1. Introduction
About 13,000 years ago, humanity moved from nomad to sedentary life styles in the fertile crescent. In the 9000 years Before Common Era (BCE), men started to raise animals, to cultivate, and to make pottery for food storage [
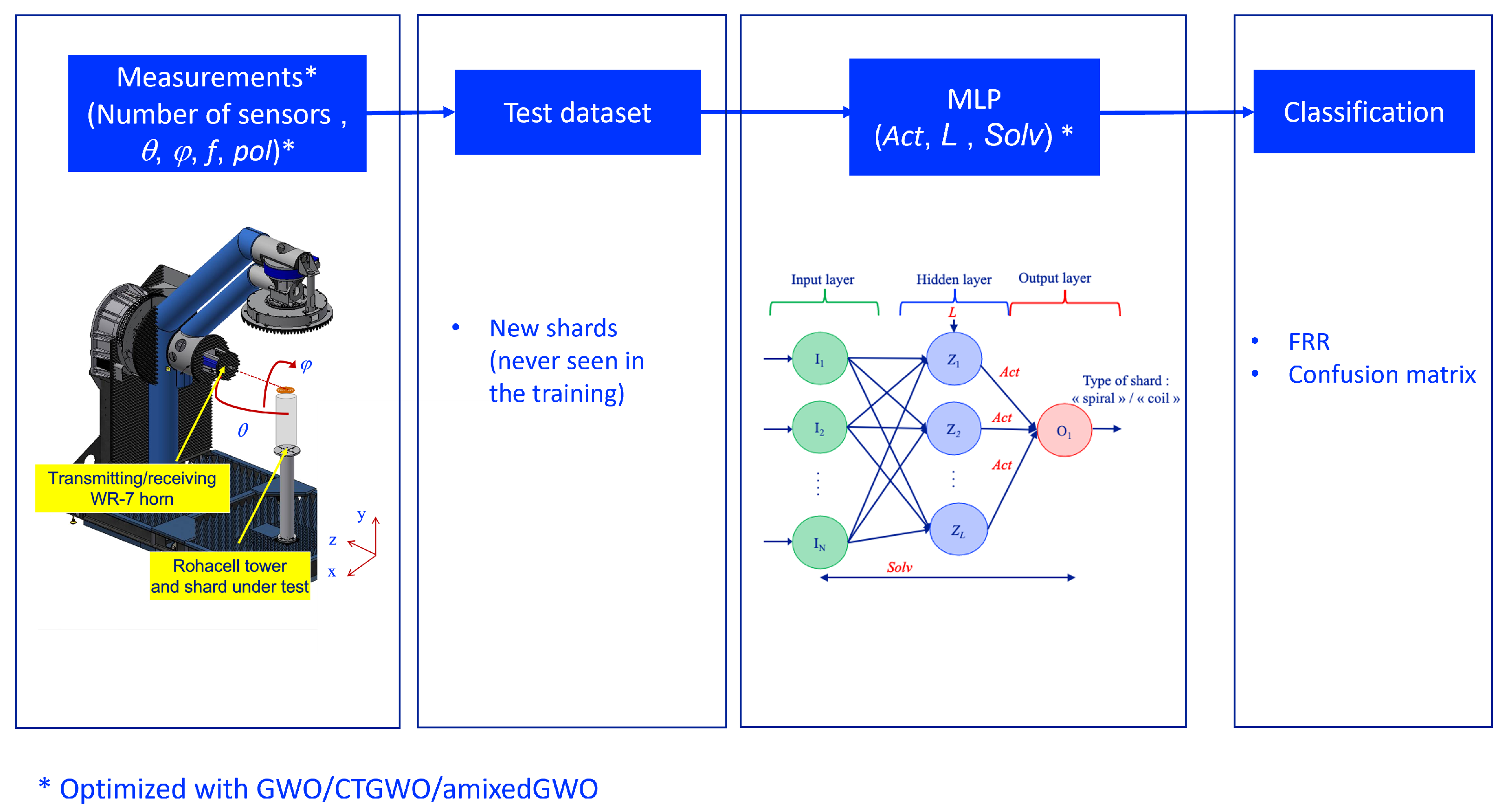
1]. How agriculture spread from Mesopotamia to the rest of the world is still a subject of study for Historians, made all the more challenging by the fact that writing emerged two thousand years later, about 3400 BCE. Looking for pottery techniques is one of the key enablers for solving this issue. Indeed, historians found that the coiling technique has spread through Central and East Europe, whereas the spiral one follows the Western and Mediterranean routes. Of course, the remains that can be found by archaeologists are not entire potteries but shards, which poses a new issue: how to recognize the pottery technique based on small pieces of potteries? We have recently proposed a new imaging modality to solve this issue [
2]. It is based on low-THz radar-based Non-Destructive Evaluation (NDE) and classification with a neural network. We emphasize, in [
2], the interest of millimeter waves for this research. Low-THz waves adequately capture pieces of information about the content of an archeological shard, in particular the shape of the pores inside the shards, thanks to the high resolution due to the short wavelength. The classification accuracy is close to 100%, which is very promising for quite a number of applications. However, in its present form, the measurement time (about 2 h per shard) hinders its extension to an application that requires real-time operation. This is a well-known problem in many radar-based applications. On one hand, the more spatial diversity we have, the better the image. At the same time, the measurement sampling has to be dense in order to avoid spurious responses. This leads to a significant number of measurements points (number of sensors), which in turn slows down the measurement. These constraints are essentially based on the need to recognize the object for imaging-based identification. In this paper, we propose to overcome this issue with a co-design scheme. To this end, we are implementing a joint optimization of the measurement system and the parameters of the Multi-Layer Perceptron (MLP) used for the classification. Our main objective is to drastically reduce the number of antennas (measurements points) for reaching real-time operation. In [
3], sensor placement is optimized in a wireless sensor network with a step-wise optimization approach; but optimizing the placement of the radar sensors independently of each other is a brand new outcome.
