

Exploring Data Input Problems in Mixed Reality Environments: Proposal and Evaluation of Natural Interaction Techniques


Abstract
:1. Introduction
2. Related Works
2.1. Natural Interaction Methods in Mixed Reality
2.2. Input Methods in Mixed Reality
2.3. Data Interaction in Immersive Analytics
3. Interaction Technique Design
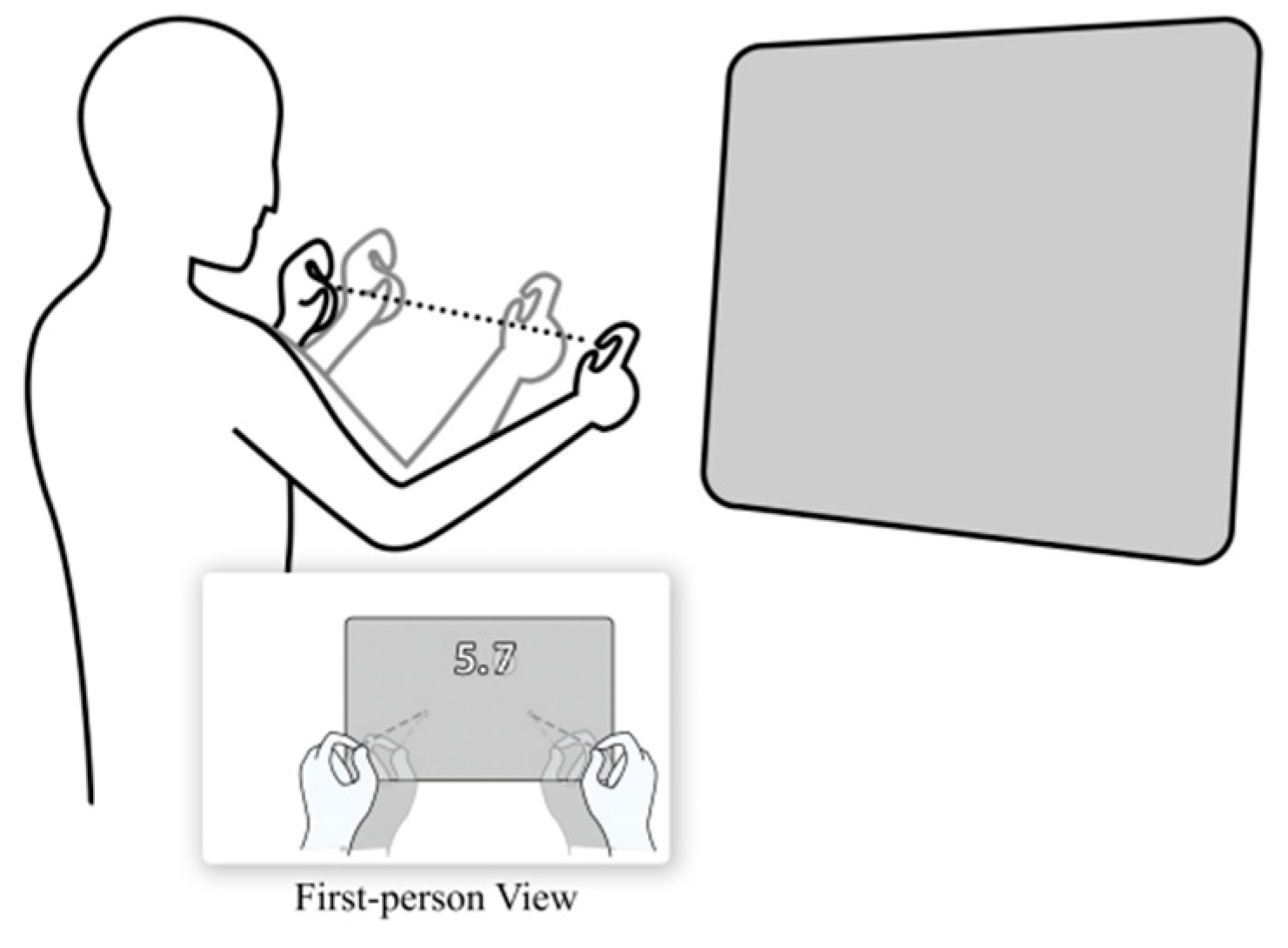
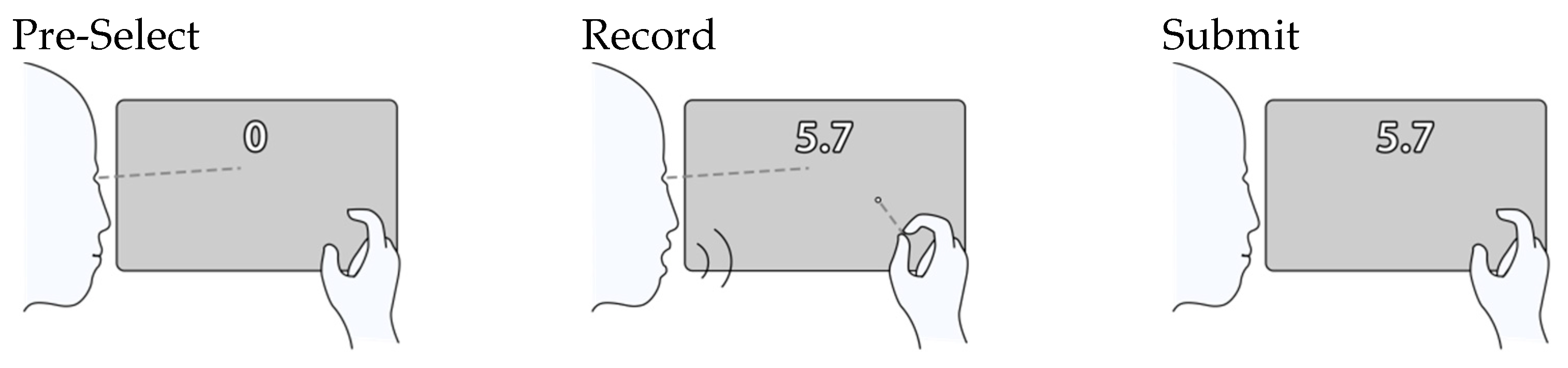
3.1. Bimanual Scaling
3.2. Gesture and Voice
3.3. Benchmark Methods
3.4. Comparison
- Introduce and evaluate the effectiveness of two novel multimodal data input techniques, “Bimanual Scaling” and “Gesture and Voice”, within an MR environment.
- Compare these novel techniques against three benchmark methods (Pinch-Slider, Touch-Slider, and Keyboard) to assess their user efficiency in inputting floating-point data at varying distances.
4. Evaluation
4.1. Participants
4.2. Hardware Devices and Experimental Setup
4.3. Task and Procedure
4.4. Evaluation Metrics
5. Result and Analysis
5.1. Task Completion Time
5.2. NASA-TLX
5.3. Discussion
6. Conclusions and Limitations
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rokhsaritalemi, S.; Sadeghi-Niaraki, A.; Choi, S.-M. A Review on Mixed Reality: Current Trends, Challenges and Prospects. Appl. Sci. 2020, 10, 636. [Google Scholar] [CrossRef]
- Flavián, C.; Ibáñez-Sánchez, S.; Orús, C. The Impact of Virtual, Augmented and Mixed Reality Technologies on the Customer Experience. J. Bus. Res. 2019, 100, 547–560. [Google Scholar] [CrossRef]
- Jiang, H. Mobile Fire Evacuation System for Large Public Buildings Based on Artificial Intelligence and IoT. IEEE Access 2019, 7, 64101–64109. [Google Scholar] [CrossRef]
- Walters, S.M.; Hirsch, S.E.; McKown, G.; Carlson, A.; Allen, A.A. Mixed-Reality Simulation with Preservice Teacher Candidates: A Conceptual Replication. Teach. Educ. Spec. Educ. 2021, 44, 340–355. [Google Scholar] [CrossRef]
- Papadopoulos, T.; Evangelidis, K.; Kaskalis, T.H.; Evangelidis, G.; Sylaiou, S. Interactions in Augmented and Mixed Reality: An Overview. Appl. Sci. 2021, 11, 8752. [Google Scholar] [CrossRef]
- Sicat, R.; Li, J.; Choi, J.; Cordeil, M.; Jeong, W.-K.; Bach, B.; Pfister, H. DXR: A Toolkit for Building Immersive Data Visualizations. IEEE Trans. Vis. Comput. Graph. 2019, 25, 715–725. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.; Jiang, J.; Chen, Y.; Liu, R.; Yang, Y.; Xue, X.; Chen, S. Metaverse: Perspectives from Graphics, Interactions and Visualization. Vis. Inform. 2022, 6, 56–67. [Google Scholar] [CrossRef]
- Filho, J.A.W.; Stuerzlinger, W.; Nedel, L. Evaluating an Immersive Space-Time Cube Geovisualization for Intuitive Trajectory Data Exploration. IEEE Trans. Vis. Comput. Graph. 2020, 26, 514–524. [Google Scholar] [CrossRef] [PubMed]
