
Machine Learning to Enhance the Detection of Terrorist Financing and Suspicious Transactions in Migrant Remittances

Abstract
:1. Introduction
1.1. Migrant Remittances
1.2. Terrorism Financing
1.3. Machine Learning and Risk Finance
2. Materials and Methods
2.1. Data Source
2.2. Traditional Rule-Based Model
2.3. Structural Equation Model
2.3.1. Specification
2.3.2. Identification
2.3.3. Estimation and Evaluation of Model Fit
2.3.4. Respecification
2.3.5. Interpretation and Reporting
2.4. Anomaly Detection
2.4.1. Distance and Density Outlier Detection
2.4.2. Isolation Forest
2.4.3. Isolation Tree
2.4.4. Training and Evaluation Stage
2.5. Local Outlier Factor
2.6. k-Distance Neighbourhood
2.7. Reachability Distance
2.8. Local Reachability Density
2.9. Proposed Outlier Detection Algorithm
2.10. Model Assessment
2.11. Cross-Validating Classification Problems
3. Results
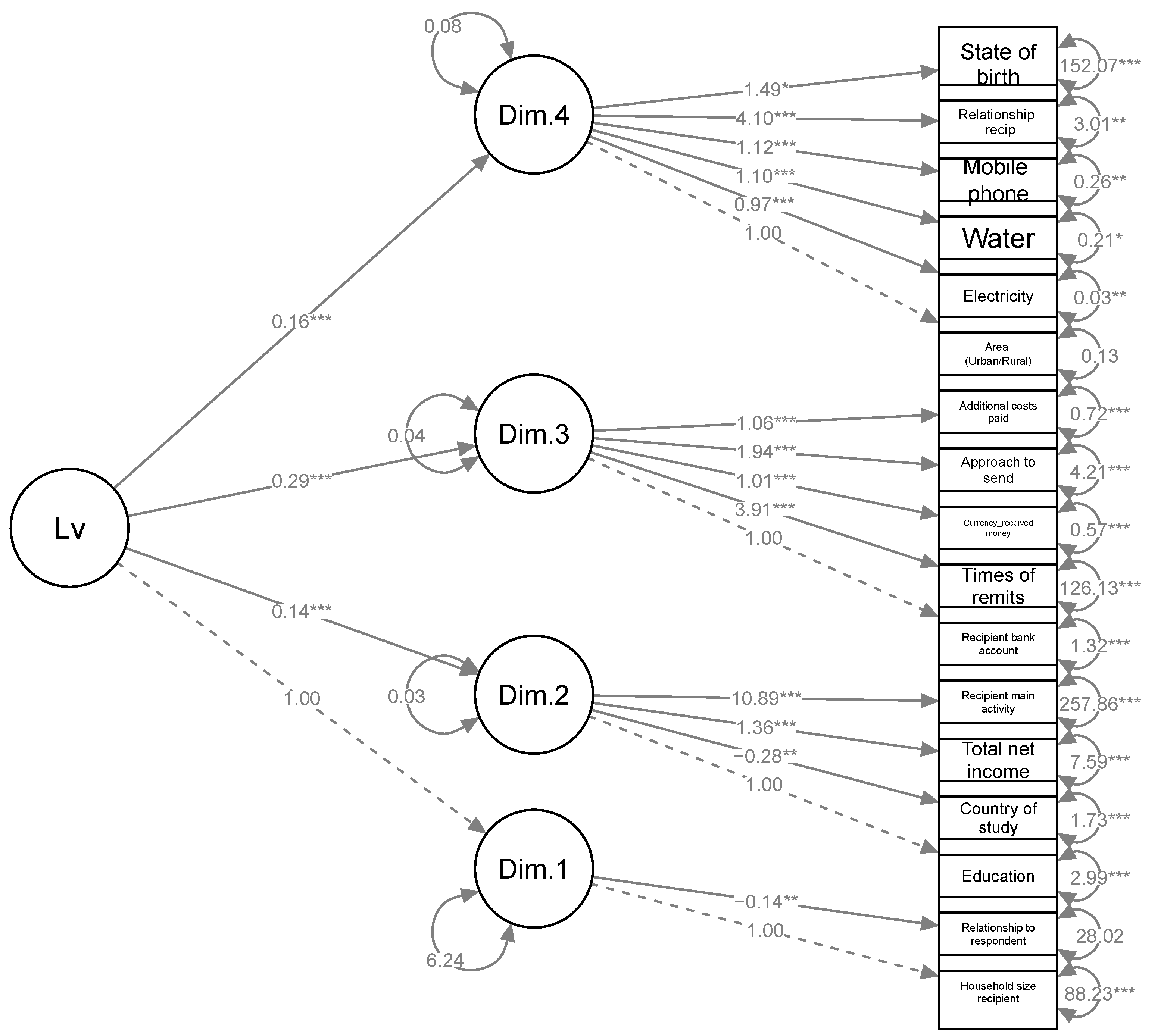
3.1. Structural Equation Model
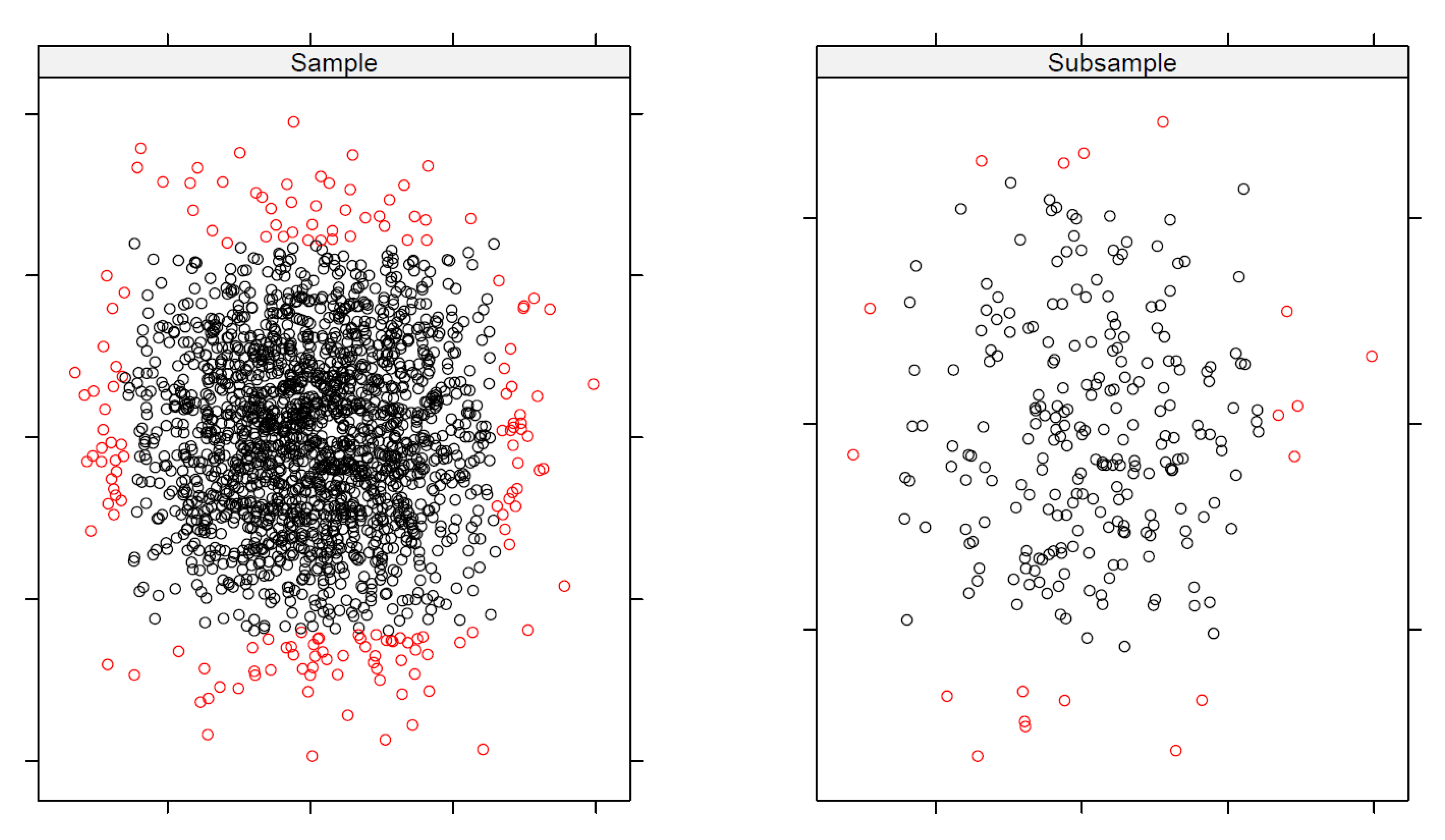
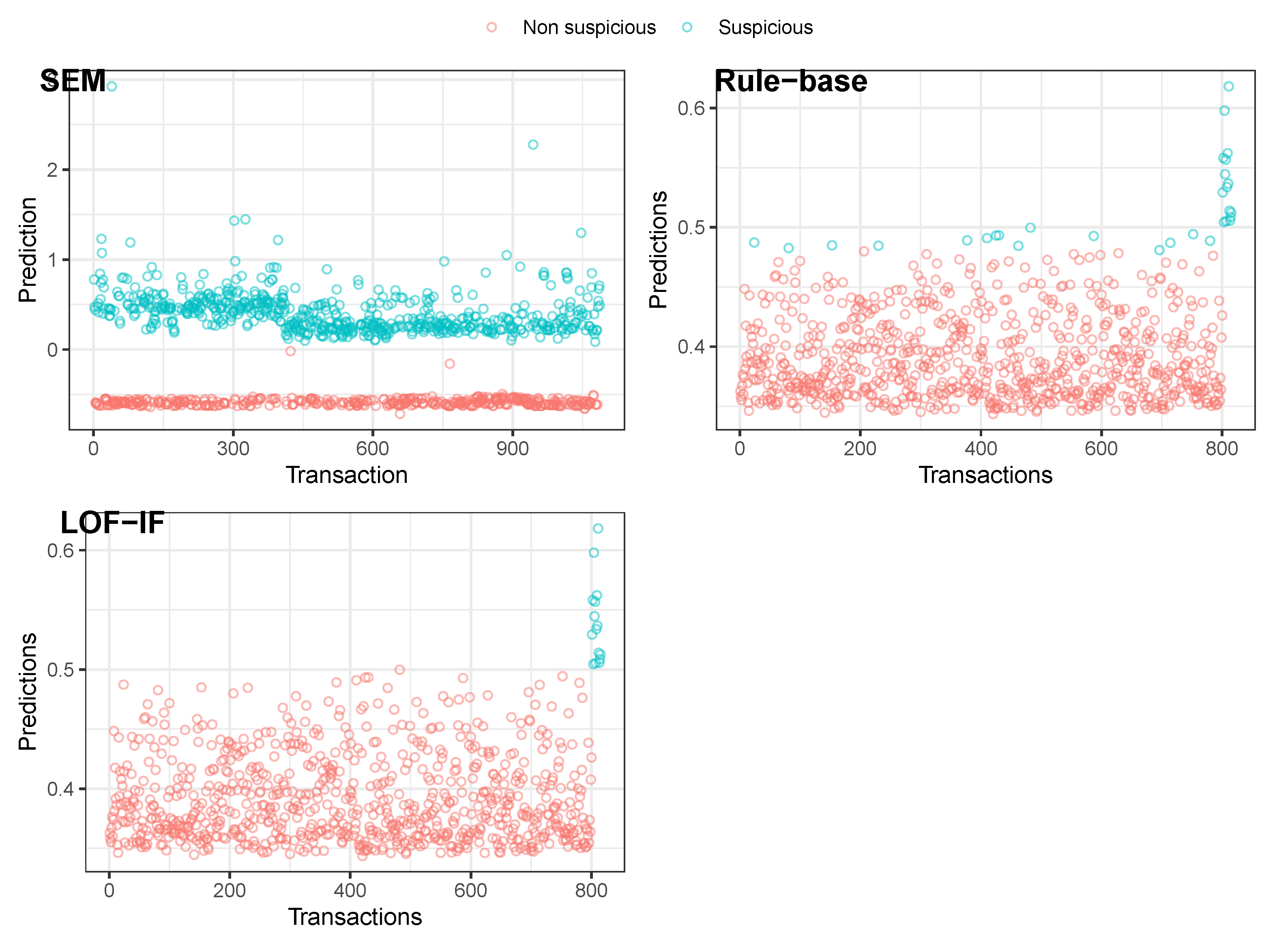
3.2. Outlier Detection Ensemble Model
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Adams, Richard, Jr., and Alfredo Cuecuecha. 2010. Remittances, Household Expenditure and Investment in Guatemala. World Development 38: 1626–41. [Google Scholar] [CrossRef]
- Agnew, Robert. 2010. A General Strain Theory of Terrorism. Theoretical Criminology 14: 131–53. [Google Scholar] [CrossRef]
- Alam, Mansoor, Mansour Tahernezhadi, Pleti Rajesh, Babitha Donepudi, and Monika Agrawal. 2020. Machine Learning and Statistical Analysis Techniques on Terrorism. In Fuzzy Systems and Data Mining VI: Proceedings of FSDM 2020. Amsterdam: IOS Press, pp. 210–22. [Google Scholar]
- Azarnert, Leonid V. 2012. Guest-worker migration, human capital and fertility. Review of Development Economics 16: 318–30. [Google Scholar] [CrossRef]