The interest of neural networks has been demonstrated to process multivariable sensor data [
4], or radar data with the aim of human activity classification (walking, running, etc.) [
5]. They also have been adapted to the design of radiofrequency and microwave antennas [
6,
7,
8], noise modeling in transistors [
9], optimization of circuits [
10], and to locate fault elements in arrays of sensors [
11].
The main contributions of this paper are as follows. A careful look at the parameters involved in the considered radar issue permits to distinguish three types of ’search spaces’, each containing all the possible values for a given parameter. For instance, the state of a given sensor corresponds to a binary search space: either 0, or 1, standing for OFF or ON. The other parameters that are investigated correspond to a continuous search space and a ternary search space. To tackle this issue, we propose a novel optimization algorithm, inspired by the GWO (Grey Wolf Optimizer), which we call the CBTGWO (Continuous Binary Ternary Grey Wolf Optimizer), to minimize a criterion which depends on a false recognition rate and on the number of sensors. Firstly, we derive a variant of the Binary GWO which favors the reduction in the number of sensors which are switched on, and a Ternary GWO. Secondly, we embed chaotic sequences in the update rules to enhance the exploration and exploitation abilities of our algorithm. We propose an original way to profit by the diversity of chaotic sequence, which exhibits the great advantage of authorizing a perfect control of the behavior of the algorithm in the last iterations of the process. The results obtained on either a single frequency context or on a wide-band context show the ability of the proposed method to drastically reduce the number of sensors while offering small false recognition rate values.
In
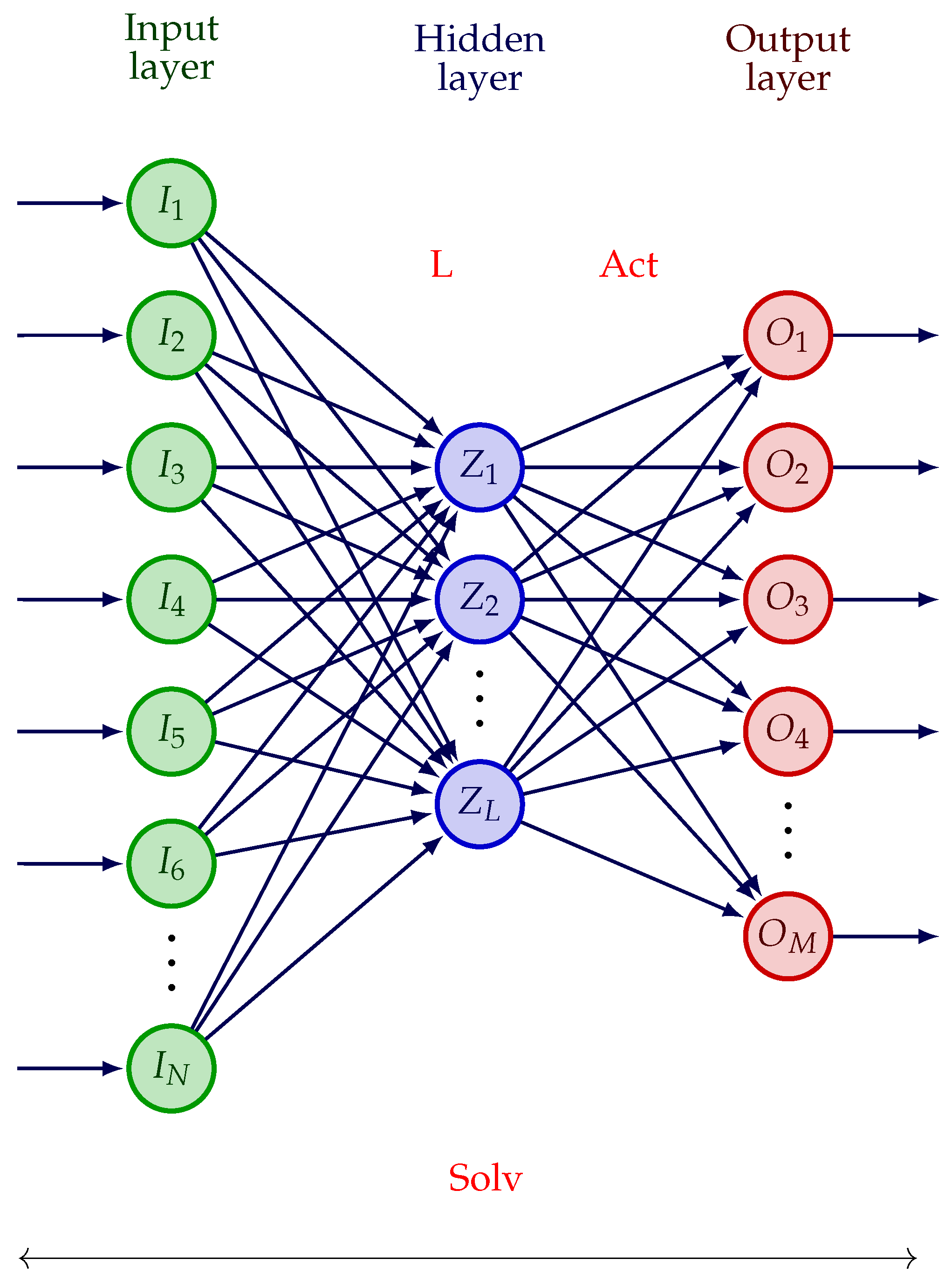
Section 2, we provide the mathematical background and state-of-the-art about the fundamentals of the GWO, and its binary version in particular. We explain what the materials used in this paper are, such as the radar data used for shard classification. We present the millimeter-wave system for shard analysis, and the neural network algorithm, which is meant for data classification. We set the problem we wish to solve: the common minimization of a false recognition rate and a number of sensors which are switched on. We derive a single criterion that combines these two criteria, and we show that the parameters which have an influence on this criterion belong either to discrete, ternary, or binary search spaces. In particular, each sensor state corresponds to a binary search space: either ON, or OFF.
