
Multimodal Environmental Sensing Using AI & IoT Solutions: A Cognitive Sound Analysis Perspective

 ,
,  and
and
Abstract
:1. Introduction
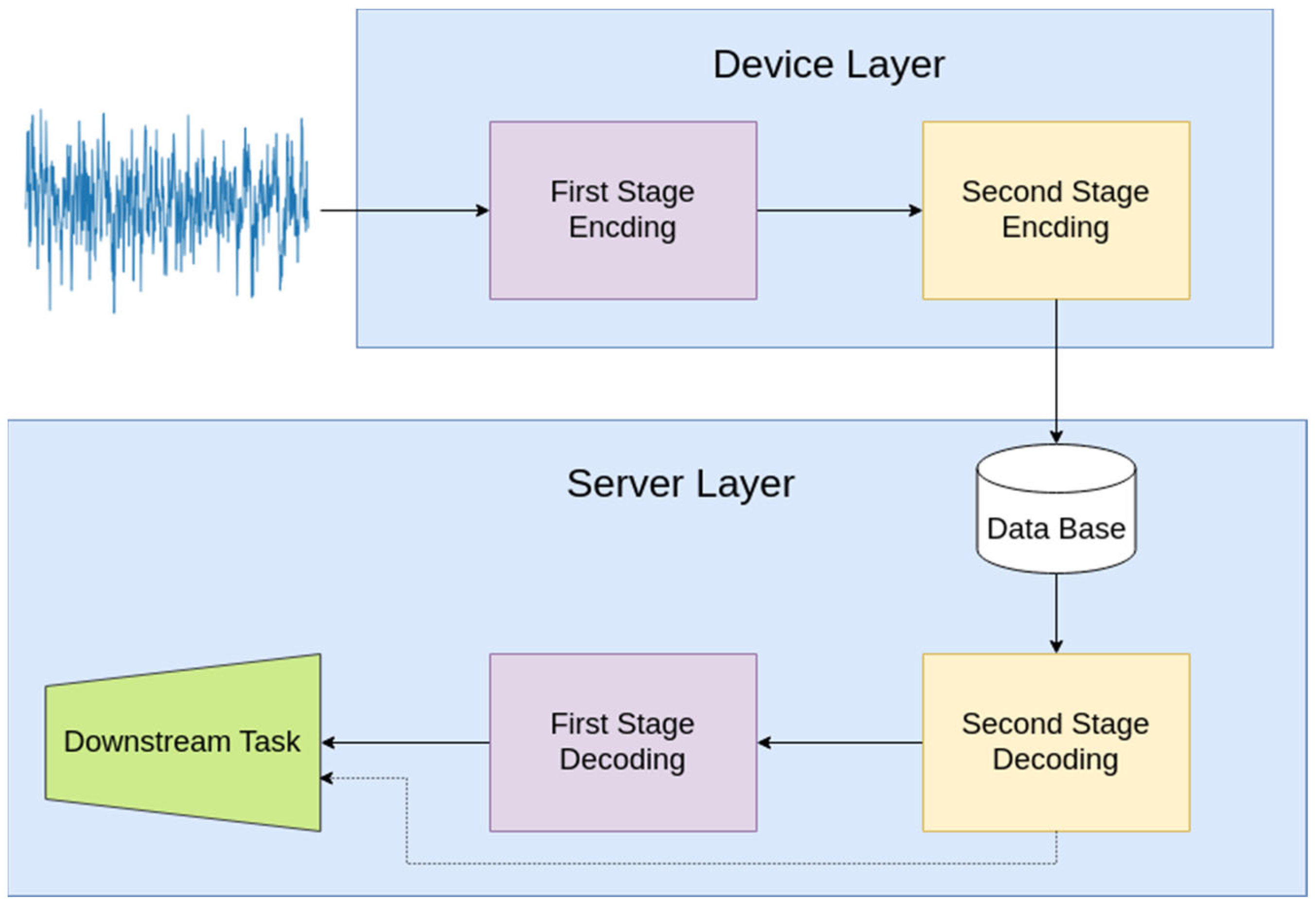
- A DNN-based model is used to encode audio. The result of this process undergoes further encoding/decoding by exploiting traditional lossy and contemporary lossless encoding techniques.
- The compression method employs a minimal number of parameters, facilitating its implementation on devices with limited processing capabilities.