- Berrar, Daniel. 2019. Cross-Validation. Encyclopedia of Bioinformatics and Computational Biology 1: 542–45. [Google Scholar]
- Biersteker, Thomas J., Sue E. Eckert, and Nikos Passas. 2008. Countering The Financing of Terrorism. London: Routledge. [Google Scholar]
- Bollen, Kenneth A., Daniel J. Bauer, Sharon L. Christ, and Michael C. Edwards. 2010. Overview of Structural Equation Models and Recent Extensions. Hoboken: John Wiley & Sons, Ltd., pp. 37–79. [Google Scholar]
- Breunig, Markus M., Hans-Peter Kriegel, Raymond T. Ng, and Jörg Sander. 2000. LOF: Identifying Density-Based Local Outliers. ACM SIGMOD Record 29: 93–104. [Google Scholar] [CrossRef]
- Brezina, Timothy. 2017. General Strain Theory. In Oxford Research Encyclopedia of Criminology and Criminal Justice. Oxford: Oxford University Press. [Google Scholar] [CrossRef]
- Chandola, Varun, Arindam Banerjee, and Vipin Kumar. 2009. Anomaly Detection: A Survey. ACM Computing Surveys (CSUR) 41: 1–58. [Google Scholar] [CrossRef]
- Cheng, Zhangyu, Chengming Zou, and Jianwei Dong. 2019. Outlier Detection using Isolation Forest and Local Outlier Factor. Paper presented at the Conference on Research in Adaptive and Convergent Systems, Chongqing, China, September 24–27; pp. 161–68. [Google Scholar]
- Chen, Xiangrong, and Alan L. Yuille. 2004. Detecting and Reading Text in Natural Scenes. Paper presented at the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2004, CVPR 2004, Washington, DC, USA, June 27–July 2; vol. 2. [Google Scholar]
- Crenshaw, Martha. 1981. The Causes of Terrorism. Comparative Politics 13: 379–99. [Google Scholar] [CrossRef]
- Cunningham, Pádraig, Matthieu Cord, and Sarah Jane Delany. 2008. Supervised Learning. In Machine Learning Techniques for Multimedia: Case Studies on Organization and Retrieval. Berlin and Heidelberg: Springer, pp. 21–49. [Google Scholar]