In
Section 3, we detail the novel method proposed in this paper. Firstly, a novel binary version of the GWO, which aims at estimating the optimal state of the sensors while favoring 0 values, and enhances exploration thanks to an evolutive update rule. Secondly, the combination of the continuous, binary, and ternary versions of the GWO yields the CBTGWO.
In
Section 4, we evaluate the performances of the CBTGWO, compared to the vanilla GWO [
12] and the adaptive mixed GWO [
13]: firstly, on a synthetic ’surrogate’ function, which models the practical radar issue under study, and, secondly, on the considered issue and real-world radar experimental data. A discussion about these results is provided in
Section 5, and conclusions are drawn in
Section 6.
We use these notations in the paper:
| Manifold | blackboard bold | |
| Matrices | boldface upper-case roman | A |
| Vectors | boldface lower-case roman | a |
| Scalars | lower-case or upper-case roman | a, a or A |
A vector a with P scalar components can be expressed as .
We use these definitions in the paper:
| Vector with P components | | |
| Hadamard product | ∘ | . |
| Absolute value | | |
| Interval | | a and b are real scalar values |
| Set of discrete values | | a and b are real scalar values |
3. Methods: Proposed Continuous Binary Ternary GWO
We wish to preserve the original philosophy of the GWO: the number of leaders ruling the update of the agents is superior to 1, and the parameter
a permits us to distinguish between an exploration phase at the beginning of the algorithm and an exploitation phase at the end. The continuous, original version of the GWO will be used to estimate the number of neurons in the hidden layer of the MLP because the search space is relatively wide (from 2 to 30); the ternary version proposed in [
29] will be used to design the 2 other hyperparameters of the MLP. Indeed, data scientists usually compare the performances of three main solvers and three main activation functions to choose the best configuration for their application. Using an adaptive learning rate with
can offer flexibility, but stochastic gradient descent performs well with relatively small datasets. As concerns
, it may outperform
when the dataset is relatively small. See [
41,
42,
43] and references inside. As the dataset considered in this paper is relatively small, we decide to take these three solvers as candidates.
We propose for the first time in this paper a binary version to design the sensor system, which favors the 0 value.
3.1. Novel Adaptive and Chaotic Expression of a
In this work, we combine the expression proposed in [
13] and the expression proposed in [
29], which yield an adaptive and chaotic version of
a:
where
is a value taken from a chaotic sequence as in [
29], and
is defined as follows:
with
, and assuming
is even.
3.2. Novel Binary GWO Favoring 0 Values
In the considered co-design problem, we face a constraint: the method that is meant to select the sensors which are switched on or off should favor the sensor switch off. That is why the proposed novel Binary GWO still explores a binary search space but favors 0 values.
3.2.1. Contribution of a Leader
As explained previously in the paper, in the case where the search space is continuous, the contribution
corresponding to any leader
l is calculated through Equation (
5). In Equation (
5), the contribution
may be smaller than 0 and larger than 1. So, we enforce clip this value in this interval:
where
is defined as in Equation (
3) and
is defined as in Equation (
4); the
consists in setting a value which is lower than 0 to 0 and a value which is larger than 1 to 1.
3.2.2. Binary Update Rule
In the considered issue of sensor selection, we wish to favor the selection of the ‘off’ state for the largest possible number of sensors. That is, we wish to favor the value 0 while updating any wolf position. In the proposed novel version of the Binary GWO, wolf q is updated from iteration to iteration as follows:
Equation (
24) is a modified version of Equation (
22), where the slope of the Sigmoid is set to a real-valued scalar
and the inflexion point of the Sigmoid is set to a real-valued scalar
.
We propose the following expressions for
and
:
and
The interest of these rules, compared to the update rules in Equation (
22), is two-fold:
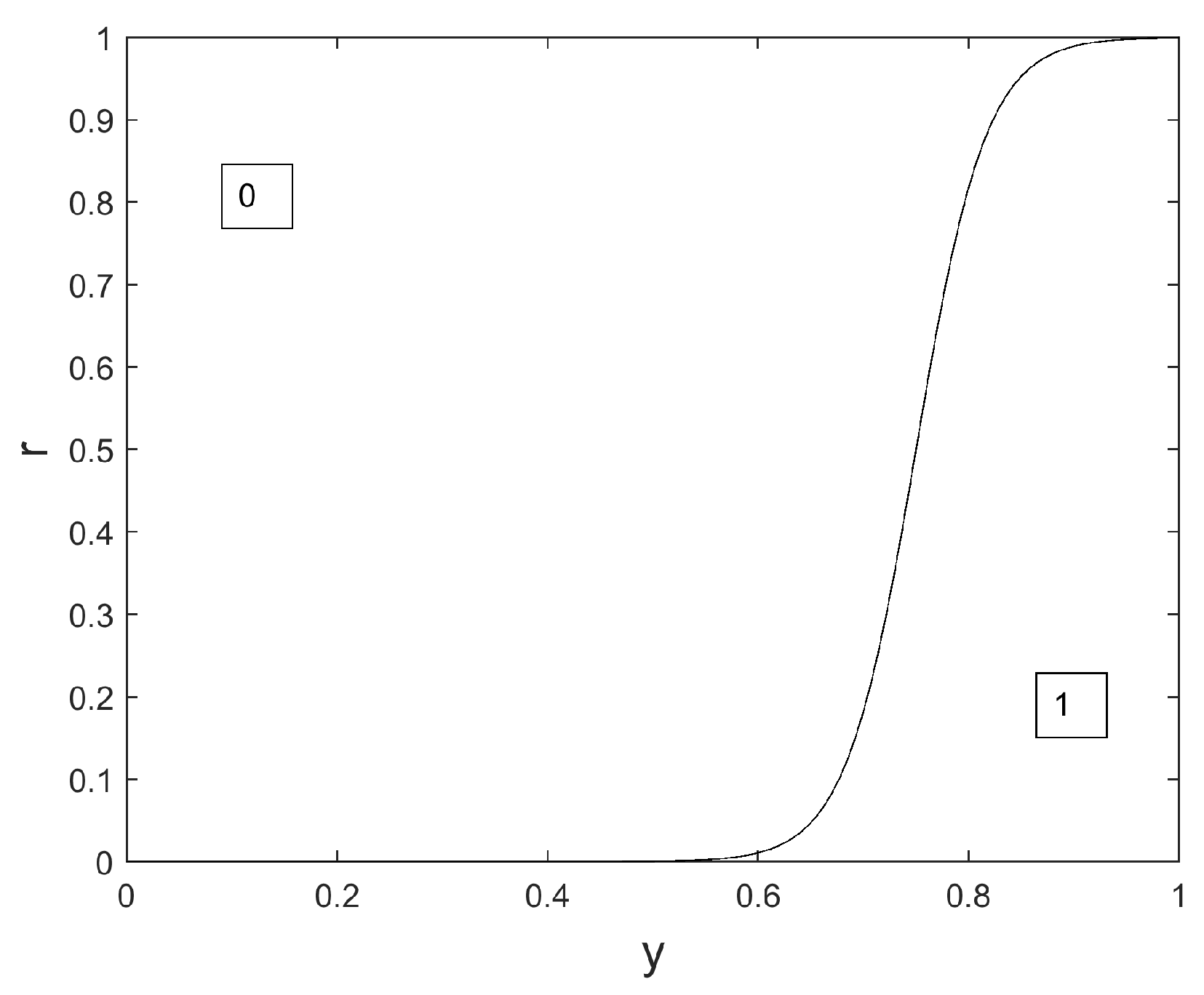
This emphasizes the exploration capacities of the method at the beginning of the algorithm, because is small at the beginning and value 0 may be chosen even for large values of y;
This permits us to favor the choice of the value 0, because .