- Kraus, M.; Fuchs, J.; Sommer, B.; Klein, K.; Engelke, U.; Keim, D.; Schreiber, F. Immersive Analytics with Abstract 3D Visualizations: A Survey. Comput. Graph. Forum 2022, 41, 201–229. [Google Scholar] [CrossRef]
- Cordeil, M.; Cunningham, A.; Bach, B.; Hurter, C.; Thomas, B.H.; Marriott, K.; Dwyer, T. IATK: An Immersive Analytics Toolkit. In Proceedings of the 2019 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), Osaka, Japan, 23–27 March 2019; pp. 200–209. [Google Scholar]
- Adhikary, J.; Vertanen, K. Text Entry in Virtual Environments Using Speech and a Midair Keyboard. IEEE Trans. Vis. Comput. Graph. 2021, 27, 2648–2658. [Google Scholar] [CrossRef] [PubMed]
- Ahn, S.; Lee, G. Gaze-Assisted Typing for Smart Glasses. In Proceedings of the 32nd Annual ACM Symposium on User Interface Software and Technology, New Orleans, LA, USA, 20–23 October 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 857–869. [Google Scholar]
- Wagner, U.; Lystbæk, M.N.; Manakhov, P.; Grønbæk, J.E.S.; Pfeuffer, K.; Gellersen, H. A Fitts’ Law Study of Gaze-Hand Alignment for Selection in 3D User Interfaces. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems, Hamburg, Germany, 23–28 April 2023; pp. 1–15. [Google Scholar]
- Ens, B.; Bach, B.; Cordeil, M.; Engelke, U.; Serrano, M.; Willett, W.; Prouzeau, A.; Anthes, C.; Büschel, W.; Dunne, C.; et al. Grand Challenges in Immersive Analytics. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021; pp. 1–17. [Google Scholar]
- Speicher, M.; Hall, B.D.; Nebeling, M. What Is Mixed Reality? In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Scotland, UK, 4–9 May 2019; pp. 1–15. [Google Scholar]
- Kang, H.J.; Shin, J.; Ponto, K. A Comparative Analysis of 3D User Interaction: How to Move Virtual Objects in Mixed Reality. In Proceedings of the 2020 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), Atlanta, GA, USA, 22–26 March 2020; pp. 275–284. [Google Scholar]
- Kerdvibulvech, C. A Review of Augmented Reality-Based Human-Computer Interaction Applications of Gesture-Based Interaction. In HCI International 2019—Late Breaking Papers; Stephanidis, C., Ed.; Springer International Publishing: Cham, Switzerland, 2019; pp. 233–242. [Google Scholar]
- Newbury, R.; Satriadi, K.A.; Bolton, J.; Liu, J.; Cordeil, M.; Prouzeau, A.; Jenny, B. Embodied Gesture Interaction for Immersive Maps. Cartogr. Geogr. Inf. Sci. 2021, 48, 417–431. [Google Scholar] [CrossRef]
- Sidenmark, L.; Clarke, C.; Zhang, X.; Phu, J.; Gellersen, H. Outline Pursuits: Gaze-Assisted Selection of Occluded Objects in Virtual Reality. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; pp. 1–13. [Google Scholar]