- Dilip, Ratha, Sonia Plaza, Eung Ju Kim, Vandana Chandra, Nyasha Kurasha, and Baran Pradhan. 2023. Remittances Remain Resilient But Are Slowing. Migration and Development Brief 38: 1–33. [Google Scholar]
- Durand, Jorge, and Douglas S. Massey. 1992. Mexican migration to the united states: A critical review. Latin American Research Review 27: 3–42. [Google Scholar] [CrossRef]
- Ezell, Barry Charles, Steven P. Bennett, Detlof Von Winterfeldt, John Sokolowski, and Andrew J. Collins. 2010. Probabilistic Risk Analysis and Terrorism Risk. Risk Analysis: An International Journal 30: 575–89. [Google Scholar] [CrossRef]
- Foster, Dean P., and Robert A. Stine. 2004. Variable Selection in Data Mining: Building A Predictive Model for Bankruptcy. Journal of the American Statistical Association 99: 303–13. [Google Scholar] [CrossRef]
- Gao, Zengan. 2009. Application of Cluster-Based Local Outlier Factor Algorithm in Anti-Money Laundering. Paper presented at 2009 International Conference on Management and Service Science, Beijing, China, September 20–22; Piscataway: Institute of Electrical and Electronics Engineers, pp. 1–4. [Google Scholar]
- Hastie, Trevor, Robert Tibshirani, Jerome H. Friedman, and Jerome H. Friedman. 2009. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. Berlin and Heidelberg: Springer, vol. 2. [Google Scholar]
- Hawkins, Douglas M. 1980. Identification of Outliers. Berlin and Heidelberg: Springer, vol. 11. [Google Scholar]
- Hoyle, Rich H. 2012. Handbook of Structural Equation Modeling. New York: Guilford Press. [Google Scholar]
- John, Hyder, and Sameena Naaz. 2019. Credit Card Fraud Detection using Local Outlier Factor and Isolation Forest. International Journal of Computer Science Engineering 7: 1060–64. [Google Scholar] [CrossRef]