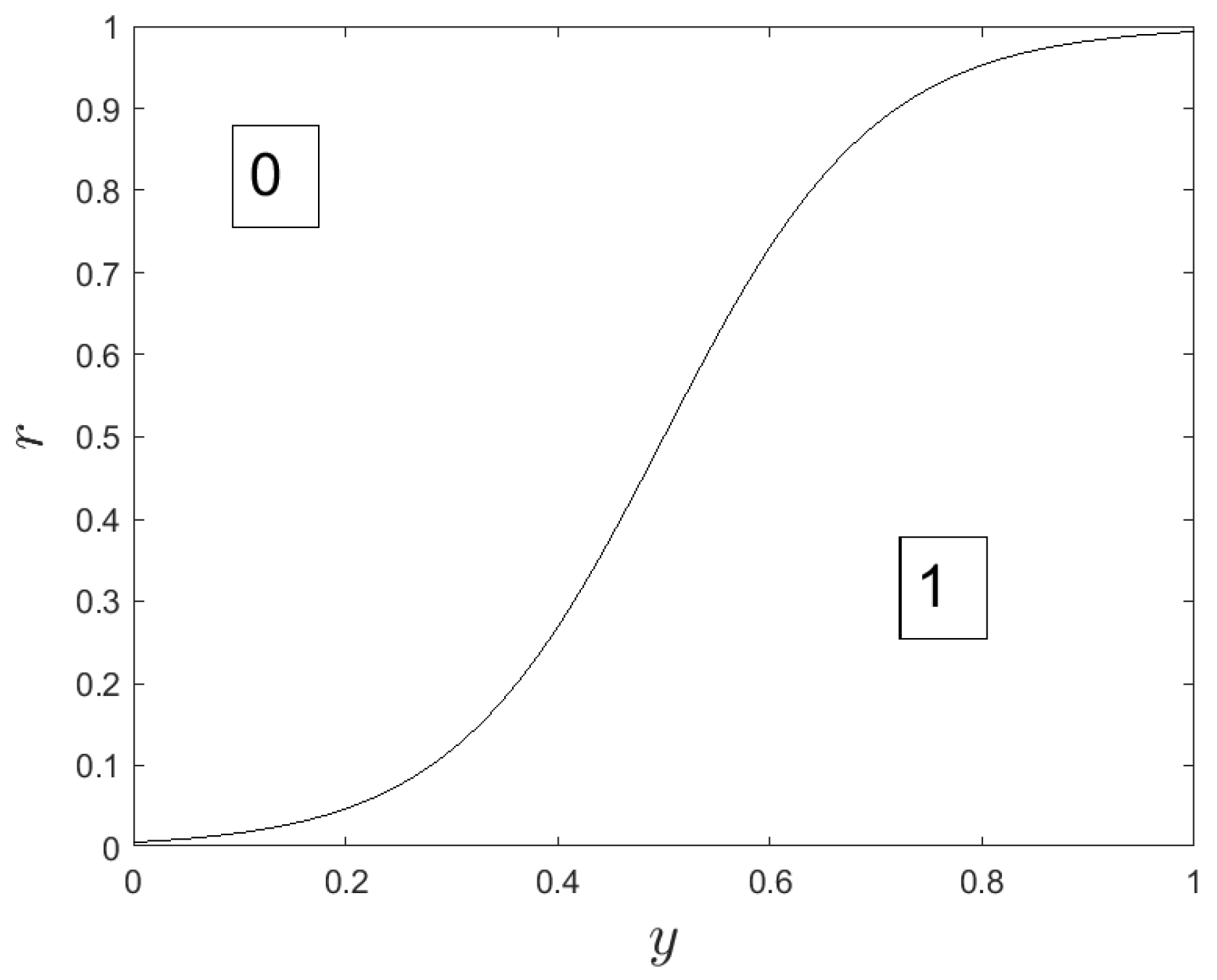
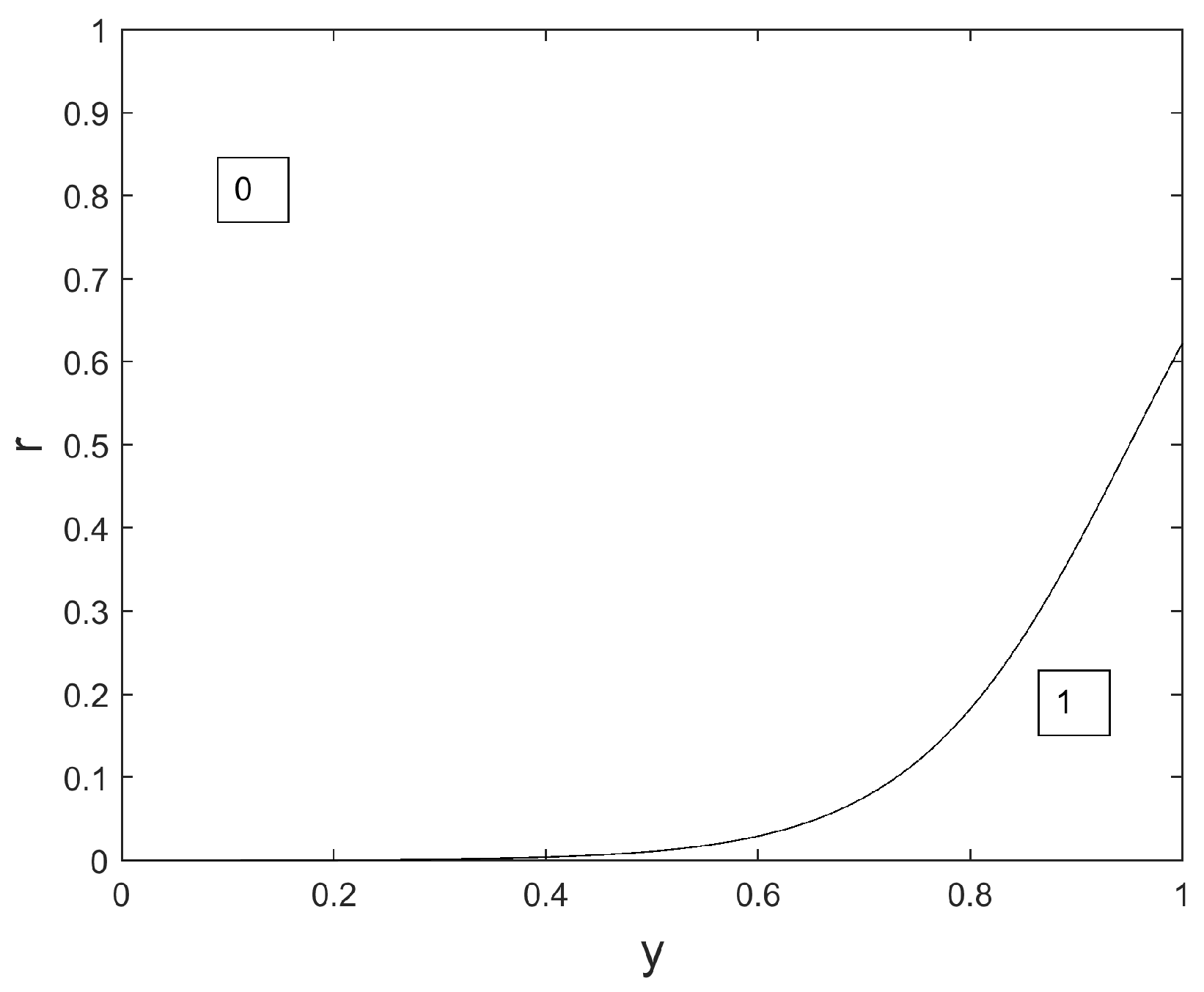
We notice in
Figure 6,
Figure 7 and
Figure 8 that the surface dedicated to 0 is increased, compared to the original Binary GWO (see
Figure 1), whatever the iteration index. Consequently, the probability to choose 0 for a given value of
is also increased whatever the iteration index. This is of great interest for our application where a large number of sensors should be switched off, and an important novelty compared to previous works such as the original Binary GWO proposed in [
31], and the Ternary GWO proposed in [
29]. Another novelty, compared to the binary versions presented in [
31,
44], is the ‘evolutive’ nature of our version of the Binary GWO: at the beginning of the optimization process, for small values of
, it is possible for the value 0 to be selected, even if the two leaders, for parameter
i, bear the value 1. See the illustration in
Figure 6. If
, the value 0 is selected with a probability of
at iteration
, with a probability of
at iteration
, with a probability almost equal to 0 at iteration
.
This evolutive nature enhances the exploration abilities of the proposed method at the beginning of the process.
3.3. Pseudo-Code CBTGWO (Algorithm 1)
We propose combining the continuous and ternary versions mentioned in
Section 2 with the proposed binary version of the GWO, which privileges the choice of value 0. A novelty with respect to the adaptive mixed GWO proposed in [
