
Advancing Spatial Drought Forecasts by Integrating an Improved Outlier Robust Extreme Learning Machine with Gridded Data: A Case Study of the Lower Mainland Basin, British Columbia, Canada



Abstract
:1. Introduction
- The efficacy of IORELM for drought forecasting: This represents the first application of IORELM to droughts in British Columbia, marking a significant step forward.
- Optimal input combinations: Analyzing various combinations based on MSDI parameters ensures the most reliable model is chosen, leading to improved prediction accuracy.
- Gridded reanalysis data in drought forecasting: This innovative approach has the potential to enhance prediction capabilities further.
2. Materials and Methods
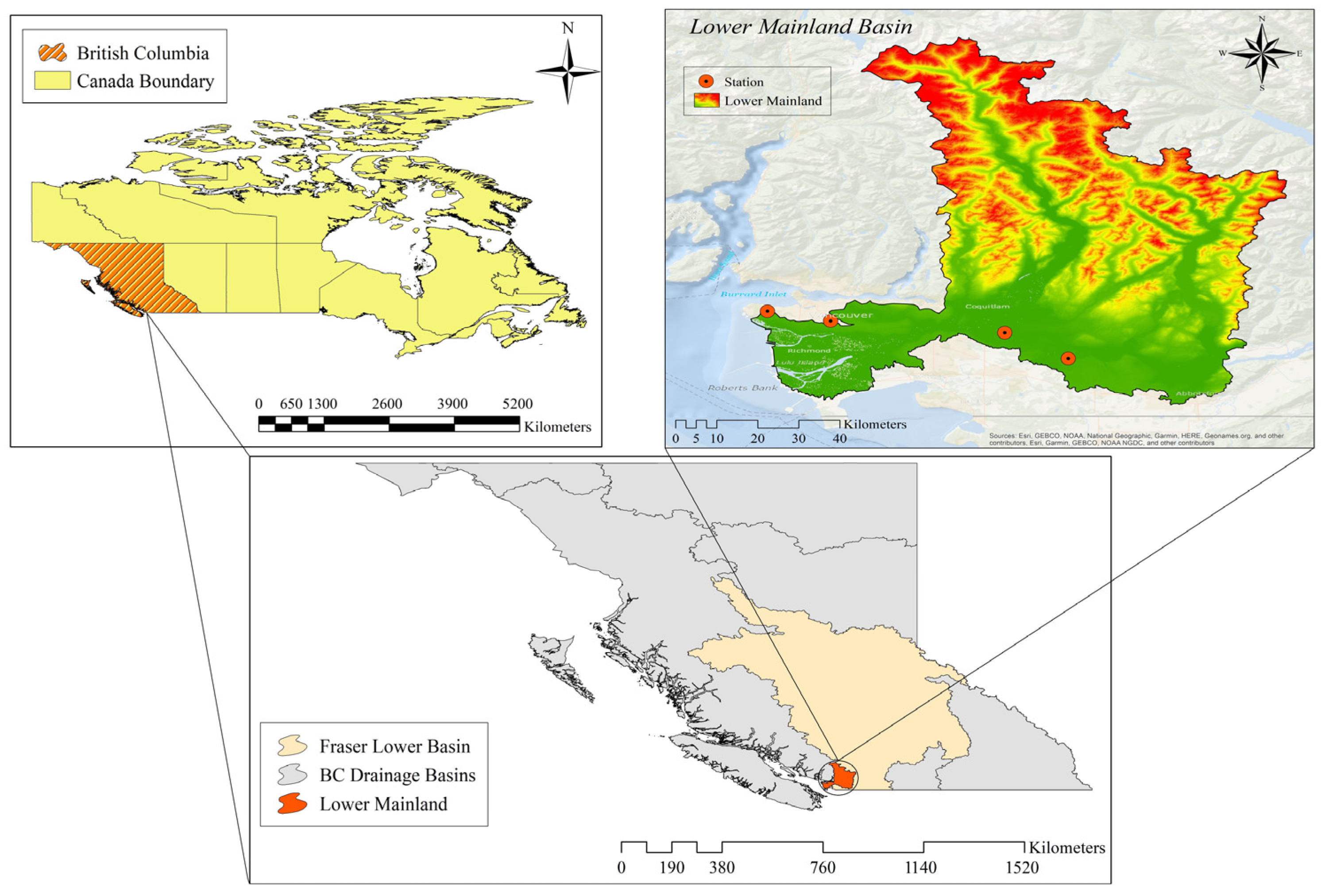
2.1. Study Area
2.2. Data Acquisition
2.3. Downscaling of Gridded Data
2.4. The Multivariate Standardized Drought Index (MSDI)
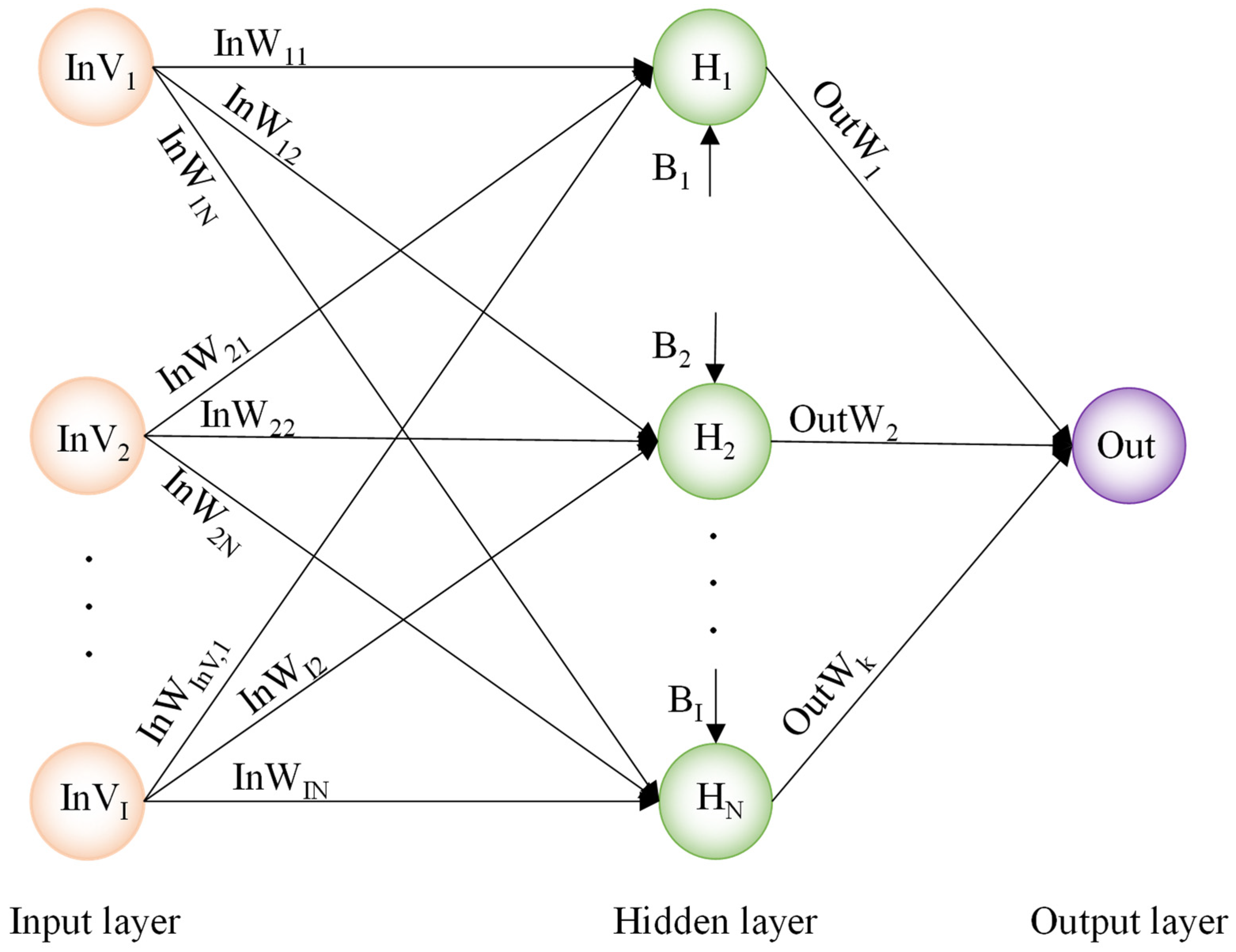
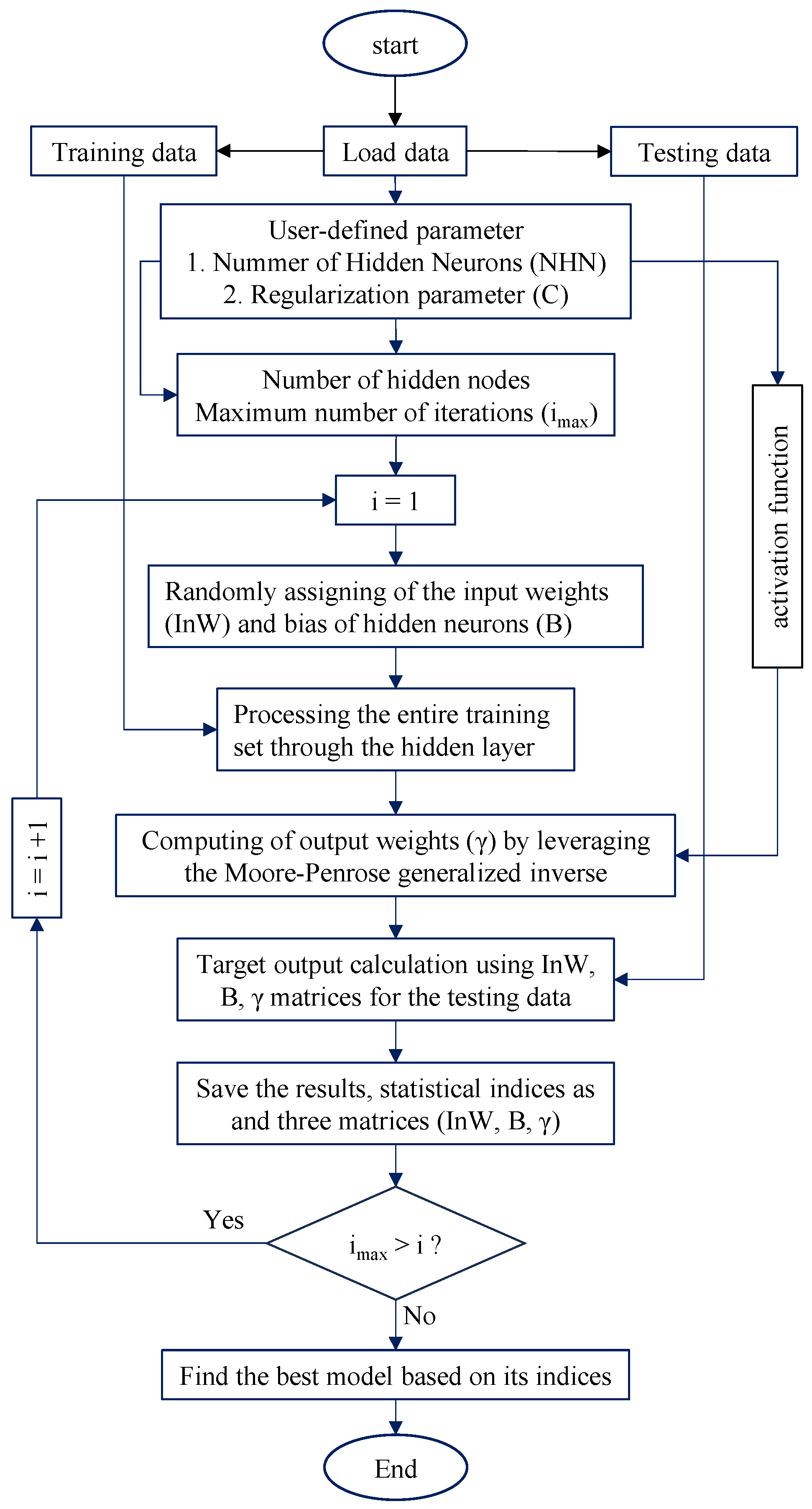
2.5. Improved Outlier Robust Extreme Learning Machine (IORELM)
2.6. Metrics for Assessing the Performance of Methods
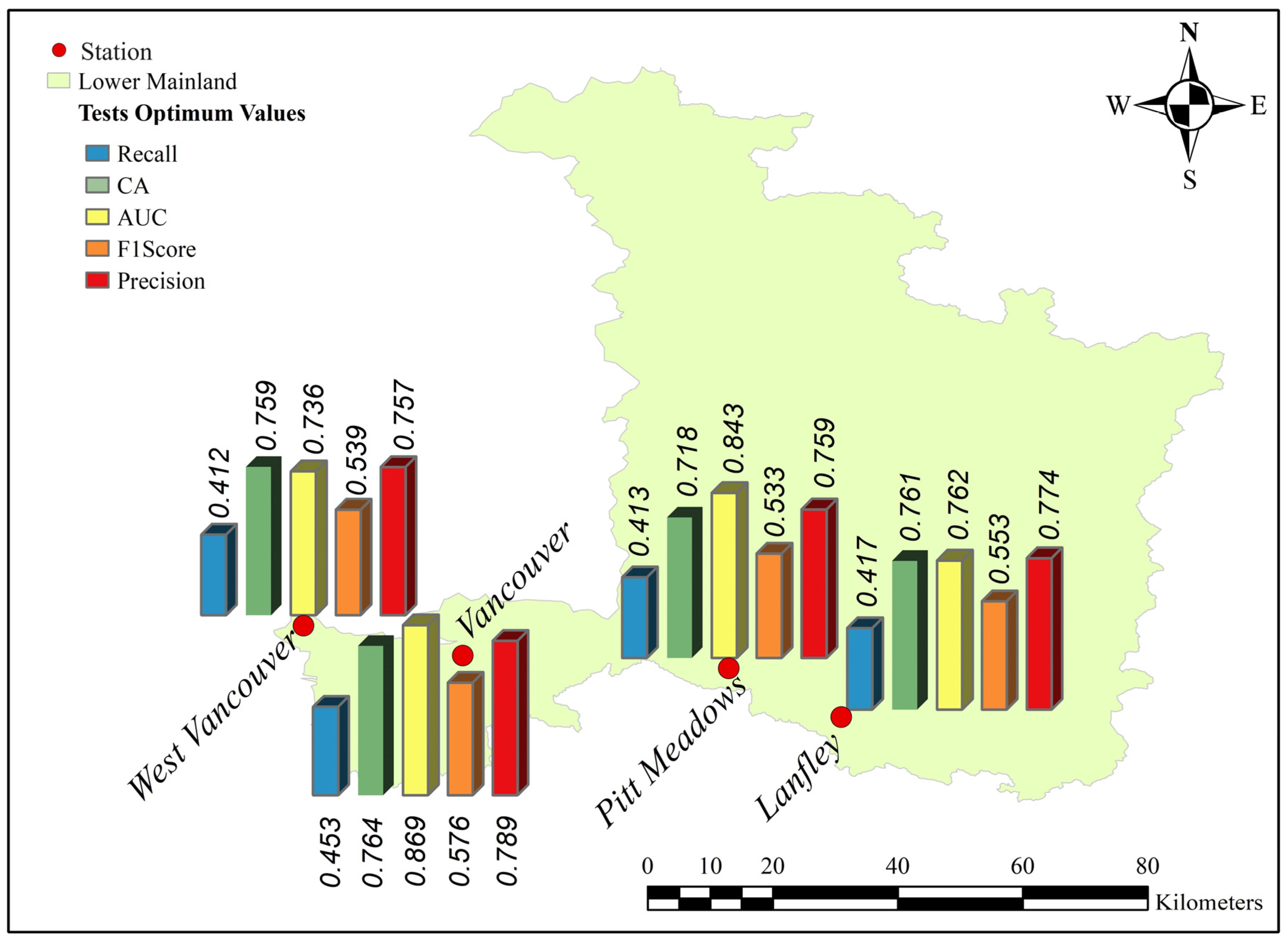
3. Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Orimoloye, I.R.; Belle, J.A.; Orimoloye, Y.M.; Olusola, A.O.; Ololade, O.O. Drought: A common environmental disaster. Atmosphere 2022, 13, 111. [Google Scholar] [CrossRef]