- Jose-de Jesus, Rocha-Salazar, Segovia-Vargas Maria-Jesus, and Camacho Minano Mariadel Mar. 2021. Money Laundering and Terrorism Financing Detection Using Neural Networks and an Abnormality Indicator. Expert Systems with Applications 169: 114470. [Google Scholar]
- Khan, Nida S., Asma S. Larik, Quratulain Rajput, and Sajjad Haider. 2013. A Bayesian Approach for Suspicious Financial Activity Reporting. International Journal of Computers and Applications 35: 181–87. [Google Scholar] [CrossRef]
- Liu, Fei Tony, Kai Ming Ting, and Zhi-Hua Zhou. 2008. Isolation Forest. Paper presented at 2008 8th Institute of Electrical and Electronics Engineers International Conference on Data Mining, Pisa, Italy, December 15–19; pp. 413–22. [Google Scholar]
- Liu, Rui, Xiao-Long Qian, Shu Mao, and Shuai-Zheng Zhu. 2011. Research on Anti-Money Laundering Based on Core Decision Tree Algorithm. Paper present at 2011 Chinese Control and Decision Conference (CCDC), Mianyang, China, May 23–25. Piscataway: Institute of Electrical and Electronics Engineers, pp. 4322–25. [Google Scholar]
- Lucas, Robert E. B. 1987. Emigration to South Africa’s Mines. The American Economic Review 77: 313–30. [Google Scholar]
- Major, John A. 2002. Advanced Techniques For Modeling Terrorism Risk. The Journal of Risk Finance 4: 15–24. [Google Scholar] [CrossRef]
- Mandhare, Harshada C., and S. R. Idate. 2017. A Comparative Study of Cluster-based Outlier Detection, Distance-based Outlier Detection and Density-based Outlier Detection Techniques. Paper presented at 2017 International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, June 15–16; pp. 931–35. [Google Scholar]
- Markou, Markos, and Sameer Singh. 2003. Novelty Detection: A Review Part 1: Statistical Approaches. Signal Processing 83: 2481–97. [Google Scholar] [CrossRef]