13] is the combination of three update rules instead of two, repositioning of the three worst agents at Step 4, and inserting a memory effect at Step 6: an agent is updated if the new score is better than the previous one.
| Algorithm 1: Pseudo-code: Continuous Binary Ternary Grey Wolf Optimization |
Inputs: fitness function, number of Q search agent, search space of P parameters, maximum of iteration , small factor set by the user, to stop the algorithm. Set iteration number , create an initial herd composed of Q wolves with all required parameter values , . This initial population forms of a matrix with Q rows and P columns. Evaluate fitness function value of each wolf , . Sort the wolves through their fitness value and update the , , and wolves which hold, respectively, the first, second, and third best fitness value. Store their position in vectors , , and , respectively. Reposition the three worst agents which become , , and , respectively. Repeat steps for each wolf , : For each component with : compute using: - (a)
Equation ( 24) if takes its values in a binary search space; - (b)
Equation ( 13) if takes its values in a ternary search space; - (c)
Equation ( 6) if takes its values in a continuous search space.
if < update as . Exchange the current population with the new one, obtained at step 5. If or , increase , and go to step 2.
Output: estimated parameter values |
In
Section 4, we aim, firstly, to illustrate the performances of the CBTGWO on a synthetic test function with the same number of parameters as in the considered co-design application. Secondly, we evaluate our method and comparative optimization algorithms on experimental radar data acquired from shards.