- The system is optimized for extremely low bit rate transmission to the cloud.
- The process allows for various classification tasks to be performed with the encoded and decoded audio, without any significant loss in accuracy.

2. Related Work
3. Materials and Methods
3.1. Data Preparation
3.2. Sound Encoding–Decoding Mechanism
3.2.1. DNN-Based Encoding
3.2.2. Conventional Coding
3.3. Classification Mechanism
3.4. Overall Pipeline
4. Results
4.1. Audio Reconstruction
4.2. Audio Classification
4.2.1. Binary Classification
- (1)
- Examine the behavior of each classifier with respect to each representation.
- (2)
- Conduct a fair comparison.
4.2.2. Multi-Label Classification
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ullo, S.L.; Sinha, G.R. Advances in smart environment monitoring systems using IoT and sensors. Sensors 2020, 20, 3113. [Google Scholar] [CrossRef] [PubMed]
- Alahi, M.E.E.; Sukkuea, A.; Tina, F.W.; Nag, A.; Kurdthongmee, W.; Suwannarat, K.; Mukhopadhyay, S.C. Integration of IoT-enabled technologies and artificial intelligence (AI) for smart city scenario: Recent advancements and future trends. Sensors 2023, 23, 5206. [Google Scholar] [CrossRef] [PubMed]
- Bibri, S.E.; Alexandre, A.; Sharifi, A.; Krogstie, J. Environmentally sustainable smart cities and their converging AI, IoT, and big data technologies and solutions: An integrated approach to an extensive literature review. Energy Inform. 2023, 6, 9. [Google Scholar] [CrossRef] [PubMed]
- Adli, H.K.; Remli, M.A.; Wong, K.N.S.W.S.; Ismail, N.A.; González-Briones, A.; Corchado, J.M.; Mohamad, M.S. Recent Advancements and challenges of AIoT application in smart agriculture: A review. Sensors 2023, 23, 3752. [Google Scholar] [CrossRef]
- Sarroeira, R.; Henriques, J.; Sousa, A.M.; da Silva, C.F.; Nunes, N.; Moro, S.; Botelho, M.D.C. Monitoring Sensors for Urban Air Quality: The Case of the Municipality of Lisbon. Sensors 2023, 23, 7702. [Google Scholar] [CrossRef] [PubMed]
- Chi, X.; Hua, J.; Hua, S.; Ren, X.; Yang, S. Assessing the impacts of human activities on air quality during the COVID-19 Pandemic through case analysis. Atmosphere 2022, 13, 181. [Google Scholar] [CrossRef]
- Wai, C.Y.; Muttil, N.; Tariq, M.A.U.R.; Paresi, P.; Nnachi, R.C.; Ng, A.W.M. Investigating the Relationship between Human Activity and the Urban Heat Island Effect in Melbourne and Four Other International Cities Impacted by COVID-19. Sustainability 2021, 14, 378. [Google Scholar] [CrossRef]
- Sun, Y.; Brimblecombe, P.; Wei, P.; Duan, Y.; Pan, J.; Liu, Q.; Fu, Q.; Peng, Z.; Xu, S.; Wang, Y.; et al. High resolution on-road air pollution using a large taxi-based mobile sensor network. Sensors 2022, 22, 6005. [Google Scholar] [CrossRef] [PubMed]
- Shumba, A.T.; Montanaro, T.; Sergi, I.; Fachechi, L.; De Vittorio, M.; Patrono, L. Leveraging IoT-aware technologies and AI techniques for real-time critical healthcare applications. Sensors 2022, 22, 7675. [Google Scholar] [CrossRef] [PubMed]
- Trilles, S.; Vicente, A.B.; Juan, P.; Ramos, F.; Meseguer, S.; Serra, L. Reliability validation of a low-cost particulate matter IoT sensor in indoor and outdoor environments using a reference sampler. Sustainability 2019, 11, 7220. [Google Scholar] [CrossRef]
- Biraghi, C.A.; Carrion, D.; Brovelli, M.A. Citizen Science Impact on Environmental Monitoring towards SDGs Indicators: The CASE of SIMILE Project. Sustainability 2022, 14, 8107. [Google Scholar] [CrossRef]
- Karanassos, D.; Kyfonidis, C.; Angelis, G.; Emvoliadis, A.; Theodorou, T.I.; Zamichos, A.; Tzovaras, D. SOCIO-BEE: A Next-Generation Citizen Science Platform for Citizens’ Engagement to Air Pollution Measuring. In Proceedings of the 2023 IEEE International Smart Cities Conference (ISC2), Bucharest, Romania, 24–27 September 2023; pp. 1–5. [Google Scholar]