- Salimi, A.; Ghobrial, T.; Bonakdari, H. Comparison of the Performance of CMIP5 and CMIP6 in the Prediction of Rainfall Trends, Case Study Quebec City. Environ. Sci. Proc. 2023, 25, 42. [Google Scholar] [CrossRef]
- Wang, L.; Jiao, W.; MacBean, N.; Rulli, M.C.; Manzoni, S.; Vico, G.; D’Odorico, P. Dryland productivity under a changing climate. Nat. Clim. Chang. 2022, 12, 981–994. [Google Scholar] [CrossRef]
- Marengo, J.A.; Galdos, M.V.; Challinor, A.; Cunha, A.P.; Marin, F.R.; Vianna, M.D.S.; Alvala, R.C.; Alves, L.M.; Moraes, O.L.; Bender, F. Drought in Northeast Brazil: A review of agricultural and policy adaptation options for food security. Clim. Resil. Sustain. 2022, 1, e17. [Google Scholar] [CrossRef]
- Ndayiragije, J.M.; Li, F. Effectiveness of drought indices in the assessment of different types of droughts, managing and mitigating their effects. Climate 2022, 10, 125. [Google Scholar] [CrossRef]
- AghaKouchak, A.; Pan, B.; Mazdiyasni, O.; Sadegh, M.; Jiwa, S.; Zhang, W.; Love, C.A.; Madadgar, S.; Papalexiou, S.M.; Davis, S.J.; et al. Status and prospects for drought forecasting: Opportunities in artificial intelligence and hybrid physical–statistical forecasting. Philos. Trans. R. Soc. A 2022, 380, 20210288. [Google Scholar] [CrossRef]