5. Discussion
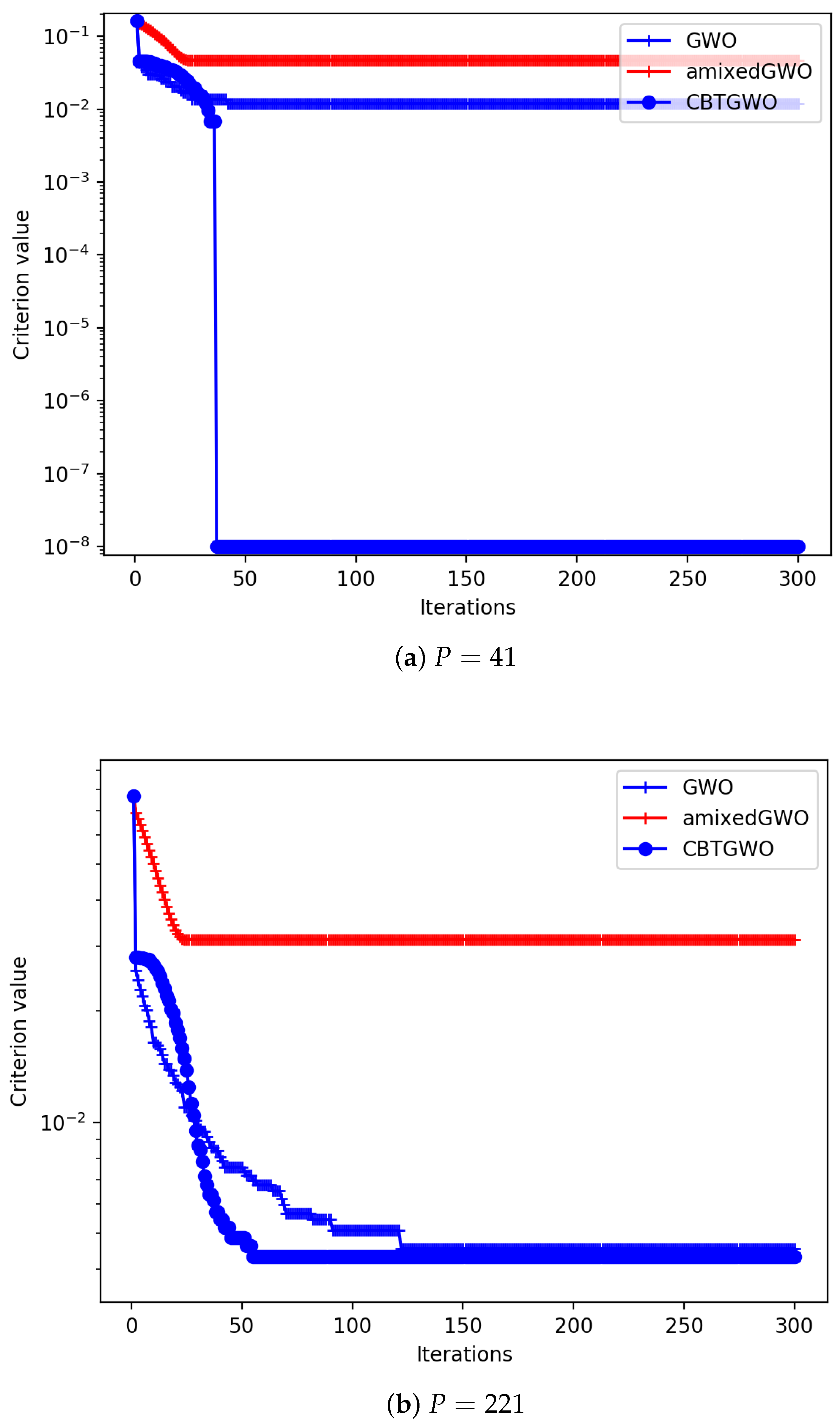
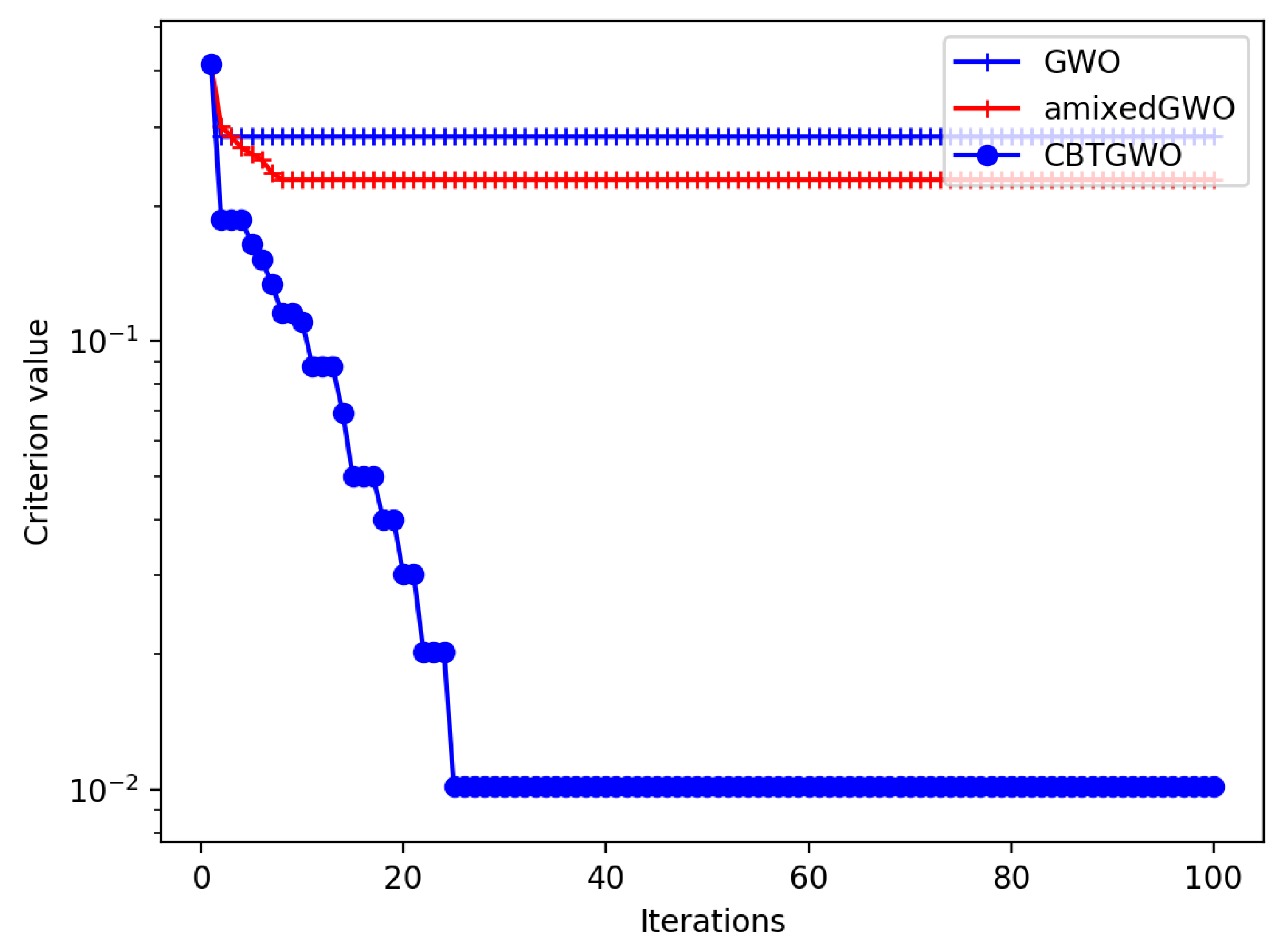
The mixed optimizer composed of the continuous GWO, the Ternary GWO, and the Binary GWO solve the considered problem of co-design of a radar system and a neural network for experimental radar data processing. Numerical simulations performed on a surrogate benchmark function show the good behavior of the proposed CBTGWO with respect to the vanilla GWO proposed in [
12] and the discrete version proposed in [
13]. We show that when 37 sensors are simulated, the exact location of the global minimum of the surrogate function is found by the proposed CBTGWO.