- Latino, M.E.; Menegoli, M.; Signore, F.; De Lorenzi, M.C. The Potential of Gamification for Social Sustainability: Meaning and Purposes in Agri-Food Industry. Sustainability 2023, 15, 9503. [Google Scholar] [CrossRef]
- Bountourakis, V.; Vrysis, L.; Konstantoudakis, K.; Vryzas, N. An enhanced temporal feature integration method for environmental sound recognition. Acoustics 2019, 1, 410–422. [Google Scholar] [CrossRef]
- Han, Y.; Zhang, Q.; Li, V.O.; Lam, J.C. Deep-AIR: A hybrid CNN-LSTM framework for air quality modeling in metropolitan cities. arXiv 2021, arXiv:2103.14587. [Google Scholar]
- Le, V.D.; Bui, T.C.; Cha, S.K. Spatiotemporal deep learning model for citywide air pollution interpolation and prediction. In Proceedings of the 2020 IEEE International Conference on Big Data and Smart Computing (BigComp), Busan, Republic of Korea, 19–22 February 2020; pp. 55–62. [Google Scholar]
- Scheibenreif, L.; Mommert, M.; Borth, D. Estimation of air pollution with remote sensing data: Revealing greenhouse gas emissions from space. arXiv 2021, arXiv:2108.13902. [Google Scholar]
- Clark, S.N.; Alli, A.S.; Brauer, M.; Ezzati, M.; Baumgartner, J.; Toledano, M.B.; Arku, R.E. High-resolution spatiotemporal measurement of air and environmental noise pollution in Sub-Saharan African cities: Pathways to Equitable Health Cities Study protocol for Accra, Ghana. BMJ Open 2020, 10, e035798. [Google Scholar] [CrossRef] [PubMed]
- Stamatiadou, M.E.; Vryzas, N.; Vrysis, L.; Saridou, T.; Dimoulas, C. A citizen science approach to support joint air quality and noise monitoring in urban areas. In Proceedings of the Audio Engineering Society Convention 152. Audio Engineering Society, The Hague, The Netherlands, 7–8 May 2022. [Google Scholar]
- Vryzas, N.; Stamatiadou, M.E.; Vrysis, L.; Dimoulas, C. The BeeMate: Air quality monitoring through crowdsourced audiovisual data. In Proceedings of the 2023 8th International Conference on Smart and Sustainable Technologies (SpliTech), Split, Croatia, 20–23 June 2023; pp. 1–5. [Google Scholar]
- Elliott, D.; Martino, E.; Otero, C.E.; Smith, A.; Peter, A.M.; Luchterhand, B.; Leung, S. Cyber-physical analytics: Environmental sound classification at the edge. In Proceedings of the 2020 IEEE 6th World Forum on Internet of Things (WF-IoT), New Orleans, LA, USA, 2–16 June 2020; pp. 1–6. [Google Scholar]
- Nanni, L.; Maguolo, G.; Brahnam, S.; Paci, M. An ensemble of convolutional neural networks for audio classification. Appl. Sci. 2021, 11, 5796. [Google Scholar] [CrossRef]
- Abdulmalek, S.; Nasir, A.; Jabbar, W.A.; Almuhaya, M.A.; Bairagi, A.K.; Khan, M.A.M.; Kee, S.H. IoT-based healthcare-monitoring system towards improving quality of life: A review. Healthcare 2022, 10, 1993. [Google Scholar] [CrossRef] [PubMed]
- Syed, A.S.; Sierra-Sosa, D.; Kumar, A.; Elmaghraby, A. IoT in smart cities: A survey of technologies, practices and challenges. Smart Cities 2021, 4, 429–475. [Google Scholar] [CrossRef]
- Wilkinghoff, K. On open-set classification with L3-Net embeddings for machine listening applications. In Proceedings of the 2020 28th European Signal Processing Conference (EUSIPCO), Amsterdam, The Netherlands, 18–21 January 2021; pp. 800–804. [Google Scholar]
- Cramer, A.L.; Wu, H.H.; Salamon, J.; Bello, J.P. Look, listen, and learn more: Design choices for deep audio embeddings. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 3852–3856. [Google Scholar]
- Snyder, D.; Garcia-Romero, D.; Sell, G.; Povey, D.; Khudanpur, S. X-vectors: Robust dnn embeddings for speaker recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5329–5333. [Google Scholar]
- Kim, J. Urban sound tagging using multi-channel audio feature with convolutional neural networks. In Proceedings of the Detection and Classification of Acoustic Scenes and Events, Tokyo, Japan, 2–3 November 2020. [Google Scholar]
