppression is applied to the entire image. This is achieved by calculating the amplitude of each pixel point relative to the gradient direction, comparing the amplitudes of pixel points with the same gradient direction, and retaining only those with the highest amplitude in the same direction. The remaining pixel points are then eliminated.
- 4.
To detect the edges, we employ the double threshold algorithm. We define strong and weak thresholds by setting pixel points with gradient values below the weak threshold to 0 and those exceeding the strong threshold to 255. For pixel points whose gradient values fall between the strong and weak thresholds, we keep pixel points whose eight neighborhoods are larger than the strong threshold and set them to 255, while the rest are assigned a value of 0. These points are then connected to form the object’s edges.
The edge-enhanced images obtained by the HPF still contain noise, which can affect the main body network’s feature extraction ability. However, a Median filter can mitigate this issue. The Median filter is a non-linear filtering method based on a statistical theory that can remove isolated noise while retaining the complete edge information of the image. Its principle is to replace the gray value of a point in the image with the median of the gray value of each point in the neighborhood of that point, so that the value of the pixel point in the domain is close to the actual value. The process can be summarized as follows:
- 1.
Slide the filter window across the image, with the center of the window overlapping the position of a pixel in the image.
- 2.
Obtain the gray value of the corresponding pixel in this window.
- 3.
Sort the grayscale values obtained from smallest to largest and find the median value in the middle of the sorted list.
- 4.
Assign the median value to the pixel at the window’s center.
3.1.2. The Main Body Network Adaptability Improvements
The
PSA [
45] mechanism adds channel attention to the self-attention mechanism based on a single spatial dimension, enabling a refined feature extraction. In this work, we use the parallel
PSA, which consists of a channel branch and a spatial branch computed in parallel and then summed up, as shown in
Figure 4. The calculation formula is as follows:
The Channel branch converts the input features
X into Q and V using a 1 × 1 convolution. Firstly, the number of channels for Q is completely compressed to 1, and the number of channels for V becomes C/2. Since the number of channels of Q is compressed, it uses the High Dynamic Range (HDR) to enhance information by increasing the attention range for Q using the softmax function. Then Q and V are multiplied to obtain Z, and the number of Z channels is increased from C/2 to C by connecting 1 × 1 convolution and LayerNorm. Finally, the sigmoid function restricts Z between 0 and 1. The calculation formula is as follows:
The spatial branch uses a 1 × 1 convolution to convert the input features into Q and V. Global pooling is used to compress Q in the spatial dimension to a size of 1 × 1. In contrast, V’s spatial dimension remains H × W. As Q’s spatial dimension is compressed, Q’s information is augmented using softmax. The feature obtained by matrix multiplication of Q and V is reshaped 1 × H × W and converted the values to between 0 and 1 using sigmoid. The calculation formula is as follows:
The PSA minimizes information loss by avoiding significant compression in both the spatial and channel dimensions. Additionally, traditional attention methods estimate the probability using only softmax or non-linear sigmoid functions. In contrast, the PSA combines softmax and sigmoid functions in both channel and spatial branches to fit the output distribution of fine-grained regression results. Therefore, the PSA can effectively extract the features of fine-grained targets.
In this study, we use the parallel PSA to improve the basic residual convolution block construct the polarized attention residual block (PAR), and employ it in stage 2, stage 3, and stage 4 of the HRNet main body network. In addition, we experimentally determine the additional position of the PAR in each stage.
Figure 5 illustrates the normal convolution operation. By performing N 3 × 3 convolution calculations on the H × W × C feature map, an H × W × N feature map can be output. The parameters for this operation can be calculated as follows:
Howard et al. [
46] proposed a decomposable convolution operation called Depthwise Separable Convolution, as shown in
Figure 6. This operation splits the above normal convolution into a 3 × 3 × C depthwise convolution and n 1 × 1 × C Pointwise convolution. The following parameter quantities are calculated:
By dividing the above two Equations (9) and (10), we can obtain the following results:
From the above Equation (10), it can be observed that replacing the normal 3 × 3 convolution with the Depthwise Separable Convolution reduces the number of parameters in the replaced part by 1/8~1/9 of the original, leading to significant improvements in the computational efficiency and a lighter network. Therefore, in this study, we use the Depthwise Separable Convolution to replace the basic residual convolution block in
Figure 7a, constructing two kinds of deep convolution residual blocks, as follows:
- 1.
A SDS residual block, as shown in
Figure 7c, where two normal convolutions are replaced by depth convolution and point convolution.
- 2.
A DDS residual block, as shown in
Figure 7d, where two Depthwise Separable Convolutions are used to replace two normal convolutions.
We used SDS and DDS for stage 2, stage 3, and stage 4 of the HRNet main body, respectively. Through the experiments, we found that SDS outperformed the normal residual block in stage 4.
3.2. Evaluation of the Model Adaptability
Figure 1c shows that the FEPVNet model was employed for cross-validation to verify its ability to adaptively extract PVs from different regions. Specifically, we trained the FEPVNet model with the Sentinel-2 China dataset to extract PVs from the US region and vice versa.