- Abozari, N.; Hassanvand, M.; Salimi, A.H.; Heddam, S.; Mohammadi, H.O.; Noori, A. Comparison performance of artificial neural network based method in estimation of electric conductivity in wet and dry periods: Case study of Gamasiab river, Iran. J. Appl. Res. Water Wastewater 2019, 6, 88–94. [Google Scholar]
- Dewitte, S.; Cornelis, J.P.; Müller, R.; Munteanu, A. Artificial intelligence revolutionises weather forecast, climate monitoring and decadal prediction. Remote Sens. 2021, 13, 3209. [Google Scholar] [CrossRef]
- Singh, S.; Goyal, M.K. Enhancing climate resilience in businesses: The role of artificial intelligence. J. Clean. Prod. 2023, 418, 138228. [Google Scholar] [CrossRef]
- Sundararajan, K.; Garg, L.; Srinivasan, K.; Bashir, A.K.; Kaliappan, J.; Ganapathy, G.P.; Selvaraj, S.K.; Meena, T. A contemporary review on drought modeling using machine learning approaches. CMES-Comput. Model. Eng. Sci. 2021, 128, 447–487. [Google Scholar] [CrossRef]
- Rad, A.M.; Ghahraman, B.; Khalili, D.; Ghahremani, Z.; Ardakani, S.A. Integrated meteorological and hydrological drought model: A management tool for proactive water resources planning of semi-arid regions. Adv. Water Resour. 2017, 107, 336–353. [Google Scholar] [CrossRef]
- Dikshit, A.; Pradhan, B.; Alamri, A.M. Temporal hydrological drought index forecasting for New South Wales, Australia using machine learning approaches. Atmosphere 2020, 11, 585. [Google Scholar] [CrossRef]