- Lopez-Meyer, P.; del Hoyo Ontiveros, J.A.; Lu, H.; Stemmer, G. Efficient end-to-end audio embeddings generation for audio classification on target applications. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Virtual, 6–11 June 2021; pp. 601–605. [Google Scholar]
- Gong, Y.; Chung, Y.A.; Glass, J. Ast: Audio spectrogram transformer. arXiv 2021, arXiv:2104.01778. [Google Scholar]
- Mohaimenuzzaman, M.; Bergmeir, C.; West, I.; Meyer, B. Environmental Sound Classification on the Edge: A Pipeline for Deep Acoustic Networks on Extremely Resource-Constrained Devices. Pattern Recognit. 2023, 133, 109025. [Google Scholar] [CrossRef]
- Palanisamy, K.; Singhania, D.; Yao, A. Rethinking CNN models for audio classification. arXiv 2020, arXiv:2007.11154. [Google Scholar]
- Chen, S.; Wu, Y.; Wang, C.; Liu, S.; Tompkins, D.; Chen, Z.; Wei, F. Beats: Audio pre-training with acoustic tokenizers. arXiv 2022, arXiv:2212.09058. [Google Scholar]
- Elizalde, B.; Deshmukh, S.; Al Ismail, M.; Wang, H. Clap learning audio concepts from natural language supervision. In Proceedings of the ICA SSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Lelewer, D.A.; Hirschberg, D.S. Data compression. ACM Comput. Surv. (CSUR) 1987, 19, 261–296. [Google Scholar] [CrossRef]
- Byun, J.; Shin, S.; Park, Y.; Sung, J.; Beack, S. A perceptual neural audio coder with a mean-scale hyperprior. In Proceedings of the ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- D’efossez, A.; Copet, J.; Synnaeve, G.; Adi, Y. High fidelity neural audio compression. arXiv 2022, arXiv:2210.13438. [Google Scholar]
- Emvoliadis, A.; Vryzas, N.; Stamatiadou, M.E.; Vrysis, L.; Dimoulas, C.; Drosou, A.; Tzovaras, D. A Robust Deep Learning-based System for Environmental Audio Compression and Classification. In Proceedings of the Audio Engineering Society Convention 154. Audio Engineering Society, Helsinki, Finland, 13–15 May 2023. [Google Scholar]
- Piczak, K.J. ESC: Dataset for environmental sound classification. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 1015–1018. [Google Scholar]
- Vrysis, L.; Tsipas, N.; Thoidis, I.; Dimoulas, C. 1D/2D Deep CNNs vs. Temporal Feature Integration for General Audio Classification. J. Audio Eng. Soc. 2020, 68, 66–77. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Van Den Oord, A.; Vinyals, O. Neural discrete representation learning. arXiv 2017, arXiv:1711.00937. [Google Scholar]
- Stankevicius, D.; Treigys, P. Investigation of machine learning methods for colour audio noise suppression. In Proceedings of the 2023 18th Iberian Conference on Information Systems and Technologies (CISTI), Aveiro, Portugal, 20–23 June 2023; pp. 1–6. [Google Scholar]
- Scudo, F.L.; Ritacco, E.; Caroprese, L.; Manco, G. Audio-based anomaly detection on edge devices via self-supervision and spectral analysis. J. Intell. Inf. Syst. 2023, 61, 765–779. [Google Scholar] [CrossRef]
- Kumble, L.; Patil, K.K. An improved data compression framework for wireless sensor networks using stacked convolutional autoencoder (scae). SN Comput. Sci. 2023, 4, 419. [Google Scholar] [CrossRef]
- Ahmed, N.; Natarajan, T.; Rao, K.R. Discrete cosine transform. IEEE Trans. Comput. 1974, 100, 90–93. [Google Scholar] [CrossRef]
- Welch, T.A. A technique for high-performance data compression. Computer 1984, 17, 8–19. [Google Scholar] [CrossRef]
- Alakuijala, J.; Farruggia, A.; Ferragina, P.; Kliuchnikov, E.; Obryk, R.; Szabadka, Z.; Vandevenne, L. Brotli: A general-purpose data compressor. ACM Trans. Inf. Syst. (TOIS) 2018, 37, 1–30. [Google Scholar] [CrossRef]
- Collet, Y.; Kucherawy, M. Zstandard compression and the application/zstd media type. Tech. Rep. 2018. [Google Scholar] [CrossRef]
- Hirschberg, D.S.; Lelewer, D.A. Context modeling for text compression. In Image and Text Compression; Springer: New York, NY, USA, 1992; pp. 113–144. [Google Scholar]
- Collet, Y. Finite State Entropy. 2013. Available online: https://github.com/Cyan4973/FiniteStateEntropy (accessed on 15 January 2024).