- Shi, R.; Zhang, J.; Yue, Y.; Yu, L.; Liang, H.-N. Exploration of Bare-Hand Mid-Air Pointing Selection Techniques for Dense Virtual Reality Environments. In Proceedings of the Extended Abstracts of the 2023 CHI Conference on Human Factors in Computing Systems, Hamburg, Germany, 23–28 April 2023; pp. 1–7. [Google Scholar]
- Nizam, S.M.; Abidin, R.Z.; Hashim, N.C.; Lam, M.C.; Arshad, H.; Majid, N. A Review of Multimodal Interaction Technique in Augmented Reality Environment. Int. J. Adv. Sci. Eng. Inf. Technol 2018, 8, 1460. [Google Scholar] [CrossRef]
- Hanifa, R.M.; Isa, K.; Mohamad, S. A Review on Speaker Recognition: Technology and Challenges. Comput. Electr. Eng. 2021, 90, 107005. [Google Scholar] [CrossRef]
- Li, J. Recent Advances in End-to-End Automatic Speech Recognition. APSIPA Trans. Signal Inf. Process. 2022, 11, e8. [Google Scholar] [CrossRef]
- Plopski, A.; Hirzle, T.; Norouzi, N.; Qian, L.; Bruder, G.; Langlotz, T. The Eye in Extended Reality: A Survey on Gaze Interaction and Eye Tracking in Head-Worn Extended Reality. ACM Comput. Surv. 2022, 55, 1–39. [Google Scholar] [CrossRef]
- Pfeuffer, K.; Mayer, B.; Mardanbegi, D.; Gellersen, H. Gaze + Pinch Interaction in Virtual Reality. In Proceedings of the 5th Symposium on Spatial User Interaction, Brighton, UK, 16–17 October 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 99–108. [Google Scholar]
- Derby, J.L.; Rarick, C.T.; Chaparro, B.S. Text Input Performance with a Mixed Reality Head-Mounted Display (HMD). In Proceedings of the Human Factors and Ergonomics Society Annual Meeting, Seattle, WA, USA, 28 October–1 November 2019; Volume 63, pp. 1476–1480. [Google Scholar] [CrossRef]
- Yu, C.; Gu, Y.; Yang, Z.; Yi, X.; Luo, H.; Shi, Y. Tap, Dwell or Gesture? Exploring Head-Based Text Entry Techniques for Hmds. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems, Denver, CO, USA, 6–11 May 2017; pp. 4479–4488. [Google Scholar]
- Dudley, J.; Benko, H.; Wigdor, D.; Kristensson, P.O. Performance Envelopes of Virtual Keyboard Text Input Strategies in Virtual Reality. In Proceedings of the 2019 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Beijing, China, 14–18 October 2019; pp. 289–300. [Google Scholar]
- Biener, V.; Ofek, E.; Pahud, M.; Kristensson, P.O.; Grubert, J. Extended Reality for Knowledge Work in Everyday Environments. In Everyday Virtual and Augmented Reality; Simeone, A., Weyers, B., Bialkova, S., Lindeman, R.W., Eds.; Springer International Publishing: Cham, Switzerland, 2023; pp. 21–56. ISBN 978-3-031-05804-2. [Google Scholar]