- Mercer, Lindsay C. J. 1990. Fraud Detection via Regression Analysis. Computers & Security 9: 331–38. [Google Scholar]
- Mesnard, Alice. 2004. Temporary Migration and Capital Market Imperfections. Oxford Economic Papers 56: 242–62. [Google Scholar] [CrossRef]
- Mitchell, Tom M. 1997. Machine Learning. New York: McGraw-Hill. [Google Scholar]
- Mukhtar, Adeel. 2018. Money Laundering, Terror Financing, and FATF: Implications For Pakistan. Journal of Current Affairs 3: 27–56. [Google Scholar]
- Rapoport, Hileel, and Frederic Docquier. 2006. The Economics of Migrants’ Remittances. Handbook of the Economics of Giving, Altruism and Reciprocity 2: 1135–98. [Google Scholar] [CrossRef]
- Ratha, Dilip. 2003. Workers Remittances: An Important And Stable Source of External Development Finance. Global Development Finance 9: 157–74. [Google Scholar]
- Raza, Saleha, and Sajjad Haider. 2011. Suspicious Activity Reporting Using Dynamic Bayesian Networks. Procedia Computer Science 3: 987–91. [Google Scholar] [CrossRef]
- Romaniuk, Peter. 2014. The State of the Art on the Financing of Terrorism. The RUSI Journal 159: 6–17. [Google Scholar] [CrossRef]
- Shokry, A. E. Muhammed, Mohammed Abo Rizka, and Nevine Makram Labib. 2020. Counter Terrorism Finance By Detecting Money Laundering Hidden Networks Using Unsupervised Machine Learning Algorithm. Paper presented at International Conferences ICT, Society, and Human Beings, Online, July 21–23; pp. 89–97. [Google Scholar]
- Sudjianto, Agus, Ming Yuan, Daniel Kern, Sheela Nair, Aijun Zhang, and Fernando Cela-Díaz. 2010. Statistical Methods For Fighting Financial Crimes. Technometrics 52: 5–19. [Google Scholar]
- UNDP. 2017. Journey to Extremism in Africa. United Nations Development Programme Special Report 1: 1–84.