This justifies its use in the considered co-design problem: we optimize the number and the location of a set of sensors, and jointly tune the parameters of a multilayer perceptron to perform shard classification from millimeter-wave measurements.
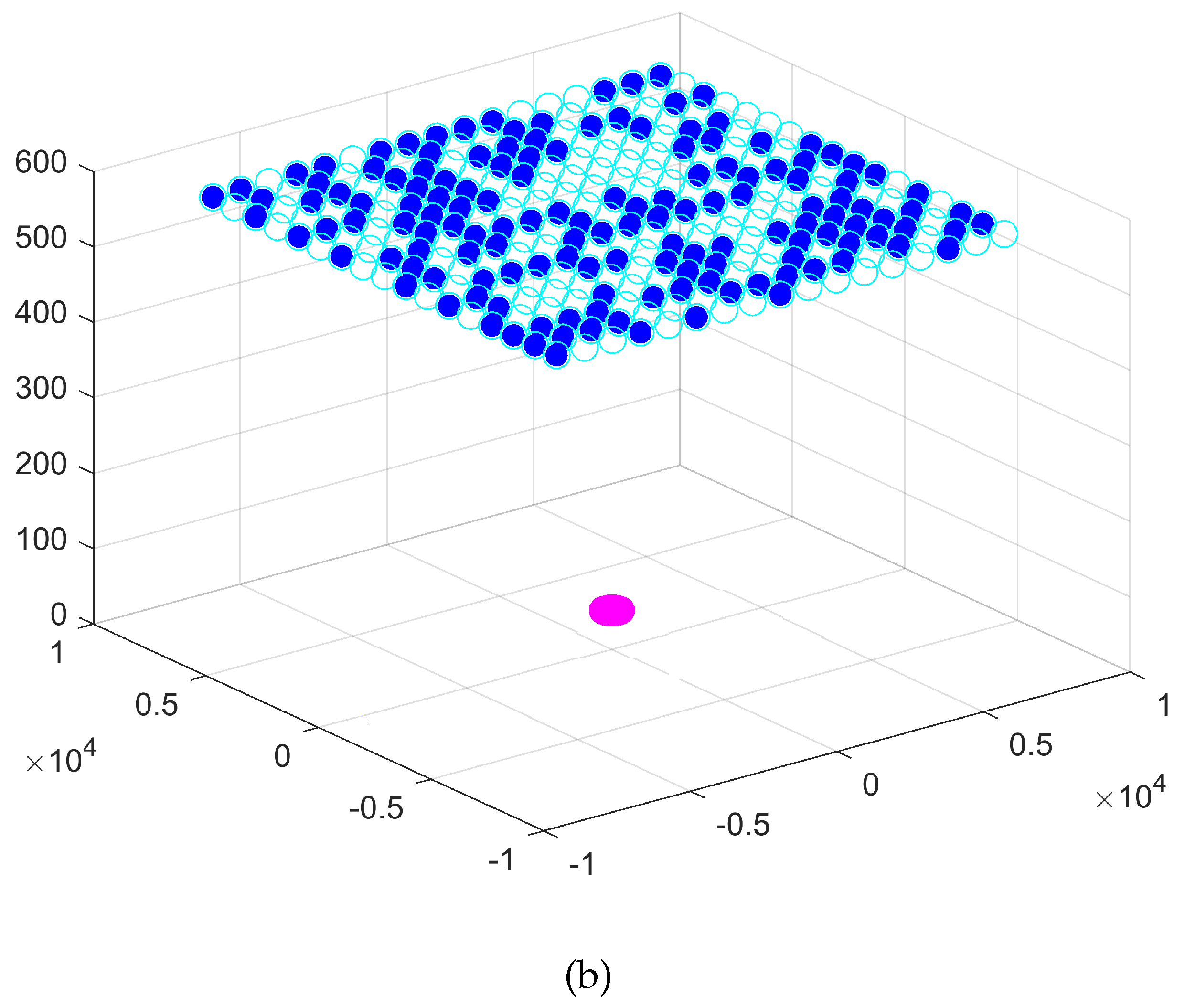
In a wide-band scenario, using the vanilla GWO and a fixed step between the sensors, we reach a 8.3% FRR on the validation base with 37 sensors; using the proposed CBTGWO, we reach a 0% FRR on the validation base with only 1 sensor. On the test database, 10 images out of 3213 are not correctly classified.