To enhance the generalizability of the Sentinel-2 image model in multi-source images and facilitate its migration for use in high-resolution image models, we compared four methods illustrated in
Figure 1d, which include three image migration strategies. These methods consist of training the model with the Sentinel-2 dataset, mixing Sentinel-2 images with Google-14 images in a 1:1 ratio to form the dataset training model, mixing Sentinel-2 images with Google-16 images in a 1:1 ratio to form the dataset training model, and mixing Sentinel-2 images with Google-14 and Google-16 images in a 1:1:2 to form the dataset training model. We then used these methods to extract PVs from the Gaofen-2 image.
3.3. Evaluation Metrics
To evaluate the results of PV extraction, we utilized four metrics, namely Precision, Recall, F1-score, and IoU. The calculations for these metrics can be completed using the following equations:
In the above Equations (11)–(14), TP represents a positive sample judged as positive, FP represents a negative sample judged as a positive, FN represents a positive sample judged as negative, and TN represents a negative sample judged as negative.
5. Discussion
In previous studies of PV extraction, some traditional methods and un-optimized CNNs [
21,
22,
23,
24] have been used for PV extraction from a single data source, achieving good results but with poor generalization. Although Kruitwagen et al. [
32] achieved PV extraction from multiple sources of images with the same resolution, cross-scale PV extraction has not been completed. Based on the deficiencies in the above research, we conducted a model of experiments using Sentinel-2 images to build FEPVNet. We combined Sentinel-2 and Google images to construct three data migration strategies to complete PV extraction from Gaofen-2 images.
Given that previous methods have difficulty extracting small features at the edge of PV panels and that image noise significantly influenced the extraction results, we embedded Canny and Median filters into the stem to construct the CM_stem. As shown in the prediction results in the last column of
Figure 8, the above improvements effectively enhanced the model’s edge extraction ability and anti-noise. To enhance the adaptive capability of the model, we constructed PAR using PSA to replace the noraml residual block and determined through ablation experiments which should be used in stage 2 of the main body network, as shown in the best ablation experiment result in the third column of
Figure 9. Finally, we combined the CM_stem and PAR to propose the adaptive FEPVNet. To reduce the number of parameters and improve the computational efficiency, we used the SDS module to replace the normal residual block in stage 4 of FEPVNet and named this model FESPVNet. After significantly reducing the number of model parameters, the loss of each evaluation metric was less than 0.5%, indicating that our method achieved a good balance between model accuracy and computational cost.
Furthermore, to demonstrate the adaptive capability of FEPVNet for PV extraction, we conducted cross-validation of HRNet and FEPVNet. The quantitative evaluation metrics are shown in
Table 5. As the results show, the evaluation metrics of the prediction results of both models have declined. The imbalance in the number of training images available from the different regions can affect the model’s learning of photovoltaic features and its prediction of photovoltaic results, which is difficult to avoid in deep learning training completely. Under the fixed data source, appropriate over- or undersampling strategies, weight updating strategies, or weighted loss functions may be adopted to improve the adverse effects caused by this problem. In addition, the decline in evaluation indicators in cross-validation results is also affected by regional differences. For example, as shown in
Figure 14, the landscapes in Chinese images are more straightforward than those in the US, and the colors of the images are also significantly different (e.g., the green PV area and the yellow circle in the figure). The difference in the data itself may require some image pre-processing or post-processing strategies to reduce the impact while also placing higher demands on the model’s generalization ability. Nevertheless, in cross-validation, the performance of FEPVNet was still superior to that of HRNet, indicating that our method has a high PV extraction accuracy and good generalization ability to cope with different regional data.
Finally, we compared the PV cross-scale extraction results of three migration strategies and two models (i.e., HRNet and FEPVNet), and the quantitative evaluation metrics are shown in
Table 6. The FEPVNet model combined with the optimal migration strategy of mixing Sentinel-2 and Google-16 images can accurately extract photovoltaic information from Gaofen-2 satellite images. This study has positive implications for large-scale PV mapping and can provide accurate PV geospatial information for those who need it.
6. Conclusions
The primary purpose of this study is to propose a cross-scale PV mapping method based on the FEPVNet model, which is used to extract photovoltaic regions from multiple sources of images adaptively. For experiments, four datasets were constructed using global PV vector samples from Sentinel-2, Google-14, Google-16, and Gaofen-2.
To enhance the anti-noise edge information extraction and high-dimensional local feature extraction capabilities of the network, we embedded Canny, Median filter, and PSA into HRNet to construct the FEPVNet model. Subsequently, we conducted comparative experiments and cross-validation experiments on the Sentinel-2 dataset. The results of the comparative experiments show that compared to classical methods such as U-Net and HRNet, FEPVNet has a higher PV extraction accuracy. Furthermore, in the cross-validation experiments with different regional images, FEPVNet mitigated the impact of training data imbalance and regional differences on PV extraction compared to HRNet. Finally, we used the data migration strategies to enable the FEPVNet model trained on Sentinel-2 images to extract PVs across scales in Gaofen-2 images, with Precision and F1-score reaching 94.37% and 91.42%, respectively, which demonstrates the effectiveness of our method.
The main contribution of this study is to construct an adaptive Filter-Embedded Network (i.e., FEPVNet) and data migration strategies to accomplish the cross-scale mapping of PV panels from multi-source images. In the future, we will investigate the model’s ability to extract other types of PV, such as rooftop photovoltaics, and its applicability to other remote-sensing images. We will also use the cross-scale PV extraction method proposed in this study to complete regional or national-scale PV mapping.


 ,
, 















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}