- Zhang, R.; Chen, Z.Y.; Xu, L.J.; Ou, C.Q. Meteorological drought forecasting based on a statistical model with machine learning techniques in Shaanxi province, China. Sci. Total Environ. 2019, 665, 338–346. [Google Scholar] [CrossRef] [PubMed]
- Achite, M.; Jehanzaib, M.; Elshaboury, N.; Kim, T.W. Evaluation of machine learning techniques for hydrological drought modeling: A case study of the Wadi Ouahrane basin in Algeria. Water 2022, 14, 431. [Google Scholar] [CrossRef]
- Li, J.; Wang, Z.; Wu, X.; Xu, C.Y.; Guo, S.; Chen, X.; Zhang, Z. Robust meteorological drought prediction using antecedent SST fluctuations and machine learning. Water Resour. Res. 2021, 57, e2020WR029413. [Google Scholar] [CrossRef]
- Mohamadi, S.; Sammen, S.S.; Panahi, F.; Ehteram, M.; Kisi, O.; Mosavi, A.; Ahmed, A.N.; El-Shafie, A.; Al-Ansari, N. Zoning map for drought prediction using integrated machine learning models with a nomadic people optimization algorithm. Nat. Hazards 2020, 104, 537–579. [Google Scholar] [CrossRef]
- Nabipour, N.; Dehghani, M.; Mosavi, A.; Shamshirband, S. Short-term hydrological drought forecasting based on different nature-inspired optimization algorithms hybridized with artificial neural networks. IEEE Access 2020, 8, 15210–15222. [Google Scholar] [CrossRef]
- Government of British Columbia. Government of British Columbia. Available online: https://www2.gov.bc.ca/ (accessed on 21 September 2023).