- Zhang, Y.; Wang, Z.; Zhang, J.; Shan, G.; Tian, D. A Survey of Immersive Visualization: Focus on Perception and Interaction. Vis. Inform. 2023, 7, 22–35. [Google Scholar] [CrossRef]
- Mota, R.C.R.; Rocha, A.; Silva, J.D.; Alim, U.; Sharlin, E. 3De Interactive Lenses for Visualization in Virtual Environments. In Proceedings of the 2018 IEEE Scientific Visualization Conference (SciVis), Berlin, Germany, 21–26 October 2018; pp. 21–25. [Google Scholar]
- Büschel, W.; Lehmann, A.; Dachselt, R. MIRIA: A Mixed Reality Toolkit for the In-Situ Visualization and Analysis of Spatio-Temporal Interaction Data. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021; Association for Computing Machinery: New York, NY, USA, 2021. [Google Scholar]
- Reski, N.; Alissandrakis, A. Open Data Exploration in Virtual Reality: A Comparative Study of Input Technology. Virtual Real. 2020, 24, 1–22. [Google Scholar] [CrossRef]
- Lee, T.K. Artificial Intelligence and Posthumanist Translation: ChatGPT versus the Translator. Available online: https://0-www-degruyter-com.brum.beds.ac.uk/document/doi/10.1515/applirev-2023-0122/html (accessed on 11 March 2024).
- Rice, S.; Crouse, S.R.; Winter, S.R.; Rice, C. The Advantages and Limitations of Using ChatGPT to Enhance Technological Research. Technol. Soc. 2024, 76, 102426. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Touch-Slider | Keyboard | Pinch-Slider | Bimanual Scaling | Gesture and Voice | |
|---|---|---|---|---|---|
| Confirm trigger | Touch | Touch | Pinch | Pinch | Pinch |
| Data input method | Slide | Touch | Slide | Scale | Voice |
| Modalities | Hand | Hand | Hand | Gaze and hand | Gaze, hand, and voice |
| Interaction metaphor | Slider | Keyboard | Slider | Scaling | Voice input |
| Gesture type | Motion (slide) + symbolic (touch) | Symbolic (touch) | Motion (slide) + symbolic (pinch) | Motion (scale) + symbolic (pinch) | Symbolic (pinch) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Chen, T.; Gong, W.; Liu, J.; Chen, J. Exploring Data Input Problems in Mixed Reality Environments: Proposal and Evaluation of Natural Interaction Techniques. Future Internet 2024, 16, 150. https://0-doi-org.brum.beds.ac.uk/10.3390/fi16050150
Zhang J, Chen T, Gong W, Liu J, Chen J. Exploring Data Input Problems in Mixed Reality Environments: Proposal and Evaluation of Natural Interaction Techniques. Future Internet. 2024; 16(5):150. https://0-doi-org.brum.beds.ac.uk/10.3390/fi16050150
Chicago/Turabian StyleZhang, Jingzhe, Tiange Chen, Wenjie Gong, Jiayue Liu, and Jiangjie Chen. 2024. "Exploring Data Input Problems in Mixed Reality Environments: Proposal and Evaluation of Natural Interaction Techniques" Future Internet 16, no. 5: 150. https://0-doi-org.brum.beds.ac.uk/10.3390/fi16050150