- Wang, Xu, and Yusheng Xu. 2019. An Improved Index for Clustering Validation Based on Silhouette Index and Calinski-Harabasz Index. In IOP Conference Series: Materials Science and Engineering. Bristol: IOP Publishing, vol. 569, p. 52024. [Google Scholar]
- Witten, Daniela, and Gareth James. 2013. An Introduction to Statistical Learning with Applications in R. Berlin and Heidelberg: Springer. [Google Scholar]
- Yang, Dean. 2011. Migrant Remittances. Journal of Economic Perspectives 25: 129–52. [Google Scholar] [CrossRef]
- Zubair, Aishat Abdul-Qadir, Umar A. Oseni, and Norhashimah Mohd Yasin. 2015. Anti-Terrorism Financing Laws in Malaysia: Current Trends and Developments. International Islamic University Malaysia Journal 23: 149. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Standard | Scaled | |
|---|---|---|
| p-- | 0.000 | 0.004 |
| 115 | 115 | |
| 1004.794 | 159.313 | |
| 0.6667 | 0.6667 | |
| - | 0.9889 | 0.9889 |
| 0.9889 | 0.9889 | |
| 0.9926 | 0.9926 | |
| 0.9926 | 0.9926 | |
| −39,547.819 | −39,547.819 | |
| −39,045.423 | −39,045.423 | |
| 79,171.639 | 79,171.639 | |
| 79,361.304 | 79,361.304 | |
| 0.084 | 0.019 | |
| - | 0.080 | 0.011 |
| - | 0.089 | 0.026 |
| p- | 0.080 | 0.011 |
| p- | 0.089 | 0.026 |
| 0.055 | 0.055 |
| SEM | Rule-Base | LOF_IF | |
|---|---|---|---|
| Normal Transactions | 613 | 1057 | 1074 |
| Suspicious Transactions | 474 | 30 | 13 |
| Normal Transaction | Suspicious Transaction | |
|---|---|---|
| Normal Transactions | 268 | 1 |
| Suspicious Transactions | 0 | 2 |
| Accuracy | 0.9963 |
| 95% Confidence Interval | (0.9796, 0.9999) |
| No Information Rate | 0.9889 |
| p-Value [Acc > NIR] | 0.1975 |
| Kappa | 0.7982 |
| F1 Score | 0.9954 |
| Specificity | 0.6667 |
| Positive Predicted Value | 0.9963 |
| Recall Rate | 0.9909 |
| Prevalence | 0.9889 |
| Detection Rate | 0.9889 |
| Detection Prevalence | 0.9926 |
| Balanced Accuracy | 0.8333 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mbiva, S.M.; Correa, F.M. Machine Learning to Enhance the Detection of Terrorist Financing and Suspicious Transactions in Migrant Remittances. J. Risk Financial Manag. 2024, 17, 181. https://0-doi-org.brum.beds.ac.uk/10.3390/jrfm17050181
Mbiva SM, Correa FM. Machine Learning to Enhance the Detection of Terrorist Financing and Suspicious Transactions in Migrant Remittances. Journal of Risk and Financial Management. 2024; 17(5):181. https://0-doi-org.brum.beds.ac.uk/10.3390/jrfm17050181
Chicago/Turabian StyleMbiva, Stanley Munamato, and Fabio Mathias Correa. 2024. "Machine Learning to Enhance the Detection of Terrorist Financing and Suspicious Transactions in Migrant Remittances" Journal of Risk and Financial Management 17, no. 5: 181. https://0-doi-org.brum.beds.ac.uk/10.3390/jrfm17050181