- Kalnay, E.; Kanamitsu, M.; Kistler, R.; Collins, W.; Deaven, D.; Gandin, L.; Iredell, M.; Saha, S.; White, G.; Woollen, J.; et al. The NCEP/NCAR 40-Year Reanalysis Project. Bull. Am. Meteorol. Soc. 1996, 77, 437–471. [Google Scholar] [CrossRef]
- National Centers for Environmental Prediction/National Weather Service/NOAA/U.S. Department of Commerce: NCEP GFS 0.25 Degree Global Forecast Grids Historical Archive; Research Data Archive at the National Center for Atmospheric Research; Computational and Information Systems Laboratory: Boulder, CO, USA, 2015. [CrossRef]
- Simmons, H.L.; Powell, B.S.; Merrifield, S.T.; Zedler, S.E.; Colin, P.L. Dynamical downscaling. Oceanography 2019, 32, 84–91. [Google Scholar] [CrossRef]
- Hao, Z.; AghaKouchak, A. Multivariate standardized drought index: A parametric multi-index model. Adv. Water Resour. 2013, 57, 12–18. [Google Scholar] [CrossRef]
- Hao, Z.; AghaKouchak, A. A nonparametric multivariate multi-index drought monitoring framework. J. Hydrometeorol. 2014, 15, 89–101. [Google Scholar] [CrossRef]
- Hao, Z.; AghaKouchak, A.; Nakhjiri, N.; Farahmand, A. Global integrated drought monitoring and prediction system. Sci. Data 2014, 1, 140001. [Google Scholar] [CrossRef] [PubMed]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: A new learning scheme of feedforward neural networks. In Proceedings of the 2004 IEEE International Joint Conference on Neural Networks (IEEE Cat. No. 04CH37541), Budapest, Hungary, 25–29 July 2004; Volume 2, pp. 985–990. [Google Scholar]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Wang, J.; Lu, S.; Wang, S.H.; Zhang, Y.D. A review on extreme learning machine. Multimed. Tools Appl. 2022, 81, 41611–41660. [Google Scholar] [CrossRef]
- Manoharan, J. Samuel. Study of variants of extreme learning machine (ELM) brands and its performance measure on classification algorithm. J. Soft Comput. Paradig. (JSCP) 2021, 3, 83–95. [Google Scholar]
- Adnan, R.M.; Mostafa, R.R.; Kisi, O.; Yaseen, Z.M.; Shahid, S.; Zounemat-Kermani, M. Improving streamflow prediction using a new hybrid ELM model combined with hybrid particle swarm optimization and grey wolf optimization. Knowl.-Based Syst. 2021, 230, 107379. [Google Scholar] [CrossRef]
- Bonakdari, H.; Ebtehaj, I.; Ladouceur, J.D. Machine Learning in Earth, Environmental and Planetary Sciences (Theoretical and Practical Applications); Elsevier: Amsterdam, The Netherlands, 2023; ISBN 9780443152849. [Google Scholar]
- Rajpal, S.; Agarwal, M.; Rajpal, A.; Lakhyani, N.; Saggar, A.; Kumar, N. Cov-elm classifier: An extreme learning machine based identification of COVID-19 using chest x-ray images. Intell. Decis. Technol. 2022, 16, 193–203. [Google Scholar] [CrossRef]
- Bartlett, P.L. For valid generalization the size of the weights is more important than the size of the network. Adv. Neural Inf. Process. Syst. 1997, 9, 134–140. [Google Scholar]
- Daszykowski, M.; Kaczmarek, K.; Vander Heyden, Y.; Walczak, B. Robust statistics in data analysis—A review: Basic concepts. Chemom. Intell. Lab. Syst. 2007, 85, 203–219. [Google Scholar] [CrossRef]
- Ebtehaj, I.; Bonakdari, H. A reliable hybrid outlier robust non-tuned rapid machine learning model for multi-step ahead flood forecasting in Quebec, Canada. J. Hydrol. 2022, 614, 128592. [Google Scholar] [CrossRef]
- Mamat, N.; Othman, M.F.; Abdulghafor, R.; Alwan, A.A.; Gulzar, Y. Enhancing image annotation technique of fruit classification using a deep learning approach. Sustainability 2023, 15, 901. [Google Scholar] [CrossRef]
- Tang, H.; Fang, J.; Xie, R.; Ji, X.; Li, D.; Yuan, J. Impact of land cover change on a typical mining region and its ecological environment quality evaluation using remote sensing based ecological index (RSEI). Sustainability 2022, 14, 12694. [Google Scholar] [CrossRef]