- Valin, J.M.; Vos, K.; Terriberry, T. Definition of the opus audio codec. Tech. Rep. 2012. [Google Scholar] [CrossRef]
- Liu, X.; Dohler, M.; Deng, Y. Vibrotactile quality assessment: Hybrid metric design based on SNR and SSIM. IEEE Trans. Multimed. 2019, 22, 921–933. [Google Scholar] [CrossRef]
- Thiede, T.; Treurniet, W.C.; Bitto, R.; Schmidmer, C.; Sporer, T.; Beerends, J.G.; Colomes, C. PEAQ-The ITU standard for objective measurement of perceived audio quality. J. Audio Eng. Soc. 2000, 48, 3–29. [Google Scholar]
- Iandola, F.; Moskewicz, M.; Karayev, S.; Girshick, R.; Darrell, T.; Keutzer, K. Densenet: Implementing efficient convnet descriptor pyramids. arXiv 2014, arXiv:1404.1869. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–22 June 2022; pp. 11976–11986. [Google Scholar]
- Koonce, B. EfficientNet. Convolutional Neural Networks with Swift for Tensorflow: Image Recognition and Dataset Categorization; Springer: New York, NY, USA, 2021; pp. 109–123. [Google Scholar]
- Wu, Z.; Shen, C.; Van Den Hengel, A. Wider or deeper: Revisiting the resnet model for visual recognition. Pattern Recognit. 2019, 90, 119–133. [Google Scholar] [CrossRef]
- Vegiris, C.E.; Avdelidis, K.A.; Dimoulas, C.A.; Papanikolaou, G.V. Live broadcasting of high definition audiovisual content using HDTV over broadband IP networks. Int. J. Digit. Multimed. Broadcast. 2008. [Google Scholar] [CrossRef]
- Vryzas, N.; Vrysis, L.; Dimoulas, C. Audiovisual speaker indexing for Web-TV automations. Expert Syst. Appl. 2021, 186, 115833. [Google Scholar] [CrossRef]
- Mandel, M.; Tal, O.; Adi, Y. Aero: Audio super resolution in the spectral domain. In Proceedings of the ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Xylogiannis, P.; Vryzas, N.; Bountourakis, V.; Dimoulas, C. Multichannel speaker diarization with arbitrary microphone arrays. In Proceedings of the Audio Engineering Society Convention 154. Audio Engineering Society, Espoo, Finland, 13–15 May 2023. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Level (N) | Bit Rate (kbps) | PEAQ | SSIM | PSNR (dB) |
|---|---|---|---|---|---|
| AE | –– | 44 | 3.34 | 0.84 | 29.8 |
| AE + Brotli * | 6 | 8.9 | 3.26 | 0.83 | 28.9 |
| 5 | 5.9 | 3.07 | 0.82 | 27.6 | |
| 4 | 3.3 | 2.79 | 0.80 | 25.5 | |
| AE + Brotli | 6 | 8.9 | 3.26 | 0.83 | 28.9 |
| 5 | 5.9 | 3.07 | 0.82 | 27.6 | |
| 4 | 3.3 | 2.79 | 0.80 | 25.5 | |
| AE + Zstd * | 6 | 9.2 | 3.26 | 0.83 | 28.9 |
| 5 | 6.1 | 3.07 | 0.82 | 27.6 | |
| 4 | 3.4 | 2.79 | 0.80 | 25.5 | |
| AE + Zstd | 6 | 9.2 | 3.26 | 0.83 | 28.9 |
| 5 | 6.1 | 3.07 | 0.82 | 27.6 | |
| 4 | 3.4 | 2.79 | 0.80 | 25.5 | |