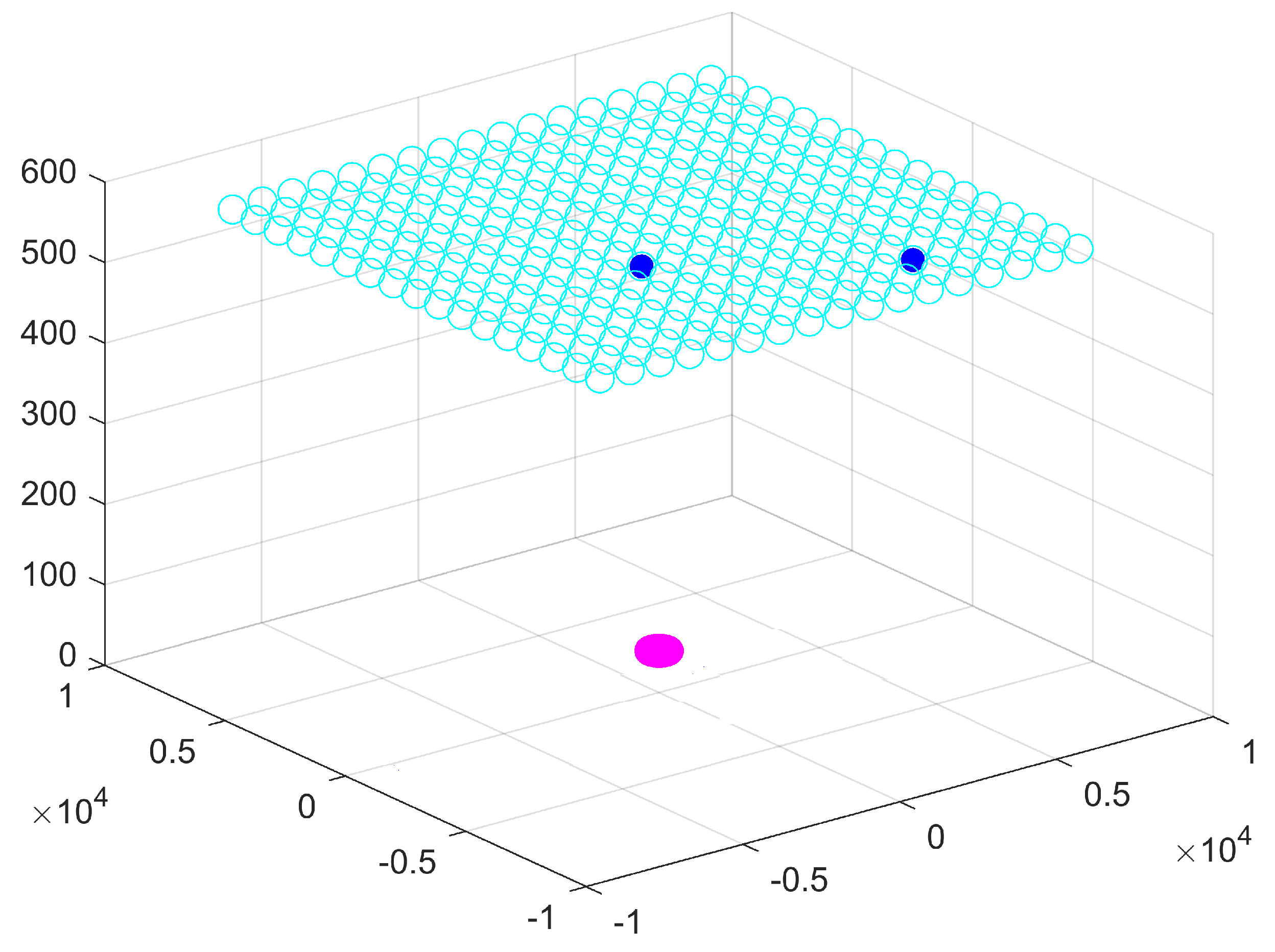
In a scenario with only one frequency, using the vanilla GWO and a fixed step between the sensors, we reach a 0% FRR on the validation base with 217 sensors; using the proposed CBTGWO we reach a 1.3% FRR on the validation base with only 2 sensors. On the test database, 11 images out of the 459 images are not correctly classified. The results obtained in the wide-band scenario point out a limitation which is inherent to the classification process: whatever the performance of the optimization method, a test database is always different from a validation database. We infer from these results that the appropriate strategy consists in finding a trade-off between the FRR value obtained on the validation database and the number of sensors, instead of aiming at the least possible FRR value on the validation database.
6. Conclusions
The contributions of this paper are three-fold. Firstly, we set a problem of radar system design, in which the number of sensors which are turned on should be minimized, and a false recognition rate should also be as small as possible. Secondly, we propose a novel binary version of the Grey Wolf Optimizer, which favors the choice of the value 0 and sensor switch off; this Binary GWO, combined with the Ternary Grey Wolf Optimizer and the continuous GWO, yield the CBTGWO. Thirdly, we apply our CBTGWO to perform the co-design of a radar acquisition system, jointly with the classification neural network. We thereby solve a major issue in the radar community, which is the selection of the least and most relevant sensors for a given application. In a wide-band scenario, the proposed method manages to select only one sensor while yielding a zero-valued FRR. In a scenario with only one frequency, three sensors are selected and placed in a manner that preserves the spatial diversity. Future research could consider other classification issues, on data acquired in a different manner. The proposed methodology could be used to design other sensor architectures (in different wavelength domains, for instance), and other neural networks including, for instance, convolutional layers.

 ,
, 
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}