- Bonakdari, H.; Jamshidi, A.; Pelletier, J.P.; Abram, F.; Tardif, G.; Martel-Pelletier, J. A warning machine learning algorithm for early knee osteoarthritis structural progressor patient screening. Ther. Adv. Musculoskelet. Dis. 2021, 13, 1759720X21993254. [Google Scholar] [CrossRef] [PubMed]
- Hossin, M.; Sulaiman, M.N. A review on evaluation metrics for data classification evaluations. Int. J. Data Min. Knowl. Manag. Process 2015, 5, 1. [Google Scholar]
- Freeman, E.A.; Moisen, G.G. A comparison of the performance of threshold criteria for binary classification in terms of predicted prevalence and kappa. Ecol. Model. 2008, 217, 48–58. [Google Scholar] [CrossRef]
- Khan, M.I.; Maity, R. Development of a Long-Range Hydrological Drought Prediction Framework Using Deep Learning. Water Resour. Manag. 2024, 38, 1497–1509. [Google Scholar] [CrossRef]
- Saha, A.; Pal, S.C.; Chowdhuri, I.; Roy, P.; Chakrabortty, R.; Shit, M. Vulnerability assessment of drought in India: Insights from meteorological, hydrological, agricultural and socio-economic perspectives. Gondwana Res. 2023, 123, 68–88. [Google Scholar] [CrossRef]
- Sahana, V.; Sreekumar, P.; Mondal, A.; Rajsekhar, D. On the rarity of the 2015 drought in India: A country-wide drought atlas using the multivariate standardized drought index and copula-based severityduration-frequency curves. J. Hydrol. Region Stud. 2020, 31, 100727. [Google Scholar] [CrossRef]
- Aghelpour, P.; Varshavian, V. Forecasting diferent types of droughts simultaneously using multivariate standardized precipitation index (MSPI), MLP neural network, and imperialistic competitive algorithm (ICA). Complexity 2021, 2021, 6610228. [Google Scholar] [CrossRef]
- Naderi, K.; Moghaddasi, M. Drought occurrence probability analysis using multivariate standardized drought index and copula function under climate change. Water Resour Manag. 2022, 36, 2865–2888. [Google Scholar] [CrossRef]
- Masud, M.B.; Qian, B.; Faramarzi, M. Performance of multivariate and multiscalar drought indices in identifying impacts on crop production. Int. J. Climatol. 2020, 40, 292–307. [Google Scholar] [CrossRef]
- Vihinen, M. How to evaluate performance of prediction methods? Measures and their interpretation in variation effect analysis. BMC Genom. 2012, 13, S2. [Google Scholar] [CrossRef] [PubMed]
- Tharwat, A. Classification assessment methods. Appl. Comput. Inform. 2020, 17, 168–192. [Google Scholar] [CrossRef]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef] [PubMed]
- Baldi, P.; Brunak, S.; Chauvin, Y.; Andersen, C.A.; Nielsen, H. Assessing the accuracy of prediction algorithms for classification: An overview. Bioinformatics 2000, 16, 412–424. [Google Scholar] [CrossRef] [PubMed]
- Lobo, J.M.; Jiménez-Valverde, A.; Real, R. AUC: A misleading measure of the performance of predictive distribution models. Glob. Ecol. Biogeogr. 2008, 17, 145–151. [Google Scholar] [CrossRef]
- Jiménez-Valverde, A. Threshold-dependence as a desirable attribute for discrimination assessment: Implications for the evaluation of species distribution models. Biodivers. Conserv. 2014, 23, 369–385. [Google Scholar] [CrossRef]
- Forootan, E.; Khaki, M.; Schumacher, M.; Wulfmeyer, V.; Mehrnegar, N.; van Dijk, A.I.; Brocca, L.; Farzaneh, S.; Akinluyi, F.; Ramillien, G.; et al. Understanding the global hydrological droughts of 2003–2016 and their relationships with teleconnections. Sci. Total Environ. 2019, 650, 2587–2604. [Google Scholar] [CrossRef] [PubMed]
- Sun, P.; Ma, Z.; Zhang, Q.; Singh, V.P.; Xu, C.Y. Modified drought severity index: Model improvement and its application in drought monitoring in China. J. Hydrol. 2022, 612, 128097. [Google Scholar] [CrossRef]
- Lim, T.S.; Loh, W.Y.; Shih, Y.S. A comparison of prediction accuracy, complexity, and training time of thirty-three old and new classification algorithms. Mach. Learn. 2000, 40, 203–228. [Google Scholar] [CrossRef]