| Opus | –– | 44 | 4.16 | 0.92 | 34.1 |
| –– | 12 | 3.26 | 0.80 | 28.6 | |
| –– | 6 | 2.41 | 0.68 | 24.7 |
| Method | Level (N) | Bit Rate (kbps) | PEAQ | SSIM | PSNR (dB) |
|---|---|---|---|---|---|
| AE | –– | 44 | 3.08 | 0.82 | 29.0 |
| AE + Brotli | 4 | 2.6 | 2.58 | 0.79 | 25.0 |
| AE + Zstd | 4 | 2.8 | 2.58 | 0.79 | 25.0 |
| Opus | 4 | 6 | 2.46 | 0.70 | 24.7 |
| Model | Precision | Recall | F1-Score | Accuracy |
|---|---|---|---|---|
| ACDNet (original) | 90.04% (4.01) | 90.27% (3.27) | 90.24% (3.34) | 91.47% (4.34) |
| 1D-CNN (original) | 73.27% (6.52) | 74.42% (5.86) | 73.63% (5.12) | 74.25% (5.16) |
| ACDNet (reconstructed) | 89.00% (6.23) | 89.81% (4.62) | 88.87% (1.53) | 89.25% (1.69) |
| 1D-CNN (reconstructed) | 81.77% (8.68) | 82.26% (6.12) | 80.63% (5.34) | 80.75% (5.16) |
| 1D-CNN (compressed) | 86.22% (4.32) | 86.07% (3.73) | 85.91% (2.56) | 85.75% (2.91) |
| Input | Level (N) | Bit Rate (kbps) | Accuracy |
|---|---|---|---|
| Original | –– | 256 | 91.47% |
| AE (plain) | –– | 44 | 89.25% |
| AE + Brotli | 4 | 3.3 | 87.97% |
| 5 | 5.9 | 88.65% | |
| 6 | 8.9 | 90.88% | |
| AE + Zstd | 4 | 3.4 | 87.97% |
| 5 | 6.1 | 88.65% | |
| 6 | 9.2 | 90.88% | |
| Opus | –– | 44 | 89.75% |
| –– | 12 | 86.52% | |
| –– | 6 | 72.34% |
| Model | 50-Class Accuracy | 5-Class Accuracy |
|---|---|---|
| ResNet-18 (original) | 84.25% (2.70) | 89.85% (1.65) |
| ConvNext (3.3 kbps) | 73.90% (3.28) | 82.20% (4.19) |
| ResNet-50 (3.3 kbps) | 73.20% (4.01) | 81.75% (3.85) |
| DenseNet-101 (3.3 kbps) | 73.15% (3.59) | 82.70% (3.92) |
| Wide ResNet (3.3 kbps) | 73.40% (3.22) | 82.60% (4.06) |
| EfficientNet (3.3 kbps) | 73.70% (3.12) | 82.10% (3.28) |
| Ensemble (3.3 kbps) | 74.60% (3.06) | 83.40% (3.14) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Emvoliadis, A.; Vryzas, N.; Stamatiadou, M.-E.; Vrysis, L.; Dimoulas, C. Multimodal Environmental Sensing Using AI & IoT Solutions: A Cognitive Sound Analysis Perspective. Sensors 2024, 24, 2755. https://0-doi-org.brum.beds.ac.uk/10.3390/s24092755
Emvoliadis A, Vryzas N, Stamatiadou M-E, Vrysis L, Dimoulas C. Multimodal Environmental Sensing Using AI & IoT Solutions: A Cognitive Sound Analysis Perspective. Sensors. 2024; 24(9):2755. https://0-doi-org.brum.beds.ac.uk/10.3390/s24092755
Chicago/Turabian StyleEmvoliadis, Alexandros, Nikolaos Vryzas, Marina-Eirini Stamatiadou, Lazaros Vrysis, and Charalampos Dimoulas. 2024. "Multimodal Environmental Sensing Using AI & IoT Solutions: A Cognitive Sound Analysis Perspective" Sensors 24, no. 9: 2755. https://0-doi-org.brum.beds.ac.uk/10.3390/s24092755