- Narasimhan, B.; Srinivasan, R. Development and evaluation of Soil Moisture Deficit Index (SMDI) and Evapotranspiration Deficit Index (ETDI) for agricultural drought monitoring. Agric. For. Meteorol. 2005, 133, 69–88. [Google Scholar] [CrossRef]
- Saito, T.; Rehmsmeier, M. The precision-recall plot is more informative than the ROC plot when evaluating binary classifiers on imbalanced datasets. PLoS ONE 2015, 10, e0118432. [Google Scholar] [CrossRef] [PubMed]
- Hu, K. Become competent within one day in generating boxplots and violin plots for a novice without prior R experience. Methods Protoc. 2020, 3, 64. [Google Scholar] [CrossRef] [PubMed]
- Swain, S.; Mishra, S.K.; Pandey, A.; Dayal, D. Assessment of drought trends and variabilities over the agriculture-dominated Marathwada Region, India. Environ. Monit. Assess. 2022, 194, 883. [Google Scholar] [CrossRef] [PubMed]
- Hassan, A.; Jones, R.; Klinkner, K.L. Beyond DCG: User behavior as a predictor of a successful search. In Proceedings of the Third ACM International Conference on Web Search and Data Mining, New York, NY, USA, 3–6 February 2010; pp. 221–230. [Google Scholar]
- Hemdan, E.E.D.; El-Shafai, W.; Sayed, A. CR19: A framework for preliminary detection of COVID-19 in cough audio signals using machine learning algorithms for automated medical diagnosis applications. J. Ambient. Intell. Humaniz. Comput. 2023, 14, 11715–11727. [Google Scholar] [CrossRef] [PubMed]
- Yacouby, R.; Axman, D. Probabilistic extension of Precision, recall, and f1 score for more thorough evaluation of classification models. In Proceedings of the First Workshop on Evaluation and Comparison of NLP Systems, Online, 20 November 2020; pp. 79–91. [Google Scholar]
- Han, B.; Geng, F.; Dai, S.; Gan, G.; Liu, S.; Yao, L. Statistically optimized back-propagation neural-network model and its application for deformation monitoring and prediction of concrete-face rockfill dams. J. Perform. Constr. Facil. 2020, 34, 04020071. [Google Scholar] [CrossRef]
- Blumenschein, M.; Debbeler, L.J.; Lages, N.C.; Renner, B.; Keim, D.A.; El-Assady, M. v-plots: Designing hybrid charts for the comparative analysis of data distributions. Comput. Graph. Forum 2020, 39, 565–577. [Google Scholar] [CrossRef]
- Rhee, J.; Im, J. Meteorological drought forecasting for ungauged areas based on machine learning: Using long-range climate forecast and remote sensing data. Agric. For. Meteorol. 2017, 237, 105–122. [Google Scholar] [CrossRef]
- Mardian, J.; Champagne, C.; Bonsal, B.; Berg, A. A machine learning framework for predicting and understanding the Canadian drought monitor. Water Resour. Res. 2023, 59, e2022WR033847. [Google Scholar] [CrossRef]
- Bacanli, U.G.; Firat, M.; Dikbas, F. Adaptive neuro-fuzzy inference system for drought forecasting. Stoch. Environ. Res. Risk Assess. 2009, 23, 1143–1154. [Google Scholar] [CrossRef]
- Dastorani, M.T.; Afkhami, H.; Shariffdarani, H.; Dastorani, M. Application of ANN and ANFIS models on dryland precipitation prediction case study: Yazd in central Iran. J. Appl. Sci. 2010, 10, 2387–2394. [Google Scholar] [CrossRef]
- Belayneh, A.; Adamowski, J.; Khalil, B.; Quilty, J. Coupling machine learning methods with wavelet transforms and the bootstrap and boosting ensemble approaches for drought prediction. Atmos. Res. 2016, 172, 37–47. [Google Scholar] [CrossRef]
- Tian, Y.; Xu, Y.P.; Wang, G. Agricultural drought prediction using climate indices based on support vector regression in Xiangjiang River Basin. Sci. Total Environ. 2018, 622, 710–720. [Google Scholar] [CrossRef] [PubMed]
- Shamshirband, S.; Hashemi, S.; Salimi, H.; Samadianfard, S.; Asadi, E. Predicting standardized streamflow index for hydrological drought using machine learning models. Eng. Appl. Comput. Fluid Mech. 2020, 14, 339–350. [Google Scholar] [CrossRef]
- Chen, J.; Yang, Y. SPI-Based regional drought prediction using weighted markov chain model. Res. J. Appl. Sci. Eng. Technol. 2012, 421, 4293–4298. [Google Scholar]
- Alamri, A.M. Short-term spatio-temporal drought forecasting using random forests model at New South Wales, Australia. Appl. Sci. 2020, 10, 4254. [Google Scholar] [CrossRef]
- Shirmohammadi, B.; Moradi, H.; Moosavi, V.; Semiromi, M.T.; Zeinali, A. Fore-casting of meteorological drought using wavelet-aNFIS hybrid model for different time steps case study: Southeastern part of east Azerbaijan province Iran. Nat. Hazards 2013, 69, 389–402. [Google Scholar] [CrossRef]
- Ganguli, P.; Reddy, M.J. Ensemble prediction of regional droughts using climate inputs and the SVM–copula approach. Hydrol. Process. 2014, 28, 4989–5009. [Google Scholar] [CrossRef]
- Zhu, S.; Luo, X.; Chen, S.; Xu, Z.; Zhang, H.; Xiao, Z. Improved hidden Markov model incorporated with copula for probabilistic seasonal drought forecasting. J. Hydrol. Eng. 2020, 25, 04020019. [Google Scholar] [CrossRef]
- Khan, N.; Sachindra, D.A.; Shahid, S.; Ahmed, K.; Shiru, M.S.; Nawaz, N. Prediction of droughts over Pakistan using machine learning algorithms. Adv. Water Resour. 2020, 139, 103562. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Station | Latitude | Longitude |
|---|---|---|
| Lanfley | 49°08′40.800″ N | 122°33′03.600″ W |
| Pitt Meadows | 49°12′29.964″ N | 122°41′24.076″ W |
| Vancouver | 49°17′43.270″ N | 123°07′18.730″ W |
| West Vancouver | 49°20′49.350″ N | 123°11′35.910″ W |
| Input Name | Description |
|---|---|
| P(t) | Total Precipitation |
| P(t − 1) | 1-day lag of total precipitation |
| P(t − 2) | 2-day lag of total precipitation |
| P(t − 3) | 3-day lag of total precipitation |
| P(t − 4) | 4-day lag of total precipitation |
| P(t − 5) | 5-day lag of total precipitation |
| P(t − 6) | 6-day lag of total precipitation |
| SM(t) | Soil moisture |
| SM(t − 1) | 1-day lag of soil moisture |
| SM(t − 2) | 2-day lag of soil moisture |
| SM(t − 3) | 3-day lag of soil moisture |
| SM(t − 4) | 4-day lag of soil moisture |
| SM(t − 5) | 5-day lag of soil moisture |
| SM(t − 6) | 6-day lag of soil moisture |
| Station | Input Combination |
|---|---|
| Pitt Meadows | P(t − 2) + P(t − 4) + SM(t − 1) + SM(t − 3) + SM(t − 4) + SM(t − 5) + SM(t − 6) + P(t) |
| Vancouver | P(t − 3) + SM(t − 1) + SM(t − 2) + SM(t − 3) + SM(t − 4) + SM(t − 6) + SM(t) |
| West Vancouver | P(t − 1) + SM(t − 1) + SM(t − 2) + SM(t − 3) + SM(t − 4) + SM(t − 5) + SM(t − 6) + SM(t) |
| Lanfley | P(t − 5) + SM(t − 1) + SM(t − 3) + SM(t − 4) + SM(t − 5) + SM(t − 6) + P(t) + SM(t) |
| Station | Recall | CA | AUC | F1-Score | Precision |
|---|---|---|---|---|---|
| West Vancouver | 0.453 | 0.764 | 0.869 | 0.789 | 0.539 |
| Vancouver | 0.413 | 0.718 | 0.843 | 0.753 | 0.412 |
| Pitt Meadows | 0.417 | 0.533 | 0.774 | 0.602 | 0.174 |
| Lanfley | 0.417 | 0.761 | 0.762 | 0.574 | 0.362 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Salimi, A.; Noori, A.; Ebtehaj, I.; Ghobrial, T.; Bonakdari, H. Advancing Spatial Drought Forecasts by Integrating an Improved Outlier Robust Extreme Learning Machine with Gridded Data: A Case Study of the Lower Mainland Basin, British Columbia, Canada. Sustainability 2024, 16, 3461. https://0-doi-org.brum.beds.ac.uk/10.3390/su16083461
Salimi A, Noori A, Ebtehaj I, Ghobrial T, Bonakdari H. Advancing Spatial Drought Forecasts by Integrating an Improved Outlier Robust Extreme Learning Machine with Gridded Data: A Case Study of the Lower Mainland Basin, British Columbia, Canada. Sustainability. 2024; 16(8):3461. https://0-doi-org.brum.beds.ac.uk/10.3390/su16083461
Chicago/Turabian StyleSalimi, Amirhossein, Amir Noori, Isa Ebtehaj, Tadros Ghobrial, and Hossein Bonakdari. 2024. "Advancing Spatial Drought Forecasts by Integrating an Improved Outlier Robust Extreme Learning Machine with Gridded Data: A Case Study of the Lower Mainland Basin, British Columbia, Canada" Sustainability 16, no. 8: 3461. https://0-doi-org.brum.beds.ac.uk/10.3390/su16083461